scrapy爬虫爬取完整小说
最新推荐文章于 2024-04-23 09:39:24 发布

为谁攀登
 最新推荐文章于 2024-04-23 09:39:24 发布
最新推荐文章于 2024-04-23 09:39:24 发布
 阅读量2.1k
阅读量2.1k
 收藏
21
收藏
21
 点赞数
4
点赞数
4
最新推荐文章于 2024-04-23 09:39:24 发布
阅读量2.1k
收藏
21

 点赞数
4
点赞数
4

介绍
使用scrapy轻松构建一个可以爬取完整小说的爬虫
目录
- 介绍
- 1、创建项目
- 2、创建爬虫脚本
- 3、分析要爬取的小说
- 4、爬取并解析数据
- 5、接收并保存数据
- 6、配置修改
- 7、编写启动脚本
- 8、效果查看
1、创建项目
在test01目录下执行命令scrapy startproject xiaoshuospider,创建一个名为xiaoshuospider的爬虫
D:\3.dev\pyworkspace\scraw\test01>scrapy startproject xiaoshuospider
New Scrapy project 'xiaoshuospider', using template directory 'c:\users\flxk\appdata\local\programs\python\python36\lib\site-packages\scrapy\templates\project', created in:
D:\3.dev\pyworkspace\scraw\test01\xiaoshuospider
You can start your first spider with:
cd xiaoshuospider
scrapy genspider example example.com
目录结构如下
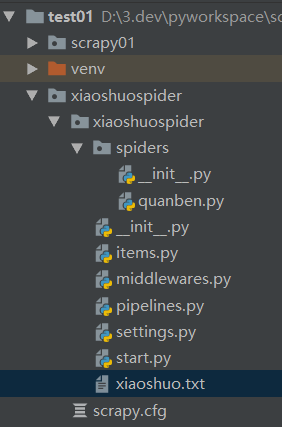
2、创建爬虫脚本
在xiaoshuospider下执行命令scrapy genspider quanben quanben.net,生成quanben.py爬虫文件
D:\3.dev\pyworkspace\scraw\test01\xiaoshuospider>scrapy genspider quanben quanben.net
Created spider 'quanben' using template 'basic' in module:
xiaoshuospider.spiders.quanben
初始内容如下
# -*- coding: utf-8 -*-
import scrapy
class QuanbenSpider(scrapy.Spider):
# 爬虫名称
name = 'quanben'
# 爬虫允许访问的域
allowed_domains = ['quanben.net']
# 初始访问地址(手动修改为自己想要的地址)
start_urls = ['https://www.quanben.net/8/8583/4296044.html']
def parse(self, response):
pass
3、分析要爬取的小说
结合xpath插件( xpath安装与使用),我们可以提取到小说的章节名称、内容和下一章节url地址

4、爬取并解析数据
在quanben.py文件中编写请求和数据解析逻辑
# -*- coding: utf-8 -*-
import scrapy
class QuanbenSpider(scrapy.Spider):
# 爬虫名称
name = 'quanben'
# 爬虫允许访问的域
allowed_domains = ['quanben.net']
# 初始访问地址(手动修改为自己想要的地址)
start_urls = ['https://www.quanben.net/8/8583/4296044.html']
def parse(self, response):
# 章节标题
title = response.xpath('//h1/text()').extract_first()
# 内容
content = response.xpath('string(//div[@id="BookText"])').extract_first().strip().replace(' ','\n')
# 下一章节地址
next_url = response.xpath('//div[@class="link xb"]/a[3]/@href').extract_first()
# 通过yield,将这个title、content传递给 pipelines.py做进一步处理
yield {
'title': title,
'content': content
}
# 通过yield,获得下一个url,并在请求完成后调用该对象的回调函数
yield scrapy.Request(response.urljoin(next_url), callback=self.parse)
5、接收并保存数据
在pipelines.py文件中编写数据持久化逻辑
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class XiaoshuospiderPipeline(object):
# 打开文件
def open_spider(self, spider):
self.filename = open('xiaoshuo.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 爬取标题
info = item['title'] + '\n'
# 爬取完整内容
# info = item['title'] + '\n' + item['content'] + '\n' + '---------------------分割线----------------------' + '\n'
# 写入文件
self.filename.write(info)
self.filename.flush()
return item
# 关闭文件
def close_spider(self, spider):
self.filename.close()
6、配置修改
在settings.py文件中的需要修改的配置信息
# 设置浏览器User-Agent请求头
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
# 是否遵循爬虫协议
ROBOTSTXT_OBEY = False
# 每隔2s请求一次
DOWNLOAD_DELAY = 2
# 开启pipelines
ITEM_PIPELINES = {
'xiaoshuospider.pipelines.XiaoshuospiderPipeline': 300,
}
7、编写启动脚本
在xiaoshuospider目录下创建start.py脚本,编写如下启动命令
from scrapy.cmdline import execute
# 启动命令
execute('scrapy crawl quanben'.split())
8、效果查看
执行脚本后,会生成xiaoshuo.txt文件保存爬取的小说内容
第一章 雪鹰领
第二章 超凡
第三章 分离
第四章 兄弟
第五章 枪法
第六章 修炼
...














 788
788










 暂无认证
暂无认证

















































 到【灌水乐园】发言
到【灌水乐园】发言










付煜铭: 代金券在哪 ?
?
隔壁de老樊: 文章不错,nice
shiyi123_: 为什么我的只能爬取第一章的 调试发现不能自动点击下一章循环 求大佬分析
wuyuer1027: 新的云都有限制了 不行了,6核以上才能绑定3个公网 10个要tmd 48核
为谁攀登: 我能用啊,你自己水平不行怪谁???