大数据开发:spark core核心讲解

 最新推荐文章于 2023-03-16 09:45:09 发布
最新推荐文章于 2023-03-16 09:45:09 发布
 阅读量588
阅读量588
 收藏
2
收藏
2


 点赞数
点赞数

关于Spark框架在大数据生态当中的地位,相信不必多说大家也明白,作为大数据公认的第二代计算引擎,Spark至今仍然占据重要的市场份额,只要提到大数据,那么Spark一定是如影随形的。今天的大数据开发学习分享,我们就主要来讲讲Spark框架核心Spark Core。
Spark Core简介
Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。
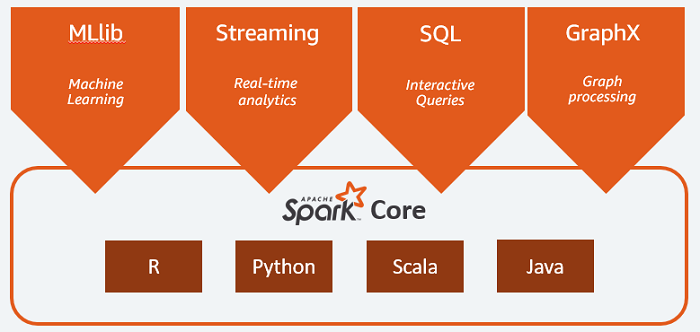
Spark本身作为一代大数据计算引擎,其核心Spark Core,正是完成计算任务的核心组件,批量的把数据加载到Spark中,然后通过它自带的一系列算子,也就是对数据的一系列操作,将数据转化,计算并最终得到自己想要的数据结果。
比如Transformation算子中的filter算子,就是对数据进行过滤,像过滤掉名字为空,电话号码为空等,都需要用到该算子。
比如Action算子中的saveAsTextFile算子,通常我们的用法就是把计算的结果保存为文本(TXT)格式。
Spark core底层
SparkCore底层是RDD,即弹性分布式分布式数据集,底层又分为多个partition(分区),它本身是不存数据的,只是计算的时候数据存在于RDD中,RDD的产生意味着调用了算子。这样一系列通过调用算子生成的RDD,最终会生成DAG有向无环图。
各个算子之间的依赖分为两种,宽依赖和窄依赖,宽依赖是子RDD的分区依赖于多个父RDD的分区,窄依赖则是子RDD的分区只依赖一个父RDD的分区,这样的依赖关系也就产生的血统的概念。
DAG有向无环图主要是与该Spark程序的执行流程有关。流程如下:
1.当一个Spark应用被提交时,首先需要为这个Spark Application构建基本的运行环境,即由任务节点(Driver)创建一个SparkContext;
2.SparkContext像资源管理器注册并申请运行Executor资源;
3.资源管理器为Executor分配资源并启动Executor进程,Executor运行状况将随着心跳发送到资源管理器上;
4.SparkContext根据RDD的依赖关系生成DAG有向无环图,并提交给DAGScheduler进行解析划分成Stage,并把该Stage中的task组成的Taskset发送给TaskScheduler;
5.TaskScheduler将Task发送到Executor执行,同时SparkContext将应用程序代码发放给Executor。
6.Executor将task丢入到线程池中执行,把执行结果反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
关于大数据开发,Spark Core大数据计算,以上就为大家做了简单的介绍了。Spark在大数据计算引擎当中,始终占据重要地位,而作为Spark核心的Spark Core,正是Spark学习当中的重难点。















 1238
1238










 暂无认证
暂无认证








 到【灌水乐园】发言
到【灌水乐园】发言










forest_long: 大佬这篇文章结构清晰,具有条理性可以借鉴并学习和落地,内容丰富图文并茂,认真看完收获很大,求回访🎀🎀🍒🍒
大佬在上,请收我: 专科想大数据太难了我感觉,深圳这边投简历几天都没面试机会

 而且老师说过小公司一般没真大数据这职位,不知道是不是真的
而且老师说过小公司一般没真大数据这职位,不知道是不是真的
GuoYale1998: 来自Yale的肯定
Zht_bs: 这个可以有
宇宙爆肝锦标赛冠军: 受教了!