Python爬虫+selenium——爬取淘宝商品信息和数据分析
最新推荐文章于 2024-03-05 09:53:41 发布

 VIP文章
心情由心态
VIP文章
心情由心态
 最新推荐文章于 2024-03-05 09:53:41 发布
最新推荐文章于 2024-03-05 09:53:41 发布
 阅读量3.9k
阅读量3.9k
 收藏
108
收藏
108


 点赞数
6
点赞数
6
浏览器驱动
点击下载chromedrive 。将下载的浏览器驱动文件chromedriver丢到Chrome浏览器目录中的Application文件夹下,配置Chrome浏览器位置到PATH环境。
需要用到的库
selenium库,time库,re库,csv库,json库,pandas库,matplotlib库,jieba库,wordcloud库
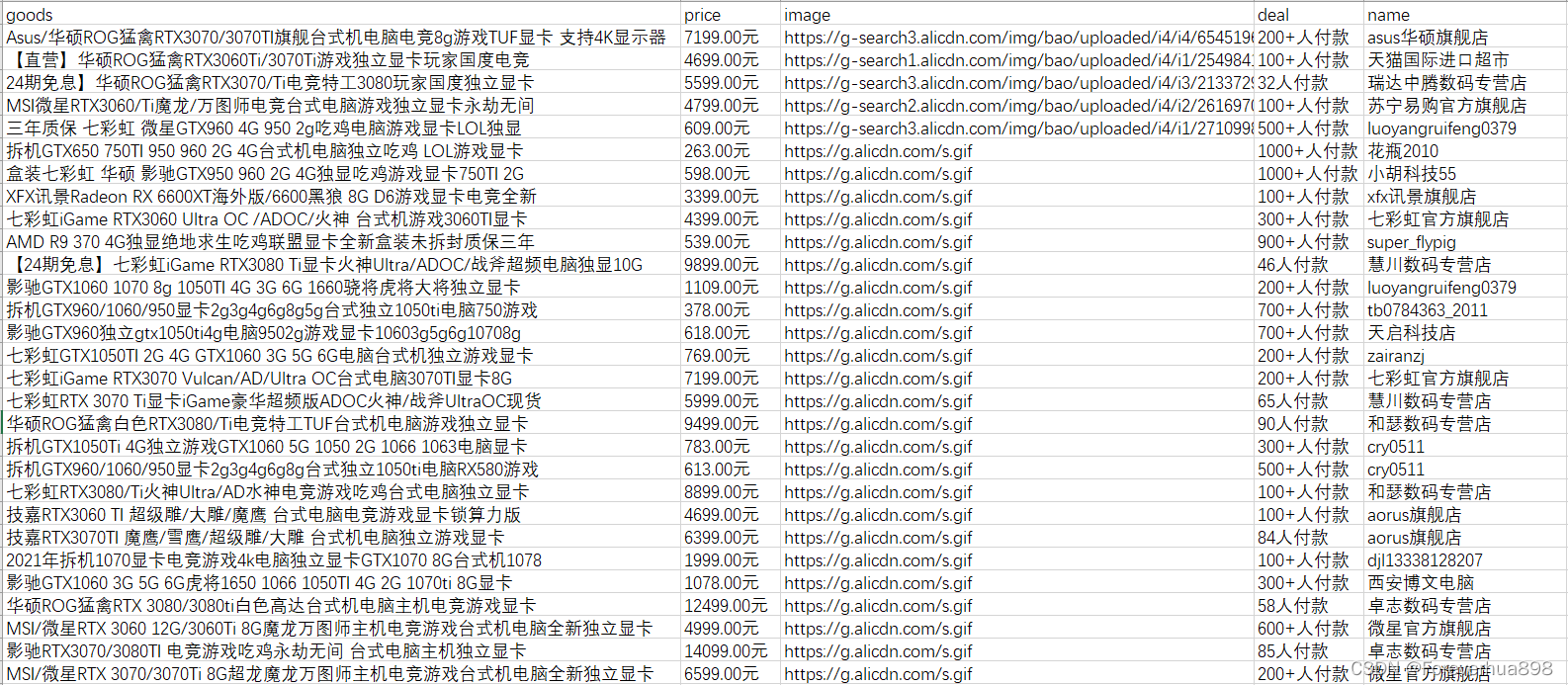
1.爬取显卡商品信息的效果图
2.相关操作与代码
先找到搜索框并用selenium模拟点击(发现需要登录,我直接扫码登录,没有写模拟登录的过程)
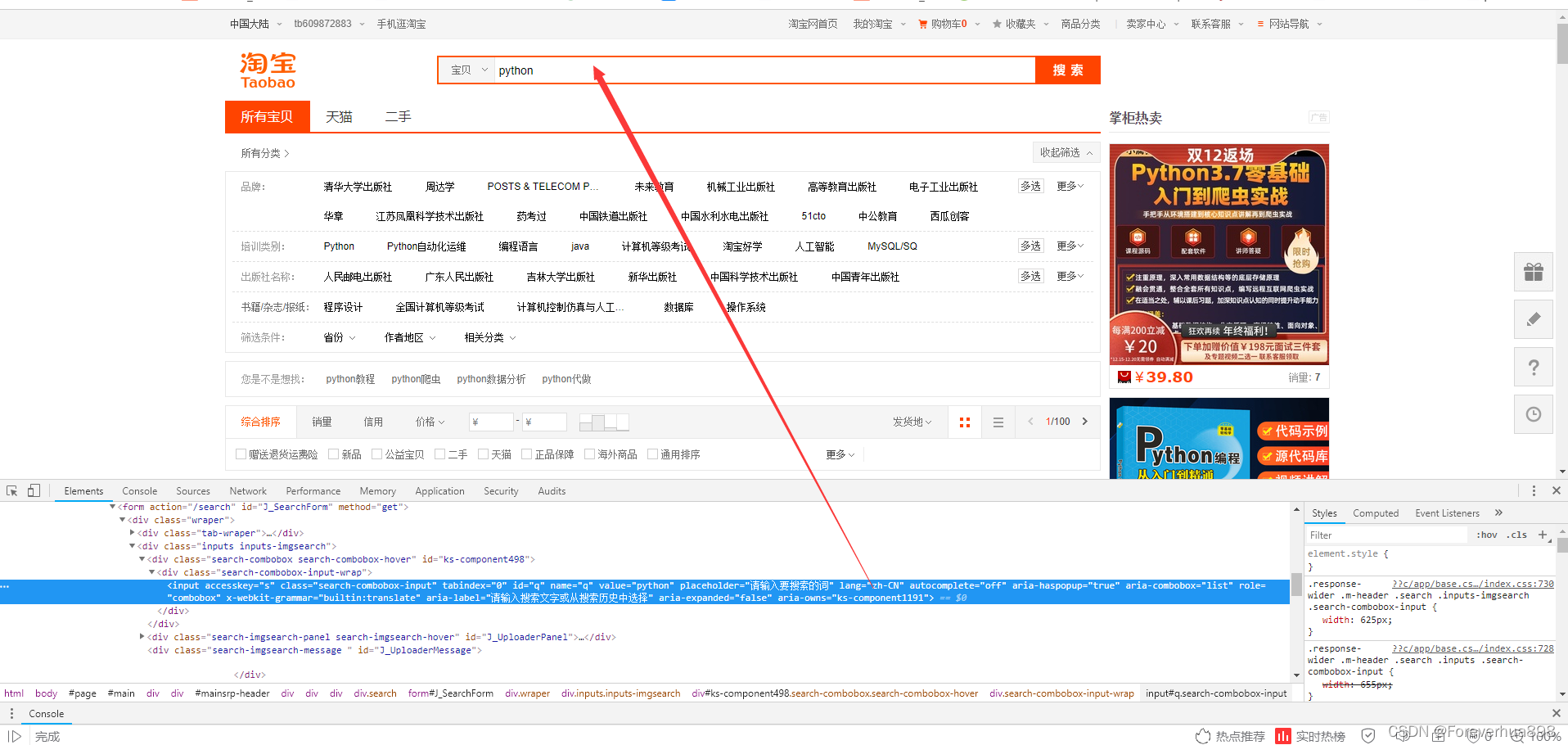
结合网页源代码,用xpath获得商品数据

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1386
1386










 暂无认证
暂无认证








 到【灌水乐园】发言
到【灌水乐园】发言










m0_63888944: 怎么转详情页
心情由心态: 不写路径,就自己保存在这个项目中,我写了2中存储文件,一种是csv存储一种是json存储,写路径需要换种写法,好久没学Python了,你上网到处搜一下嘛,有问题在来问我,多去排错,修bug,熟能生巧,你如果知道bug为什么了,你就是高手了
心情由心态: 那就是导包或者版本不兼容的问题
渴望力量的数据狗: 你好,想问一下,不知道这个保存的文件路径在哪,能指点一下吗?
weixin_42176573: 出错运行