算法笔记:字符串编辑距离(Edit Distance on Real sequence,EDR)/ Levenshtein距离

UQI-LIUWJ
 已于 2023-12-09 20:24:26 修改
已于 2023-12-09 20:24:26 修改
 阅读量754
阅读量754
 收藏
2
收藏
2
 点赞数
点赞数
已于 2023-12-09 20:24:26 修改
阅读量754
收藏
2

 点赞数
点赞数
于 2023-04-10 15:11:54 首次发布

1 算法介绍
- 给定两个长度分别为n和m的轨迹tr1和tr2,最小距离的匹配阈值e
- 两条轨迹之间的EDR距离就是需要对轨迹tr1进行插入、删除或替换使其变为tr2的操作次数
- 动态规划的算法如下
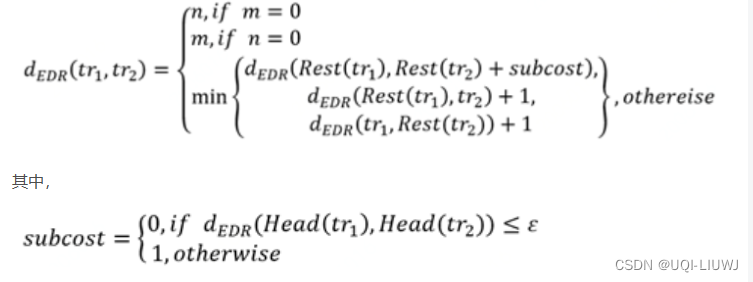
红色的是还没有考虑的两个轨迹部分;黑色是已经考虑过的两个轨迹部分
2 举例
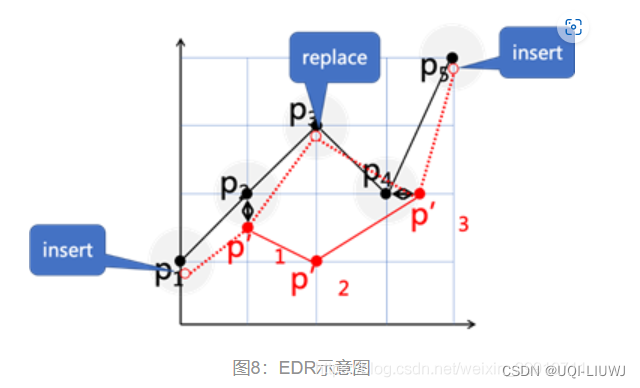
- 在p1处“插入”一点、将p2'“替换”替换为p3和在p5处“插入”一点,共计3个操作使两条轨迹相等(即对应点距离均小于阈值),故其EDR值为3
3 python代码
3.1 自行实现
import numpy as np
def EDR(TR1,TR2):
m,n = len(TR1)+1,len(TR2)+1
matrix = np.zeros((m,n))
#matrix[i][j]表示 TR1还剩i个元素,TR2还剩j个元素时,他们的编辑距离
for i in range(1,m):
matrix[i][0] = i
for j in range(1,n):
matrix[0][j] = j
#这两个for循环表示,一个轨迹没有元素了,另一个轨迹还有n个元素,那么此时编辑距离为n(插入/删除n个值
for i in range(1,m):
for j in range(1,n):
if TR1[i-1]==TR2[j-1]:
cost = 0
else:
cost = 1
#判断两个轨迹对应位置的值是否一致
matrix[i][j]=min(matrix[i-1][j]+1,matrix[i][j-1]+1,matrix[i-1][j-1]+cost)
#删除,插入,替换,这三个操作哪个编辑距离小一点,就选哪个
return matrix
disEDR=EDR("ivan1","ivan2")
disEDR[-1][-1],disEDR
'''
(1.0,
array([[0., 1., 2., 3., 4., 5.],
[1., 0., 1., 2., 3., 4.],
[2., 1., 0., 1., 2., 3.],
[3., 2., 1., 0., 1., 2.],
[4., 3., 2., 1., 0., 1.],
[5., 4., 3., 2., 1., 1.]]))
'''3.2 editdistpy包
EDR的快速实现
import sys
from editdistpy import levenshtein
string_1 = "ivan1"
string_2 = "ivan2"
levenshtein.distance(string_1, string_2,sys.maxsize)
#1
levenshtein.distance(string_1, string_2,0.5)
#-1
如果编辑距离小于第三个变量,那么就返回编辑距离,否则返回-1
参考内容:
轨迹相似性度量方法_轨迹相似度_意念回复的博客-CSDN博客
字符串编辑距离(Levenshtein距离)算法 - BlackStorm - 博客园 (cnblogs.com)















 3299
3299










 高校学生
高校学生














































 到【灌水乐园】发言
到【灌水乐园】发言












Haruのpopura: 楼主你好,第三节公式6中提到时间正则化项为负对数似然函数,请问一下,当时序模型为AR时,公式(9)里面的时间正则化项T_AR()里面为什么并不等于AR模型的负对数似然函数?按理说AR模型里面是包含高斯噪声的,假设服从N(0,P)的正态分布,AR的似然函数里面也应该包含参数P的,但是公式(9)里面并没有
Haruのpopura: 我要是能早点看到就好了!!
Dustin5173: 牛,来自一个从业者的点赞
leon_lihang: 这种情况通常发生在时间序列的起始阶段或者结束阶段,因为在计算趋势时,需要考虑到较短的时间窗口。当时间序列的起始或结束的数据点不足以支撑趋势的计算时,就会导致趋势部分出现空值。 这种情况的处理方式可以是: 忽略空值:在分析时忽略这些空值,聚焦于非空值的数据点。 插值处理:通过插值方法填补这些空值,使得趋势部分更加平滑。常见的插值方法包括线性插值、多项式插值等。 调整参数:尝试调整seasonal_decompose函数的参数,比如调整趋势部分的窗口大小,以期减少空值的出现。 总的来说,出现空值的趋势部分并不罕见,可以通过上述方法进行处理,以便更好地分析和理解时间序列数据。 【以上回答来源chatgpt】
专家-百锦再@新空间代码工作室: 这篇文章的亮点在于作者对复杂问题的深入剖析,特别是在第二节中提到的潜在解决方案。这些方案不仅涵盖了各个层面的考虑,而且给出了可行的实施建议。这种全面性和可操作性使得这篇文章非常有价值。