







在线爬虫是大快大数据一体化开发框架的重要组成部分,本篇重点分享在线爬虫的安装。 爬虫安装前准备工作:大快大数据平台安装完成、zookeeper、redis、elasticsearch、mysql等组件安装启动成功。
1、修改爬虫安装配置文件(最好在线下修改好后再上传平台)
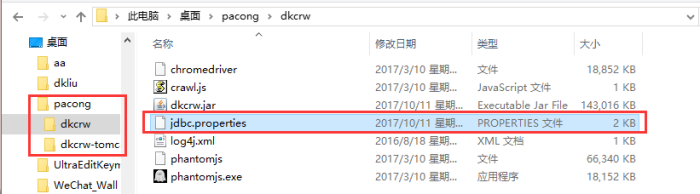
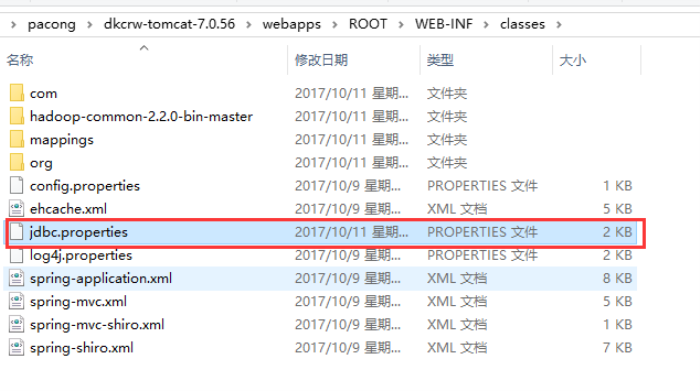
2、修改crawler\dkcrw\jdbc.properties配置文件(只修改图片里的内容其他内容默认即可)
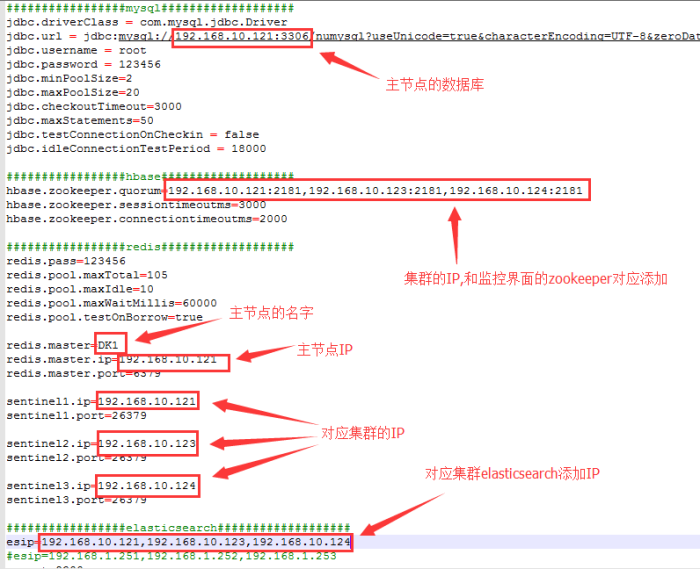
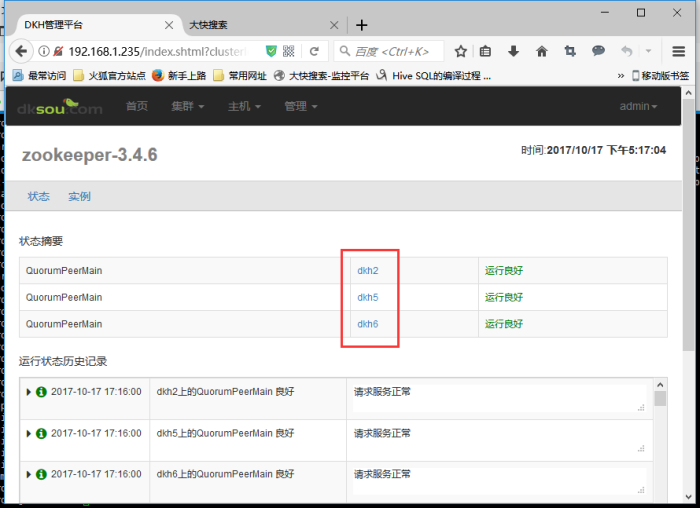
Hbase.zookeeper.quorum所填地址应在DKM监控平台查看:
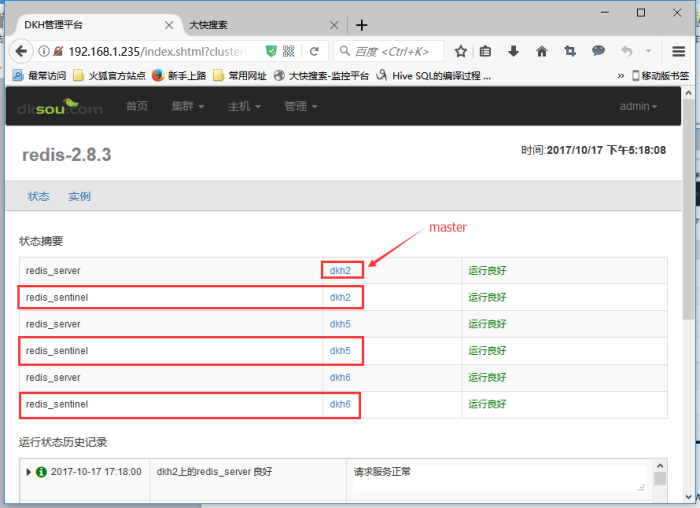
Redis相关配置看如下界面:
3、把已修改的crawler\dkcrw\下的jdbc.properties配置文件替换到\crawler\dkcrw-tomcat-7.0.56\webapps\ROOT\WEB-INF\classes下(这下面有一个没有改好的直接替换)
修改好后把修改好的爬虫文件打压成压缩文件
4、上传平台主节点并解压(这里就不介绍怎么上传了的了,本次例子是上传到root目录下,安装包上传到任何目录下都可以推选root目录)

unzip 解压命令,解压唱功后会多了一个 cuawler 的文件夹

使用cd crawler 命令进入 crawler 文件夹下

使用mysql -uroot -p123456 < numysql.sql 命令添加numysql.sql数据库

5、分发爬虫文件

每个节点都需要有dkcrw文件, dkcrw-tomcat-7.0.56文件只能放在一个节点上,不能放在主节点上(推选放在从节点) 命令: scp -r {要分发的文件名可填写多个,如果不在要分发文件的目录下请添加路径} {分发到的服务器ip或名称:分发到的路径} 例如: cd /opt/dkh scp -r dkcrw dk2:/opt/dkh/ scp -r dkcrw dkcrw-tomcat-7.0.56/ dk2:/opt/dkh/

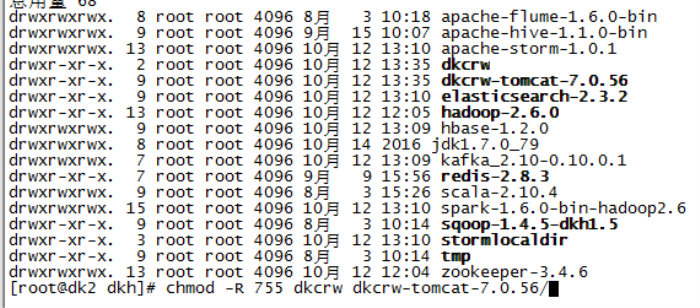
6、在分发了dkcrw-tomcat-7.0.56文件的节点上给文件添加权限 命令: chmod -R 755 {需要给权限的文件等} 例如: cd /opt/dkh chmod -R 755 dkcrw dkcrw-tomcat-7.0.56/
7、启动爬虫界面 命令: cd /opt/dkh/dkcrw-tomcat-7.0.56/bin/ ./startup.sh

启动界面之后再浏览器中输入启动界面节点的IP,来打开爬虫界面看是否启动成功(账号密码是默认的)

8、启动每个节点的dkcrw.jar 命令: 主节点运行 cd /opt/dkh/dkcrw/ nohup java -jar dkcrw.jar master > dkcrw.log 2>&1 &
从节点运行 cd /opt/dkh/dkcrw/ nohup java -jar dkcrw.jar slave > dkcrw.log 2>&1 &
注意:可以先使用前台启动爬虫,确定爬虫没错误。 前台启动命令java -jar dkcrw.jar master/slave














 80万+
80万+










 暂无认证
暂无认证







 到【灌水乐园】发言
到【灌水乐园】发言










weixin_45186442: 大量收苹果id
L·J.J: 有出苹果id么
karnooL: 可以批量注册吗
王腾: 资源404了
lllugmk: 这个是外国的软件吗,数据存储安全吗