什么是网络爬虫?有什么用?怎么爬?终于有人讲明白了

 已于 2022-02-11 16:00:17 修改
已于 2022-02-11 16:00:17 修改
 阅读量3.4w
阅读量3.4w
 收藏
74
收藏
74


 点赞数
17
点赞数
17

【导读】网络爬虫也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。
此时,我们可以使用网络爬虫对数据信息进行自动采集,比如应用于搜索引擎中对站点进行爬取收录,应用于数据分析与挖掘中对数据进行采集,应用于金融分析中对金融数据进行采集,除此之外,还可以将网络爬虫应用于舆情监测与分析、目标客户数据的收集等各个领域。
当然,要学习网络爬虫开发,首先需要认识网络爬虫,本文将带领大家一起认识几种典型的网络爬虫,并了解网络爬虫的各项常见功能。

一、什么是网络爬虫
随着大数据时代的来临,网络爬虫在互联网中的地位将越来越重要。互联网中的数据是海量的,如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。
我们感兴趣的信息分为不同的类型:如果只是做搜索引擎,那么感兴趣的信息就是互联网中尽可能多的高质量网页;如果要获取某一垂直领域的数据或者有明确的检索需求,那么感兴趣的信息就是根据我们的检索和需求所定位的这些信息,此时,需要过滤掉一些无用信息。前者我们称为通用网络爬虫,后者我们称为聚焦网络爬虫。
1. 初识网络爬虫
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每天会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又如何筛选这些重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差异。
所以,我们在研究爬虫的时候,不仅要了解爬虫如何实现,还需要知道一些常见爬虫的算法,如果有必要,我们还需要自己去制定相应的算法,在此,我们仅需要对爬虫的概念有一个基本的了解。
除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。
如果想自己实现一款小型的搜索引擎,我们也可以编写出自己的爬虫去实现,当然,虽然可能在性能或者算法上比不上主流的搜索引擎,但是个性化的程度会非常高,并且也有利于我们更深层次地理解搜索引擎内部的工作原理。
大数据时代也离不开爬虫,比如在进行大数据分析或数据挖掘时,我们可以去一些比较大型的官方站点下载数据源。但这些数据源比较有限,那么如何才能获取更多更高质量的数据源呢?此时,我们可以编写自己的爬虫程序,从互联网中进行数据信息的获取。所以在未来,爬虫的地位会越来越重要。

2. 为什么要学网络爬虫
我们初步认识了网络爬虫,但是为什么要学习网络爬虫呢?要知道,只有清晰地知道我们的学习目的,才能够更好地学习这一项知识,我们将会为大家分析一下学习网络爬虫的原因。
当然,不同的人学习爬虫,可能目的有所不同,在此,我们总结了4种常见的学习爬虫的原因。
1)学习爬虫,可以私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理进行更深层次地理解。
有的朋友希望能够深层次地了解搜索引擎的爬虫工作原理,或者希望自己能够开发出一款私人搜索引擎,那么此时,学习爬虫是非常有必要的。
简单来说,我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。
当然,信息怎么爬取、怎么存储、怎么进行分词、怎么进行相关性计算等,都是需要我们进行设计的,爬虫技术主要解决信息爬取的问题。
2)大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集,去掉很多无关数据。
在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得, 也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。
此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而进行更深层次的数据分析,并获得更多有价值的信息。

3)对于很多SEO从业者来说,学习爬虫,可以更深层次地理解搜索引擎爬虫的工作原理,从而可以更好地进行搜索引擎优化。
既然是搜索引擎优化,那么就必须要对搜索引擎的工作原理非常清楚,同时也需要掌握搜索引擎爬虫的工作原理,这样在进行搜索引擎优化时,才能知己知彼,百战不殆。
4)从就业的角度来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高,所以,深层次地掌握这门技术,对于就业来说,是非常有利的。
有些朋友学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能够胜任这方面岗位的人员较少,所以属于一个比较紧缺的职业方向,并且随着大数据时代的来临,爬虫技术的应用将越来越广泛,在未来会拥有很好的发展空间。
除了以上为大家总结的4种常见的学习爬虫的原因外,可能你还有一些其他学习爬虫的原因,总之,不管是什么原因,理清自己学习的目的,就可以更好地去研究一门知识技术,并坚持下来。
3. 网络爬虫的组成
接下来,我们将介绍网络爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库构成。
图1-1所示是网络爬虫的控制节点和爬虫节点的结构关系。

图1-1 网络爬虫的控制节点和爬虫节点的结构关系
可以看到,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以互相通信,同时,控制节点和其下的各爬虫节点之间也可以进行互相通信,属于同一个控制节点下的各爬虫节点间,亦可以互相通信。
控制节点,也叫作爬虫的中央控制器,主要负责根据URL地址分配线程,并调用爬虫节点进行具体的爬行。
爬虫节点会按照相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果存储到对应的资源库中。
4. 网络爬虫的类型
现在我们已经基本了解了网络爬虫的组成,那么网络爬虫具体有哪些类型呢?
网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。在实际的网络爬虫中,通常是这几类爬虫的组合体。
4.1 通用网络爬虫
首先我们为大家介绍通用网络爬虫(General Purpose Web Crawler)。通用网络爬虫又叫作全网爬虫,顾名思义,通用网络爬虫爬取的目标资源在全互联网中。
通用网络爬虫所爬取的目标数据是巨大的,并且爬行的范围也是非常大的,正是由于其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是非常高的。这种网络爬虫主要应用于大型搜索引擎中,有非常高的应用价值。
通用网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。通用网络爬虫在爬行的时候会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
4.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网络爬虫,顾名思义,聚焦网络爬虫是按照预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网络爬虫不像通用网络爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节省爬虫爬取时所需的带宽资源和服务器资源。
聚焦网络爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后根据链接和内容的重要性,可以确定哪些页面优先访问。
聚焦网络爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于增强学习的爬行策略和基于语境图的爬行策略。关于聚焦网络爬虫具体的爬行策略,我们将在下文中进行详细分析。

4.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。
增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新,所以增量式网络爬虫,在爬取网页的时候,只爬取内容发生变化的网页或者新产生的网页,对于未发生内容变化的网页,则不会爬取。
增量式网络爬虫在一定程度上能够保证所爬取的页面,尽可能是新页面。
4.4 深层网络爬虫
深层网络爬虫(Deep Web Crawler),可以爬取互联网中的深层页面,在此我们首先需要了解深层页面的概念。
在互联网中,网页按存在方式分类,可以分为表层页面和深层页面。所谓的表层页面,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层页面则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的关键词之后才能够获取得到的页面。
在互联网中,深层页面的数量往往比表层页面的数量要多很多,故而,我们需要想办法爬取深层页面。
爬取深层页面,需要想办法自动填写好对应表单,所以,深层网络爬虫最重要的部分即为表单填写部分。
深层网络爬虫主要由URL列表、LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分构成。
深层网络爬虫表单的填写有两种类型:
第一种是基于领域知识的表单填写,简单来说就是建立一个填写表单的关键词库,在需要填写的时候,根据语义分析选择对应的关键词进行填写;
第二种是基于网页结构分析的表单填写,简单来说,这种填写方式一般是领域知识有限的情况下使用,这种方式会根据网页结构进行分析,并自动地进行表单填写。
以上,为大家介绍了网络爬虫中常见的几种类型,希望读者能够对网络爬虫的分类有一个基本的了解。
5. 爬虫扩展——聚焦爬虫
由于聚焦爬虫可以按对应的主题有目的地进行爬取,并且可以节省大量的服务器资源和带宽资源,具有很强的实用性,所以在此,我们将对聚焦爬虫进行详细讲解。图1-2所示为聚焦爬虫运行的流程,熟悉该流程后,我们可以更清晰地知道聚焦爬虫的工作原理和过程。
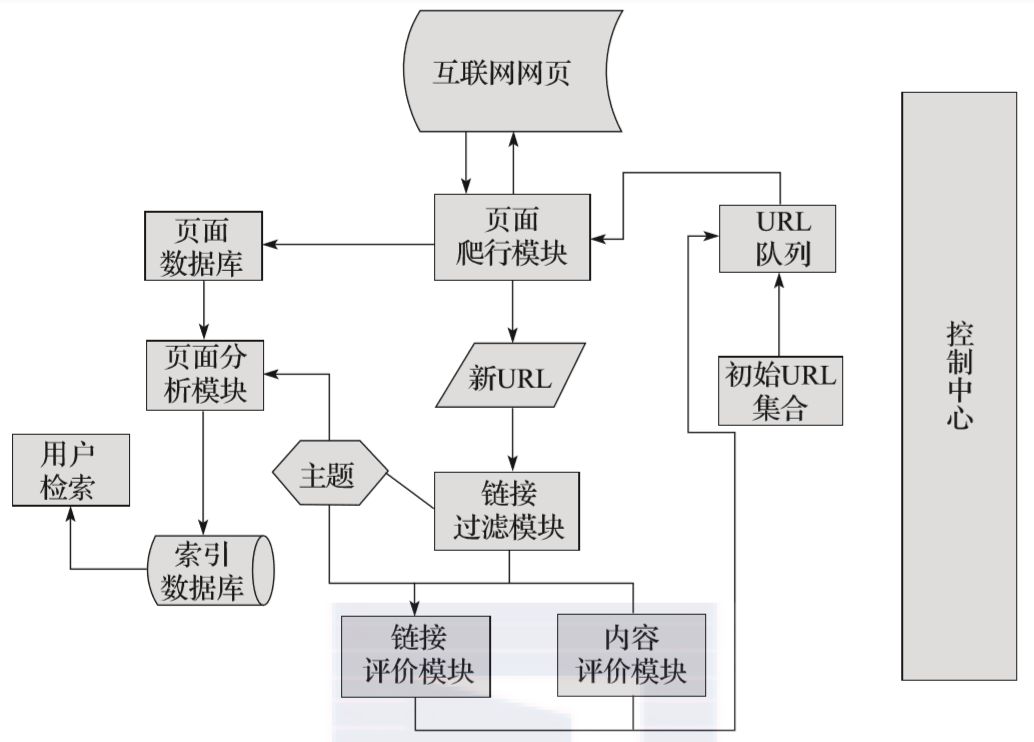
图1-2 聚焦爬虫运行的流程
首先,聚焦爬虫拥有一个控制中心,该控制中心负责对整个爬虫系统进行管理和监控,主要包括控制用户交互、初始化爬行器、确定主题、协调各模块之间的工作、控制爬行过程等方面。
然后,将初始的URL集合传递给URL队列,页面爬行模块会从URL队列中读取第一批URL列表,然后根据这些URL地址从互联网中进行相应的页面爬取。
爬取后,将爬取到的内容传到页面数据库中存储,同时,在爬行过程中,会爬取到一些新的URL,此时,需要根据我们所定的主题使用链接过滤模块过滤掉无关链接,再将剩下来的URL链接根据主题使用链接评价模块或内容评价模块进行优先级的排序。完成后,将新的URL地址传递到URL队列中,供页面爬行模块使用。
另一方面,将页面爬取并存放到页面数据库后,需要根据主题使用页面分析模块对爬取到的页面进行页面分析处理,并根据处理结果建立索引数据库,用户检索对应信息时,可以从索引数据库中进行相应的检索,并得到对应的结果。
这就是聚焦爬虫的主要工作流程,了解聚焦爬虫的主要工作流程有助于我们编写聚焦爬虫,使编写的思路更加清晰。
二、网络爬虫技能总览
在上文中,我们已经初步认识了网络爬虫,那么网络爬虫具体能做些什么呢?用网络爬虫又能做哪些有趣的事呢?在本章中我们将为大家具体讲解。
1. 网络爬虫技能总览图
如图2-1所示,我们总结了网络爬虫的常用功能。

图2-1 网络爬虫技能示意图
在图2-1中可以看到,网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这些新闻网站进行浏览,比较麻烦。此时可以利用网络爬虫,将这多个新闻网站中的新闻信息爬取下来,集中进行阅读。
有时,我们在浏览网页上的信息的时候,会发现有很多广告。此时同样可以利用爬虫将对应网页上的信息爬取过来,这样就可以自动的过滤掉这些广告,方便对信息的阅读与使用。
有时,我们需要进行营销,那么如何找到目标客户以及目标客户的联系方式是一个关键问题。我们可以手动地在互联网中寻找,但是这样的效率会很低。此时,我们利用爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方式等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行分析,比如分析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时,可以利用爬虫轻松将这些数据采集到,以便进行进一步分析,而这一切爬取的操作,都是自动进行的,我们只需要编写好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现很多强大的功能。总之,爬虫的出现,可以在一定程度上代替手工访问网页,从而,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。

2. 搜索引擎核心
爬虫与搜索引擎的关系是密不可分的,既然提到了网络爬虫,就免不了提到搜索引擎,在此,我们将对搜索引擎的核心技术进行一个简单的讲解。
图2-2所示为搜索引擎的核心工作流程。首先,搜索引擎会利用爬虫模块去爬取互联网中的网页,然后将爬取到的网页存储在原始数据库中。爬虫模块主要包括控制器和爬行器,控制器主要进行爬行的控制,爬行器则负责具体的爬行任务。
然后,会对原始数据库中的数据进行索引,并存储到索引数据库中。
当用户检索信息的时候,会通过用户交互接口输入对应的信息,用户交互接口相当于搜索引擎的输入框,输入完成之后,由检索器进行分词等操作,检索器会从索引数据库中获取数据进行相应的检索处理。
用户输入对应信息的同时,会将用户的行为存储到用户日志数据库中,比如用户的IP地址、用户所输入的关键词等等。随后,用户日志数据库中的数据会交由日志分析器进行处理。日志分析器会根据大量的用户数据去调整原始数据库和索引数据库,改变排名结果或进行其他操作。

图2-2 搜索引擎的核心工作流程
以上就是搜索引擎核心工作流程的简要概述,可能大家对索引和检索的概念还不太能区分,在此我为大家详细讲一下。
简单来说,检索是一种行为,而索引是一种属性。比如一家超市,里面有大量的商品,为了能够快速地找到这些商品,我们会将这些商品进行分组,比如有日常用品类商品、饮料类商品、服装类商品等组别,此时,这些商品的组名我们称之为索引,索引由索引器控制。
如果,有一个用户想要找到某一个商品,那么需要在超市的大量商品中寻找,这个过程,我们称之为检索。如果有一个好的索引,则可以提高检索的效率;若没有索引,则检索的效率会很低。
比如,一个超市里面的商品如果没有进行分类,那么用户要在海量的商品中寻找某一种商品,则会比较费力。
3. 用户爬虫的那些事儿
用户爬虫是网络爬虫中的一种类型。所谓用户爬虫,指的是专门用来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的利用价值也相对较高。
利用用户爬虫可以做大量的事情,接下来我们一起来看一下利用用户爬虫所做的一些有趣的事情吧。
2015年,有知乎网友对知乎的用户数据进行了爬取,然后进行对应的数据分析,便得到了知乎上大量的潜在数据,比如:
知乎上注册用户的男女比例:男生占例多于60%。
知乎上注册用户的地区:北京的人口占据比重最大,多于30%。
知乎上注册用户从事的行业:从事互联网行业的用户占据比重最大,同样多于30%。
除此之外,只要我们细心发掘,还可以挖掘出更多的潜在数据,而要分析这些数据,则必须要获取到这些用户数据,此时,我们可以使用网络爬虫技术轻松爬取到这些有用的用户信息。
同样,在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据,比如:
QQ空间用户发说说的时间规律:晚上22点左右,平均发说说的数量是一天中最多的时候。
QQ空间用户的出生月份分布:1月份和10月份出生的用户较多。
QQ空间用户的年龄阶段分布:出生于1990年到1995年的用户相对来说较多。
QQ空间用户的性别分布:男生占比多于50%,女生占比多于30%,未填性别的占10%左右。
除了以上两个例子之外,用户爬虫还可以做很多事情,比如爬取淘宝的用户信息,可以分析淘宝用户喜欢什么商品,从而更有利于我们对商品的定位等。
由此可见,利用用户爬虫可以获得很多有趣的潜在信息,那么这些爬虫难吗?其实不难,相信你也能写出这样的爬虫。

三、小结
网络爬虫也叫作网络蜘蛛、网络蚂蚁、网络机器人等,可以自动地浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则去浏览,这些规则我们将其称为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
学习爬虫,可以:①私人订制一个搜索引擎,并且可以对搜索引擎的数据采集工作原理,进行更深层次地理解;②为大数据分析提供更多高质量的数据源;③更好地研究搜索引擎优化;④解决就业或跳槽的问题。
网络爬虫由控制节点、爬虫节点、资源库构成。
网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型。在实际的网络爬虫中,通常是这几类爬虫的组合体。
聚焦网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。
爬虫的出现,可以在一定程度上代替手工访问网页,所以,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。
检索是一种行为,而索引是一种属性。如果有一个好的索引,则可以提高检索的效率,若没有索引,则检索的效率会很低。
用户爬虫是网络爬虫的其中一种类型。所谓用户爬虫,即专门用来爬取互联网中用户数据的一种爬虫。由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的利用价值也相对较高。















 1311
1311











 暂无认证
暂无认证


















 到【灌水乐园】发言
到【灌水乐园】发言










2301_81729856: 楼主可以分享爬取到的数据吗
長ずる: sum_num = 0 for i in range(100,401): if i % 3 == 2 and i % 5 == 3: sum_num += i print(sum_num)
宽度307: 一位沙发
2401_83950345: 求出100到400之间同时满足除以3余2和除以5余3的数的和。我们用的是python。🥺🥺
2401_83950345: 作者大大,呜呜呜,我们老师留了一道题不会做,想请你帮忙可以吗🥹