IIS屏蔽搜索引擎爬虫

 于 2020-11-18 11:50:55 发布
于 2020-11-18 11:50:55 发布
 阅读量1.3k
阅读量1.3k
 收藏
4
收藏
4


 点赞数
点赞数
事情的起源,还是来自于站点的日志系统,发现了很多莫名的异常报错,领导要求排查减少日志上的错误数量。检查发现请求的地址是业务地址,但是没有带用户授权标识上来, 一般正常的用户不会发生这种情况呀。 再细致一检查,这类异常请求的ua 都带有 bot、spider 诸如 baidu.com/search/spider ,www.similartech.com/smtbot,http://www.bing.com/bingbot.htm 等等 那么说明这些都为搜索引擎的机器人爬虫
这是回想我们设置在站点下放的防采集文件,robots文件,里面已经有配置很多禁止采集的设置了,使用站长工具生成的robots文件格式也很标准。哎仔细一查,很多搜索引擎都不按禁止采集规则走都直接进行请求,机器人是不会带我们客户的登陆标识的,直接请求我们业务地址导致的业务执行错误。
综上,最好的解决方案 我们按照客户端请求的ua User-Agent 进行拦截, 凡是ua中带有bot spider字样出现的,先都统统屏蔽了。 虽然有可能误杀某个浏览器的ua就是有带bot, 但现在是基于系统中的日志来看是没有的
这里我们的服务器是iis 要用到一个iis重写功能 iisrewrite

添加规则,针其中针对符合条件规则的请求进行阻止
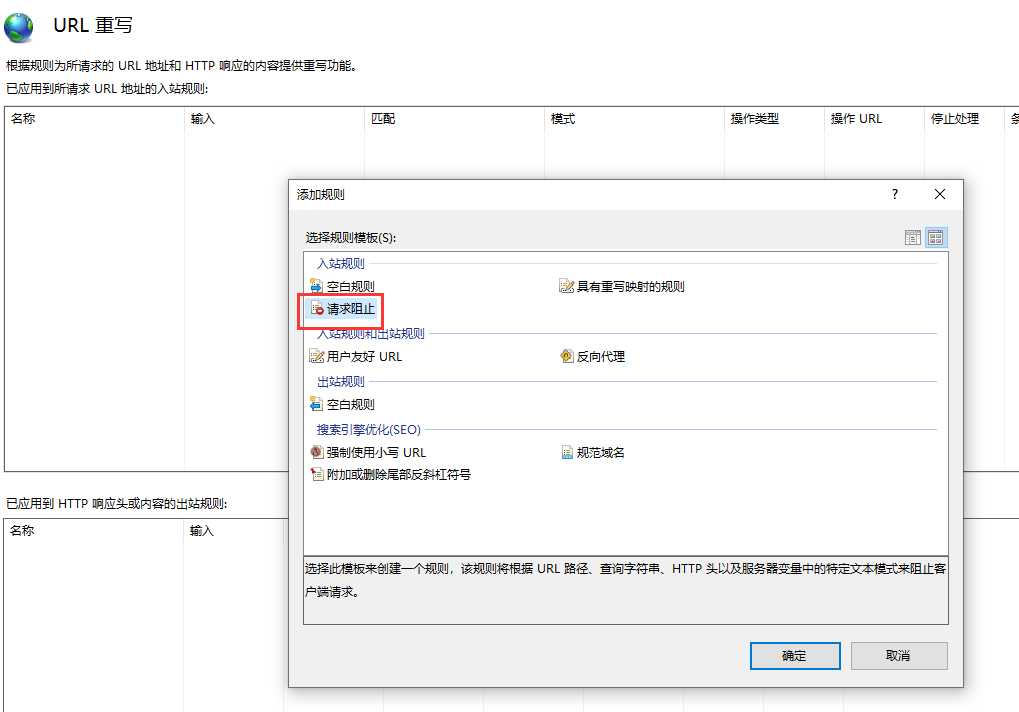
这里我们选择请求用户代理标头 也就是用户请求的ua User-Agent 使用正则表达式进行匹配
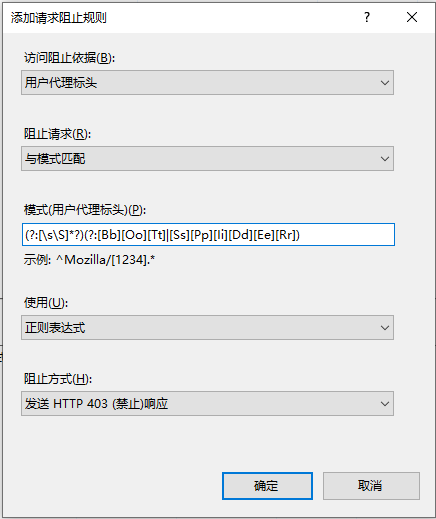
这里放出福利,正则匹配规则:
(?:[\s\S]*?)(?:[Bb][Oo][Tt]|[Ss][Pp][Ii][Dd][Ee][Rr])
点击确定,即可完成 这是我们用postman对网站设置进行一个检验:当Ua是正常浏览器的时候 返回的是正确的信息

当ua中含有搜索引擎相关的标头出现的时候, 请求即被拦截















 1910
1910










 暂无认证
暂无认证











 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 非常感谢CSDN博主的分享,这篇博客介绍了wireshark抓取https的方法,对网络安全有很大的帮助。我觉得接下来可以写一篇关于HTTPS的深度解析,包括HTTPS的原理、SSL/TLS协议、证书认证等方面的内容。这样的技术文章对其他用户的学习和实践都有很大的帮助。相信会有更多读者期待您的下一篇博客。加油! 为了方便博主创作,提高生产力,CSDN上线了AI写作助手功能,就在创作编辑器右侧哦~(https://mp.csdn.net/edit?utm_source=blog_comment_recall )诚邀您来加入测评,到此(https://activity.csdn.net/creatActivity?id=10450&utm_source=blog_comment_recall)发布测评文章即可获得「话题勋章」,同时还有机会拿定制奖牌。
weixin_39803622: 怎么联系你交流一下
weixin_42146002: 怎么联系你
Nappyboy: 写的很详细,wx_Haloom 同学现在在哪里工作呀?