京东搜索产品时,pc端列表页只展示100页的数据
最新推荐文章于 2024-03-11 12:51:46 发布

梅雨琪
 最新推荐文章于 2024-03-11 12:51:46 发布
最新推荐文章于 2024-03-11 12:51:46 发布
 阅读量2k
阅读量2k
 收藏
1
收藏
1
 点赞数
3
点赞数
3
最新推荐文章于 2024-03-11 12:51:46 发布
阅读量2k
收藏
1

 点赞数
3
点赞数
3

问题描述:当你在电脑上浏览京东网站时,官网只给你返回100页数据,每页60个,总共只显示6000个商品,但实际有几十万的相关产品没有展示出来。
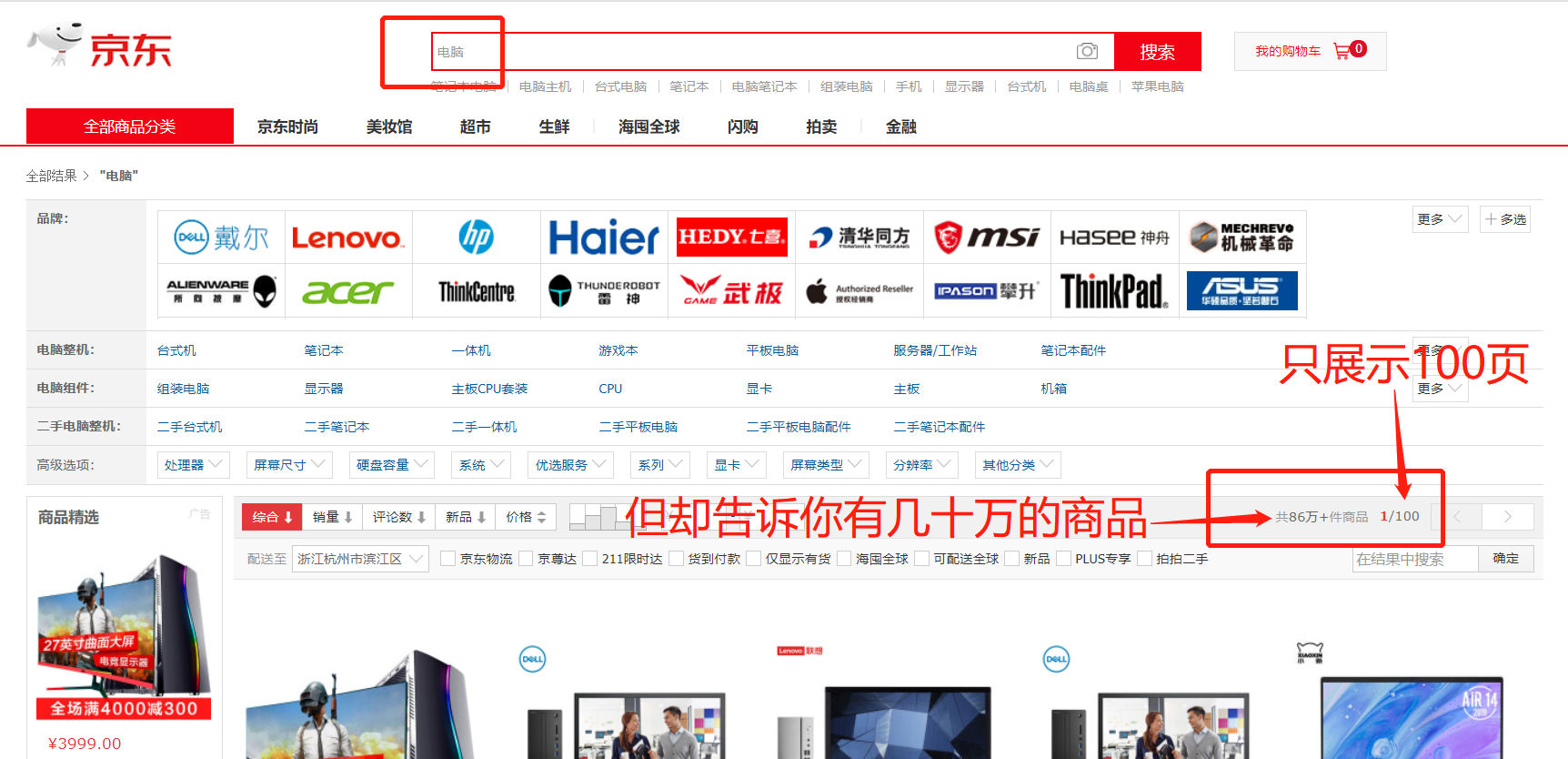
这算是京东的一种反扒机制,美团的电脑端也是这样,只给你返回固定页数的信息。遇到这个问题,可以选择增加搜索维度、寻找其他接口的方法,尽量多的去获取数据。
解决方法:
一、在搜索的时候,缩小搜索范围,增加搜索维度
- 1、在搜索商品时,加上品牌、型号等信息,缩小范围
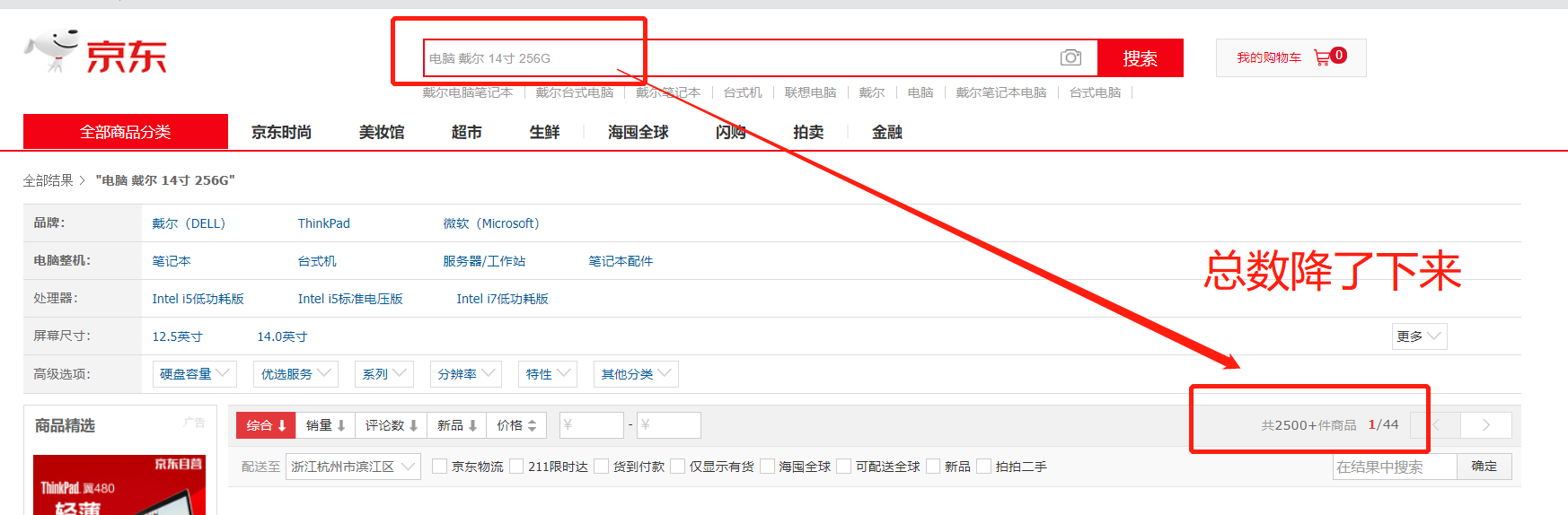
- 2、利用好京东的导航栏,进行每一层的缩小范围
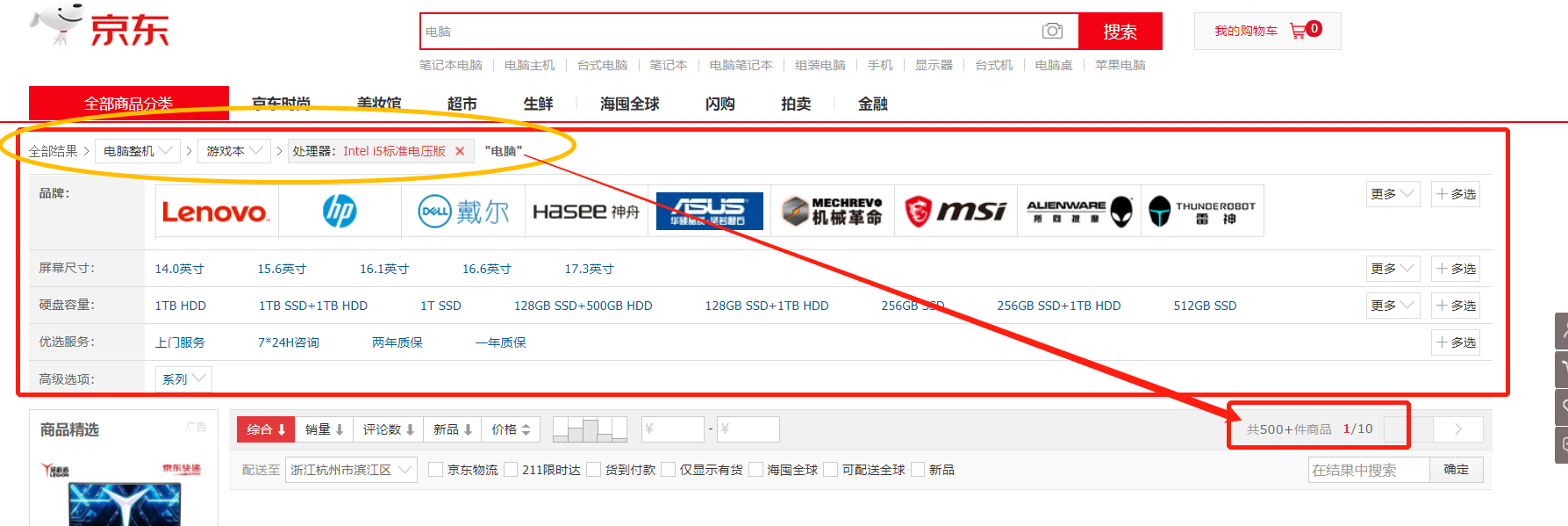
这个方法更可取一些,可以循环导航栏的信息,去一层一层的获取。
这个导航栏可以用xpath到每一个的链接。
# 提取商品页的所有相关商品
response.xpath("//div[contains(@class,'J_selectorLine')]/@class")
------------
J_selectorLine s-brand # 商品的品牌栏
J_selectorLine s-category # 商品的类别栏
J_selectorLine s-category
J_selectorLine s-line # 商品的细分条件栏
J_selectorLine s-line s-senior # 商品的选项栏
二、如果搜索固定的商品,可以找到它专属的商品页深度挖掘
- 1、利用好京东的导航栏,找到你想要抓取的信息
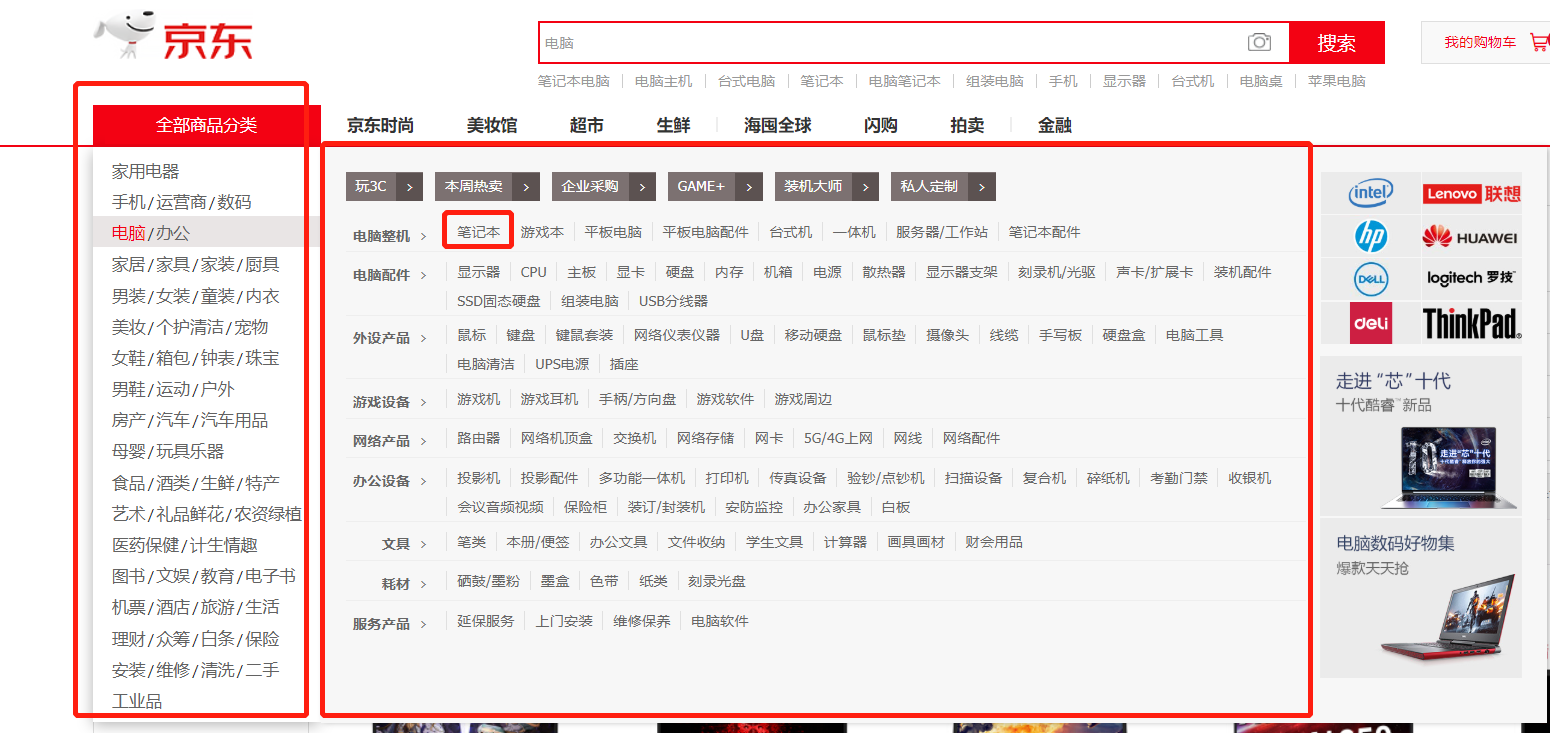
- 2、跳转到二级域名下的商品列表里,他展示全部的页码。
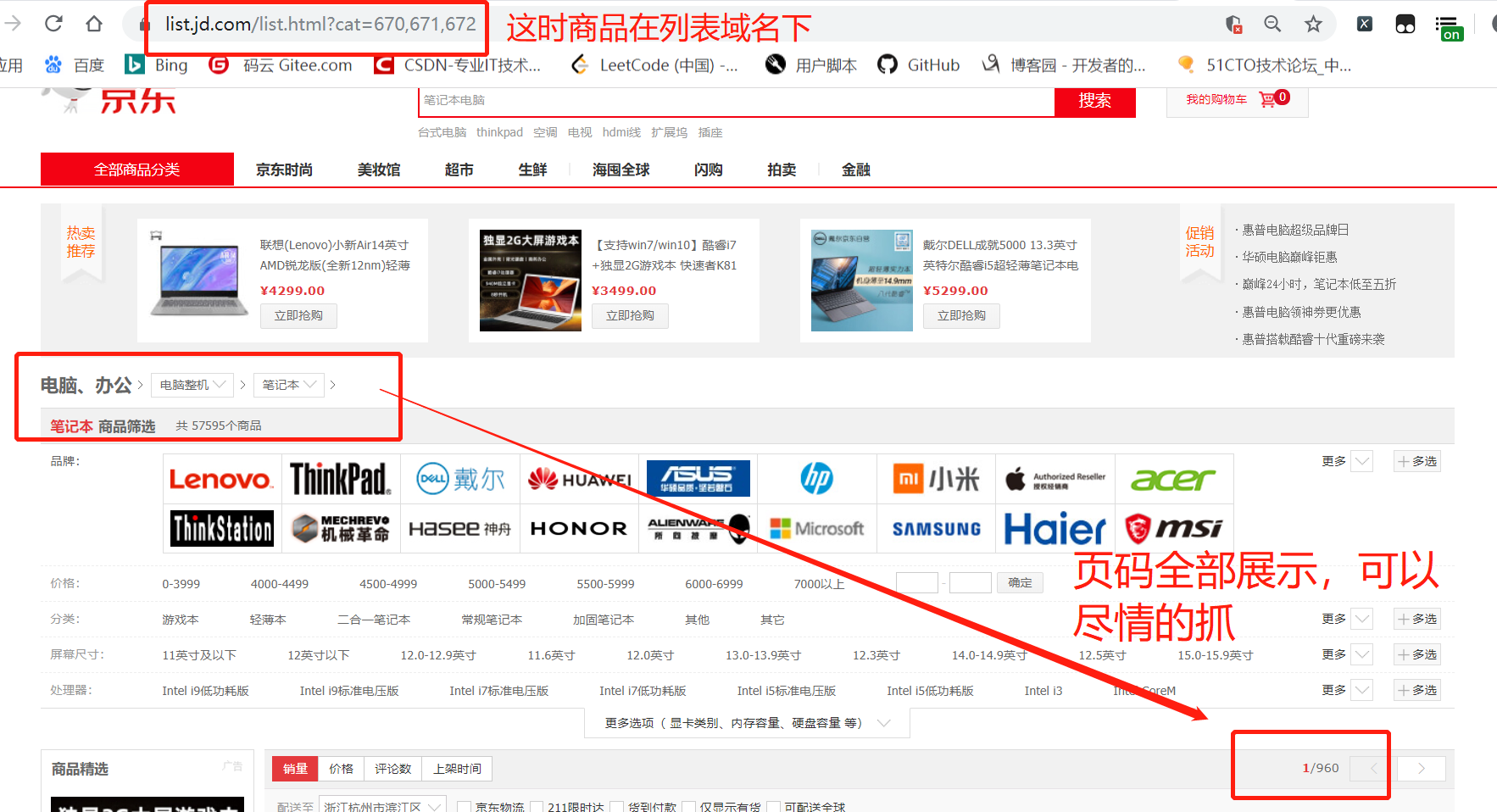
- 3、这种方法可以用于全站抓取哦。
三、商品详情页的同款商品可以一并获取
-
1、抓到具体到商品详情页后,会发现很多同款不同信号的商品,可以一起抓取
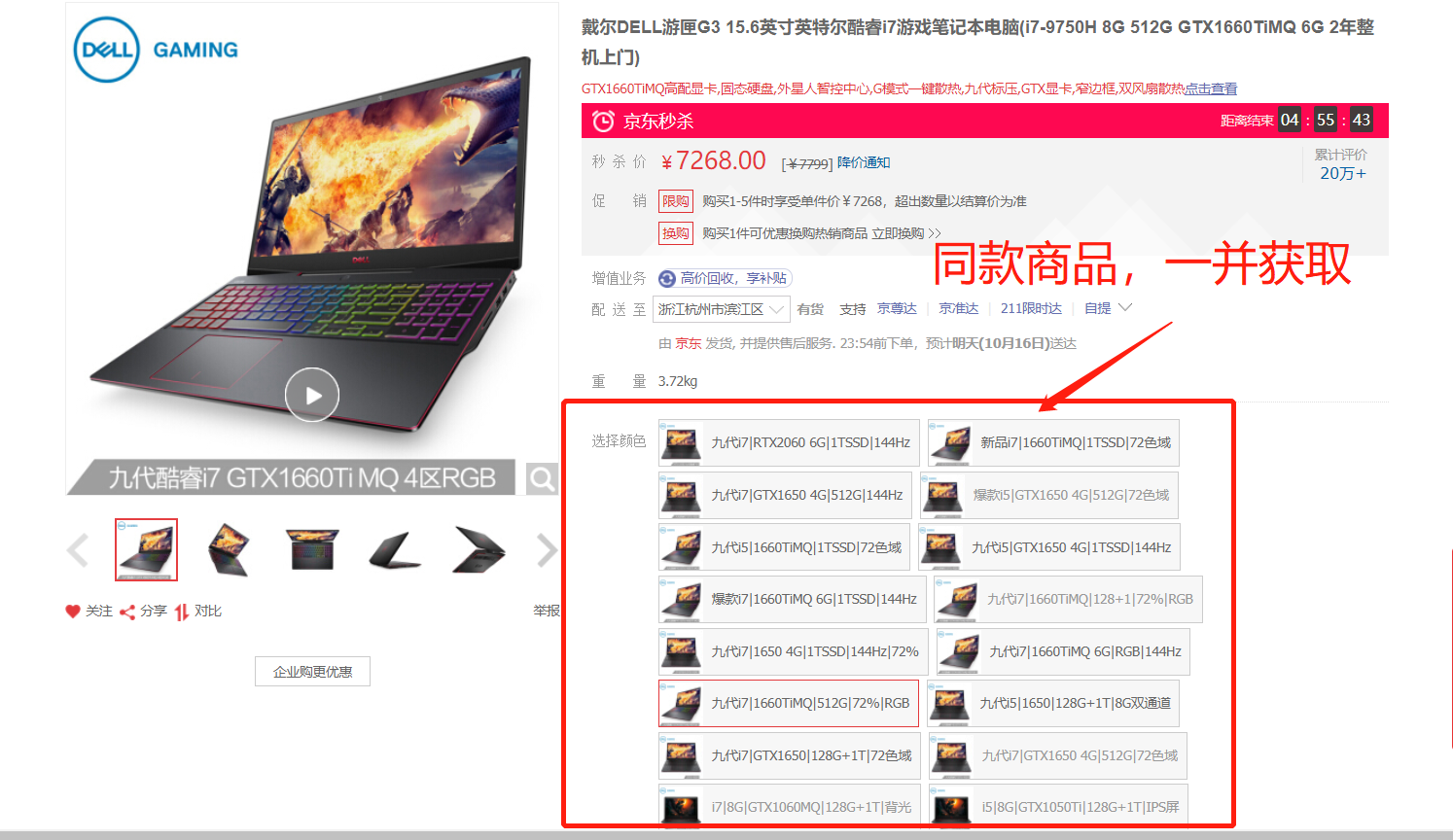
-
2、这个商品列表,需要用到源代码正则匹配。
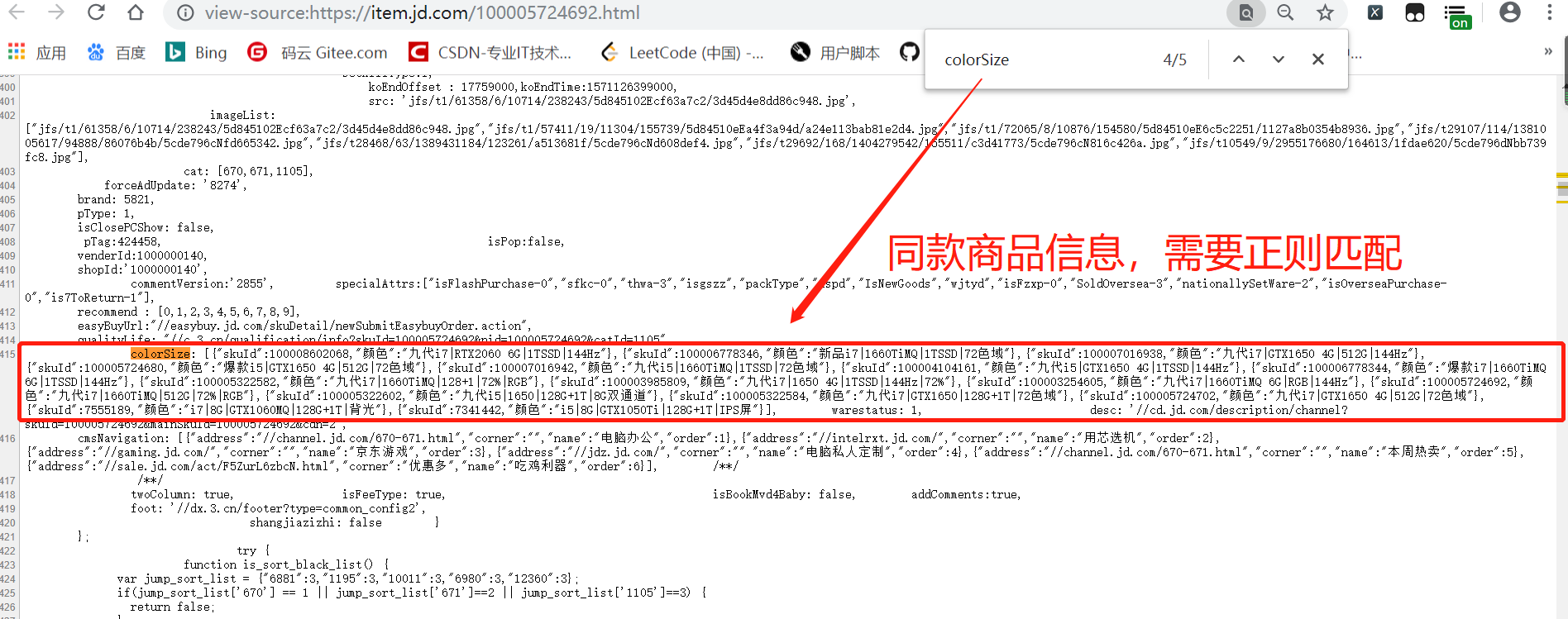
正则规则: re.findall(r"colorSize:(.*?}]),[ ]+?[warestatus:]+", response)这时,提取到的是每一个商品的
skuId和颜色信息,再用字符串拼接商品的URL"https://item.jd.com/{skuId}.html",去提取每一个商品的信息即可。














 743
743










 暂无认证
暂无认证





















 到【灌水乐园】发言
到【灌水乐园】发言










m0_70808317: 为啥我下拉进度条也没有继续加载后面的商品啊
Java_小菜狗: 可以很强
EX十六*碣: 找到办法了,还有一种可能,BIOS里CPU的虚拟机硬件支持没有打开,设置成Enabled就可以了。
cpyinf: 能贴出源码吗,我用了这个方法报错了,报错显示 spider.browser.get(request.url) AttributeError: 'MobileSpider' object has no attribute 'browser'
fenjincheng: 讲的真好。