爬虫找不到链接?
最新推荐文章于 2024-04-24 22:52:03 发布

聆听我的召唤,菜鸟进化
 最新推荐文章于 2024-04-24 22:52:03 发布
最新推荐文章于 2024-04-24 22:52:03 发布
 阅读量1.9k
阅读量1.9k
 收藏
2
收藏
2
 点赞数
点赞数
最新推荐文章于 2024-04-24 22:52:03 发布
阅读量1.9k
收藏
2

 点赞数
点赞数

一、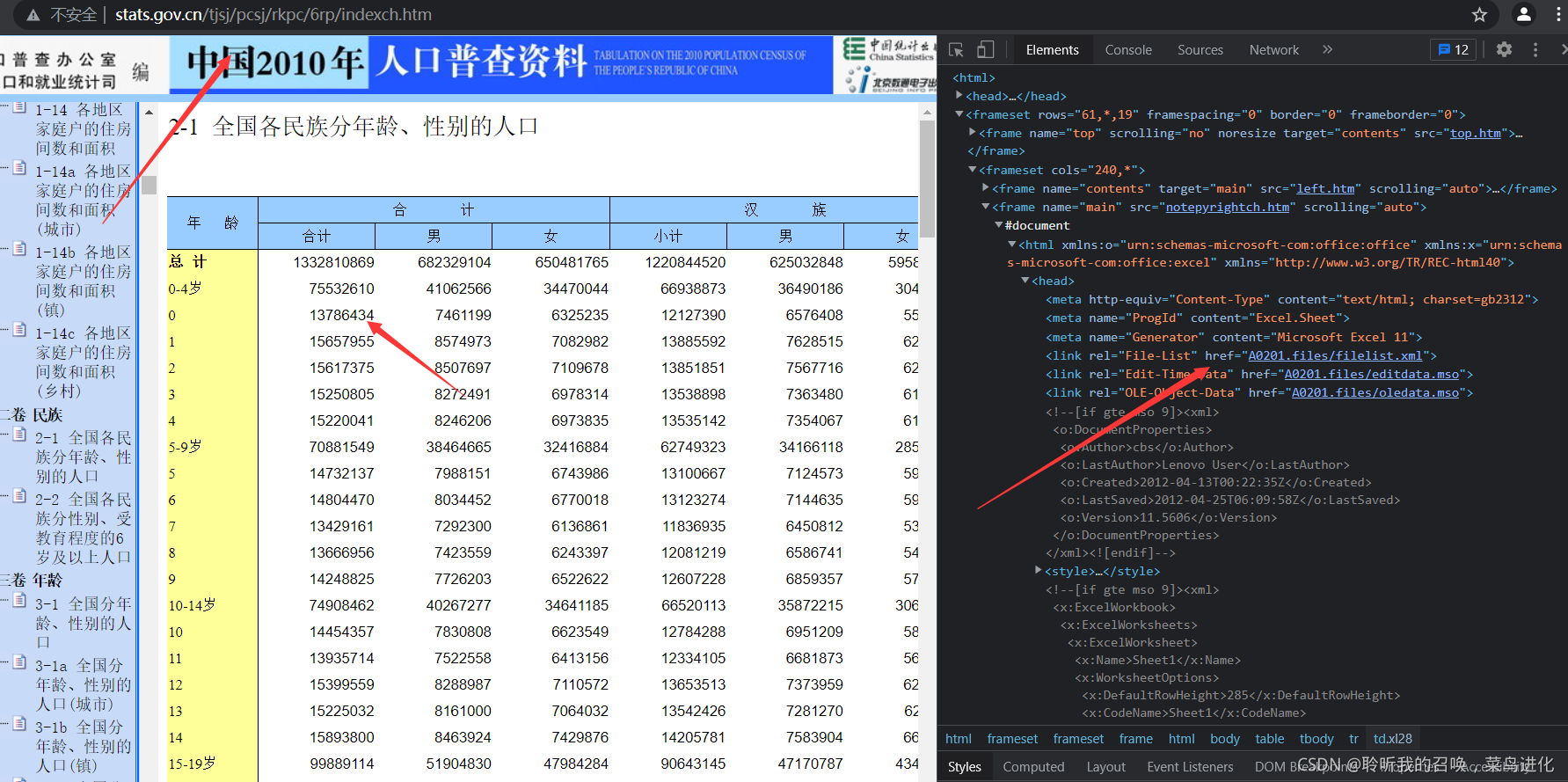
图一
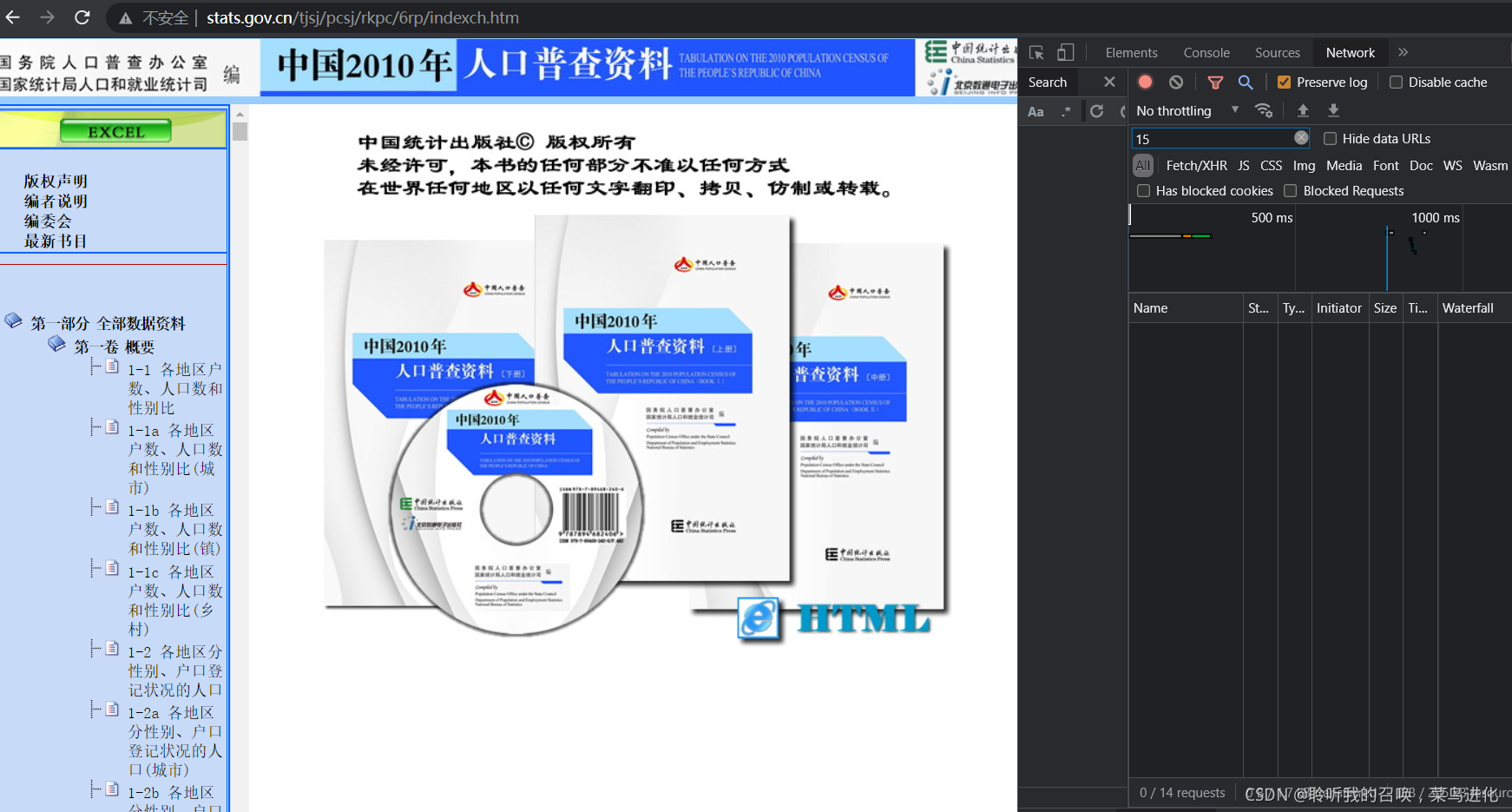
图二
如图,我想获取这个网页,但是我们在用图一的连接时,我们发现得不到链接,于是,我们进入Network打算刷新看看,结果不显示链接。
解决方案:由于这个网页的数据是放在frame里的,所以直接在frame里找链接,如图一的第三个箭头。
二、
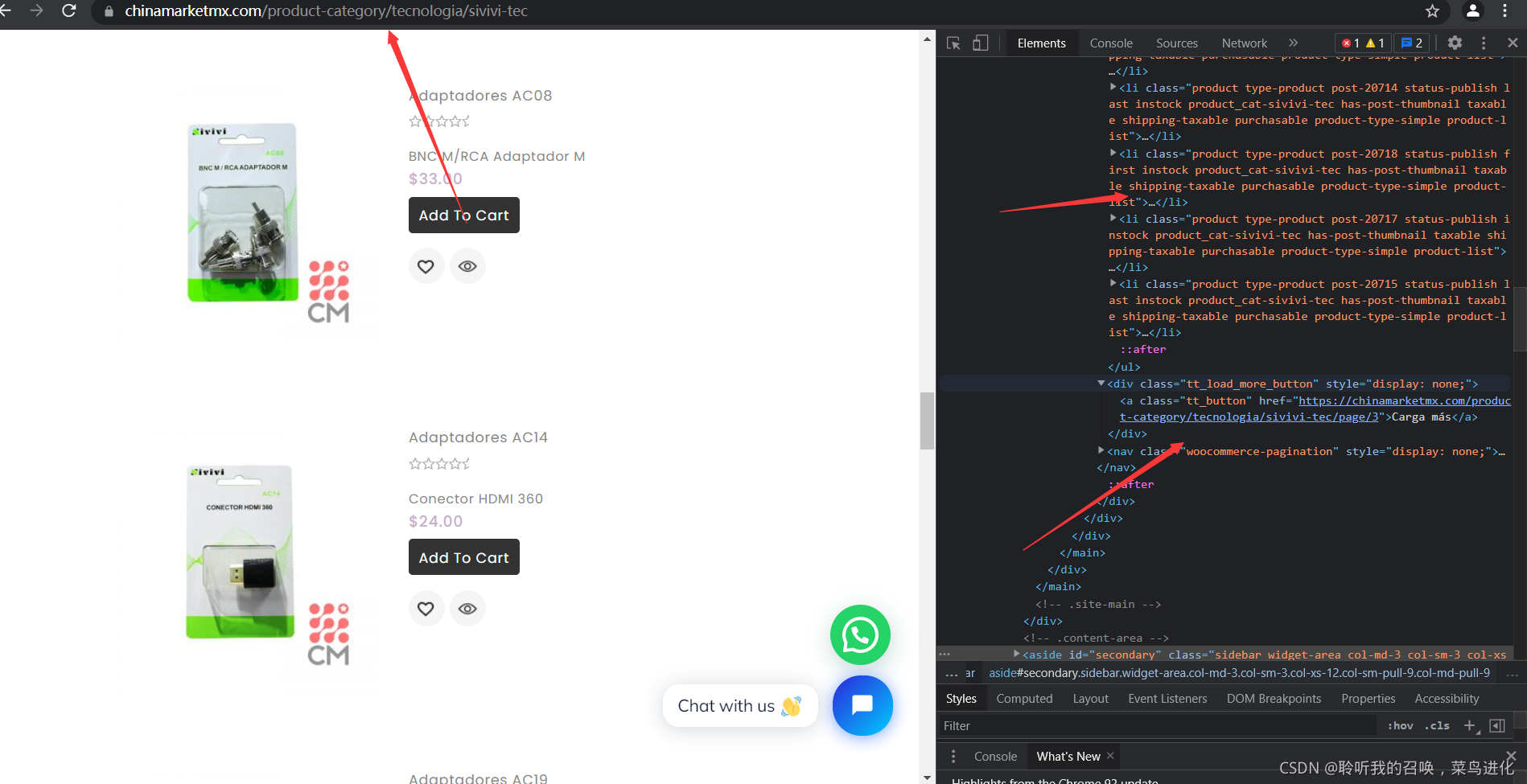
图三
如图,我们获取网站时,会遇到下拉刷新的网页,稍微做过爬虫的都是到,上面第一个红箭头肯定不能用,于是于是,我们进入Network打算刷新看看规律,但是显然没有规律怎么办,裂开。
方案,打开刷新标签,慢慢找,可能有惊喜。毕竟做反爬手段也很费事。















 2600
2600










 暂无认证
暂无认证




















 到【灌水乐园】发言
到【灌水乐园】发言












聆听我的召唤,菜鸟进化: 冰箱是并且