浏览器打印出完整的知乎文章为PDF文件
最新推荐文章于 2024-06-12 20:49:37 发布

集电极
 最新推荐文章于 2024-06-12 20:49:37 发布
最新推荐文章于 2024-06-12 20:49:37 发布
 阅读量1.5w
阅读量1.5w
 收藏
65
收藏
65
 点赞数
30
点赞数
30
最新推荐文章于 2024-06-12 20:49:37 发布
阅读量1.5w
收藏
65

 点赞数
30
点赞数
30

浏览器打印出完整的知乎文章为PDF文件
1.前言
最近看知乎文章,遇到一些好文章想打印下载成PDF文件方便收藏和离线阅读。但知乎文章正常打印会有上下两个栏幅挡住一些内容,非常影响阅读。在网上也找了一些方法,感觉说的不是那么好,特写这篇文章。
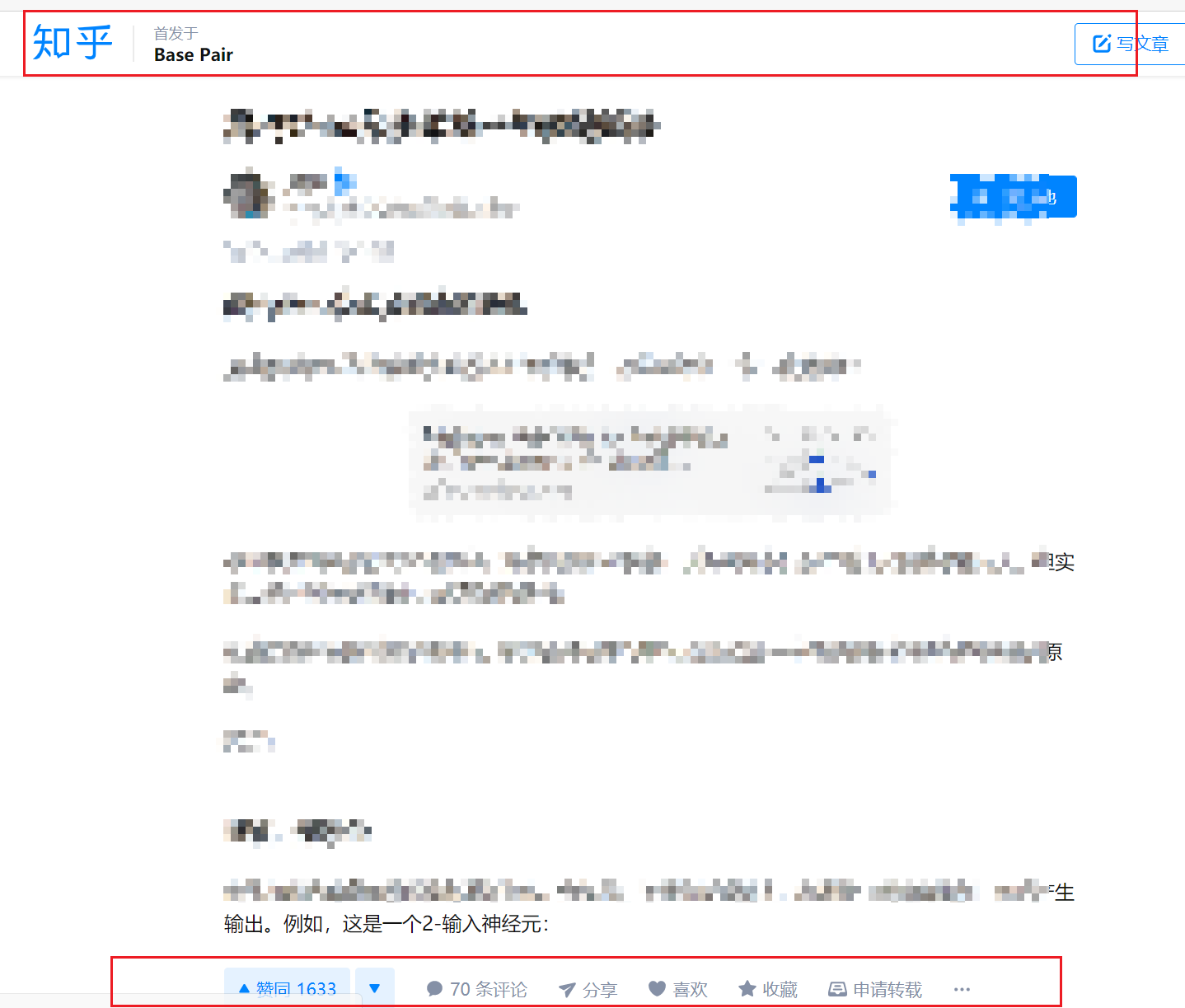
说明:暂时只找到打印知乎文章的方法,对知乎问题的解答还没有好的打印方法
2020/11/1更新打印问题解答打印方法
用火狐浏览器打印才可以,同下面操作去掉上边框即可。
由此怀疑其他浏览器是按手机模式打印的,因为在手机打印时才会出现那【继续浏览内容选项】
Chrome派系浏览器

火狐浏览器

。
2.打印流程
2.1.去除上边的遮挡栏
首先在上边栏找一个地方右击,比如在【知乎】两字右击,然后点击检查选项跳到源代码【知乎】哪里。
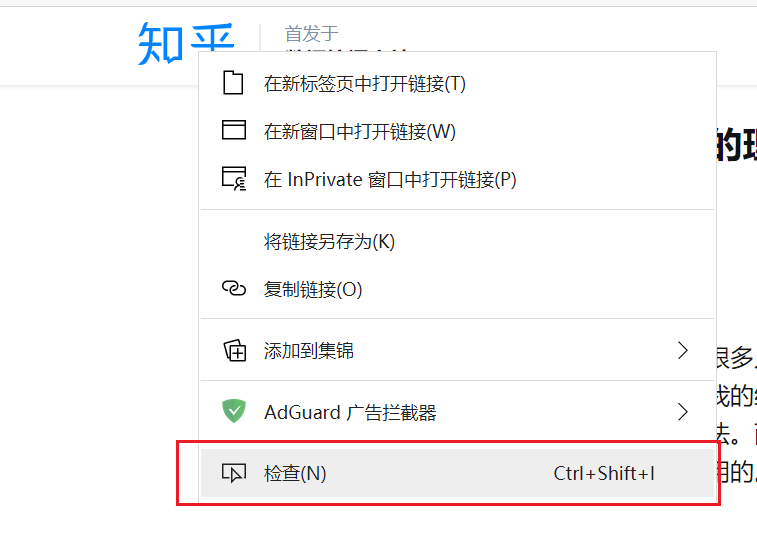
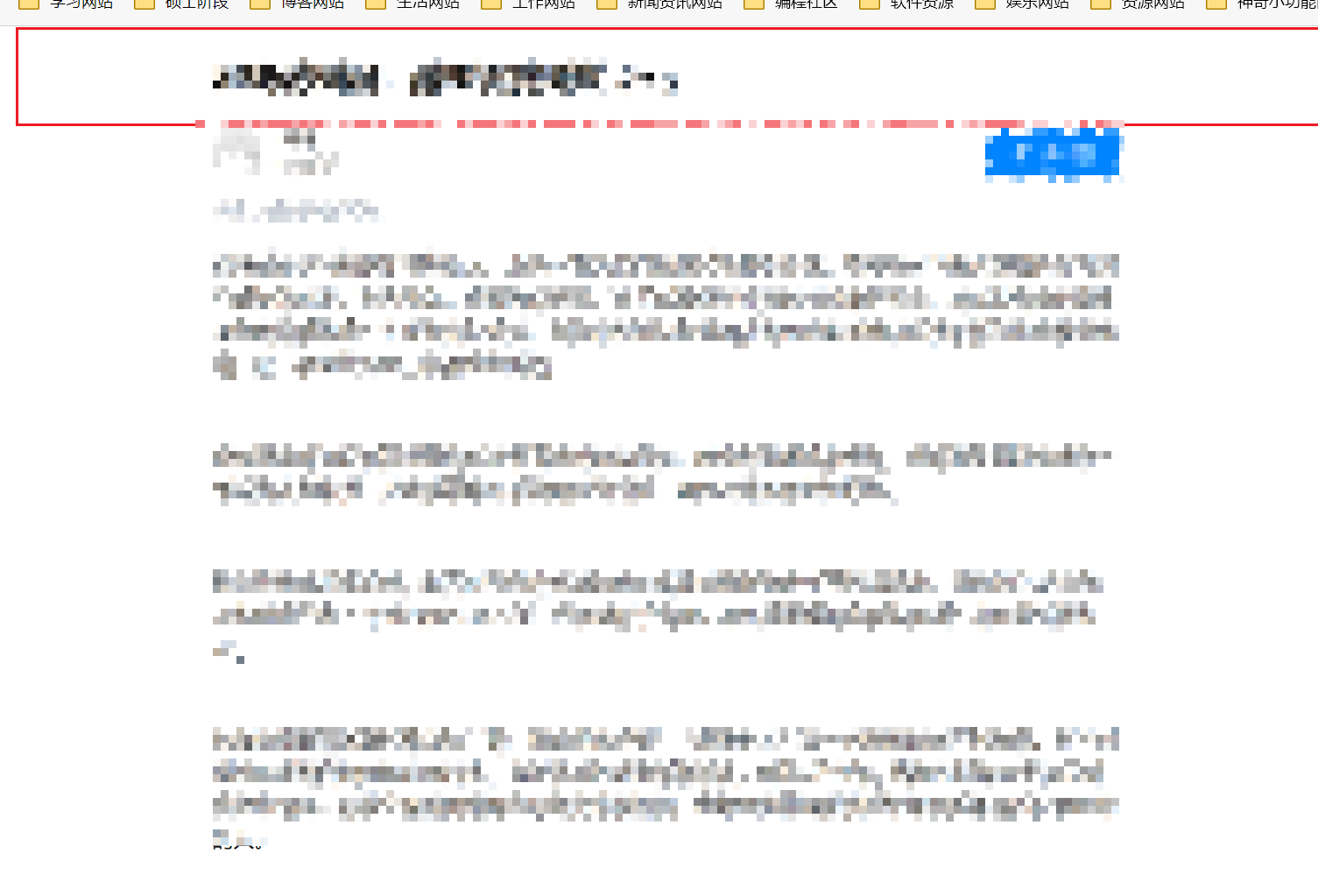
在源代码调试框下,向上移动鼠标,找到整个【遮挡栏的】源代码句,就是如下图表示的使整个【栏】变蓝色的那一句


最后,右击把那整句删了。

可以看到【上边遮挡栏不见了】这时不要刷新了,刷新之后又重来了
如果删了还存在白边,可能是没有删到最顶层的代码,继续删除
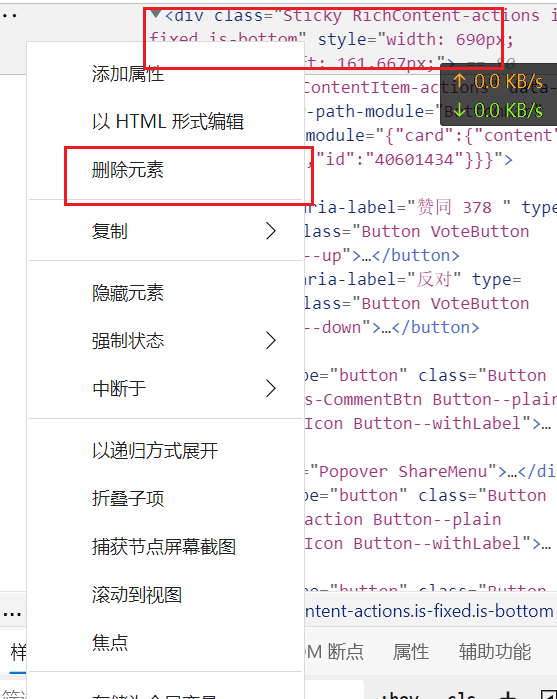
2.2 去除下面遮挡栏
更新一下(换了一个浏览器)
点击下边框点击查找,在源码结构树找到对应节点


右击删除即可


和去除上面遮挡栏一样。下面只给出图
3打印图

。
。
。
。
。
。















 1114
1114










 暂无认证
暂无认证



































 到【灌水乐园】发言
到【灌水乐园】发言










带羊人: 我有一个问题,如果我要在一个类的其中一个槽函数里面返回数据,那类外面的语句应该怎么调用呢
集电极: 这些代码是在同一个代码文件的。如果你自行切分为多个文件运行,CoraData类在 In [3]: 中。
weixin_53153905: from dataset import CoraData,请问这个自定义的包在哪里呢,百度网盘找不到了
rybd111: 输入neo4j是错误的,提示没有授权
theoffspring: 控件改名就尴尬了