如何用Python提取中文关键词?

 最新推荐文章于 2024-01-22 12:30:03 发布
最新推荐文章于 2024-01-22 12:30:03 发布
 阅读量3.2w
阅读量3.2w
 收藏
144
收藏
144


 点赞数
30
点赞数
30
本文一步步为你演示,如何用Python从中文文本中提取关键词。如果你需要对长文“观其大略”,不妨尝试一下。

(由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
需求
好友最近对自然语言处理感兴趣,因为他打算利用自动化方法从长文本里提取关键词,来确定主题。
他向我询问方法,我推荐他阅读我的那篇《如何用Python从海量文本提取主题?》。
看过之后,他表示很有收获,但是应用场景和他自己的需求有些区别。
《如何用Python从海量文本提取主题?》一文面对的是大量的文档,利用主题发现功能对文章聚类。而他不需要处理很多的文档,也没有聚类的需求,但是需要处理的每篇文档都很长,希望通过自动化方法从长文提取关键词,以观其大略。
我突然发现,之前居然忘了写文,介绍单一文本关键词的提取方法。
虽然这个功能实现起来并不复杂,但是其中也有些坑,需要避免踩进去的。
通过本文,我一步步为你演示如何用Python实现中文关键词提取这一功能。
环境
Python
第一步是安装Python运行环境。我们使用集成环境Anaconda。
请到这个网址 下载最新版的Anaconda。下拉页面,找到下载位置。根据你目前使用的系统,网站会自动推荐给你适合的版本下载。我使用的是macOS,下载文件格式为pkg。

下载页面区左侧是Python 3.6版,右侧是2.7版。请选择2.7版本。
双击下载后的pkg文件,根据中文提示一步步安装即可。

样例
我专门为你准备了一个github项目,存放本文的配套源代码和数据。请从这个地址下载压缩包文件,然后解压。
解压后的目录名称为demo-keyword-extraction-master,样例目录包含以下内容:
除了README.md这个github项目默认说明文件外,目录下还有两个文件,分别是数据文件sample.txt和程序源代码文件demo-extract-keyword.ipynb。
结巴分词
我们使用的关键词提取工具为结巴分词。
之前在《如何用Python做中文分词?》一文中,我们曾经使用过该工具为中文语句做分词。这次我们使用的,是它的另一项功能,即关键词提取。
请进入终端,使用cd命令进入解压后的文件夹demo-keyword-extraction-master,输入以下命令:
pip install jieba
好了,软件包工具也已经准备就绪。下面我们执行
jupyter notebook
进入到Jupyter笔记本环境。

到这里,环境已经准备好了,我们下面来介绍本文使用的中文文本数据。
数据
一开始,我还曾为寻找现成的中文文本发愁。
网上可以找到的中文文本浩如烟海。
但是拿来做演示,是否会有版权问题,我就不确定了。万一把哪位大家之作拿来做了分析,人家可能就要过问一句“这电子版你是从哪里搞到的啊?”
万一再因此提出诉讼,我可无法招架。
后来发现,我这简直就是自寻烦恼——找别人的文本干什么?用我自己的不就好了?
这一年多以来,我写的文章已有90多篇,总字数已经超过了27万。

我特意从中找了一篇非技术性的,以避免提取出的关键词全都是Python命令。
我选取的,是去年的那篇《网约车司机二三事》。

这篇文章,讲的都是些比较有趣的小故事。
我从网页上摘取文字,存储到sample.txt中。
注意,这里是很容易踩坑的地方。在夏天的一次工作坊教学中,好几位同学因为从网上摘取中文文本出现问题,卡住很长时间。
这是因为不同于英语,汉字有编码问题。不同系统都有不同的默认编码,不同版本的Python接受的编码也不同。你从网上下载的文本文件,也可能与你系统的编码不统一。

不论如何,这些因素都有可能导致你打开后的文本里,到处都是看不懂的乱码。
因而,正确的使用中文文本数据方式,是你在Jupyter Notebook里面,新建一个文本文件。
然后,会出现以下的空白文件。
把你从别处下载的文本,用任意一种能正常显示的编辑器打开,然后拷贝全部内容,粘贴到这个空白文本文件中,就能避免编码错乱。
避开了这个坑,可以为你节省很多不必要的烦恼尝试。
好了,知道了这个窍门,下面你就能愉快地进行关键词提取了。
执行
回到Jupyter Notebook的主界面,点击demo-extract-keyword.ipynb,你就能看到源码了。

对,你没看错。只需要这短短的4个语句,就能完成两种不同方式(TF-idf与TextRank)的关键词提取。
本部分我们先讲解执行步骤。不同关键词提取方法的原理,我们放在后面介绍。
首先我们从结巴分词的分析工具箱里导入所有的关键词提取功能。
from jieba.analyse import *
在对应的语句上,按下Shift+Enter组合按键,就可以执行语句,获取结果了。
然后,让Python打开我们的样例文本文件,并且读入其中的全部内容到data变量。
with open('sample.txt') as f:
data = f.read()
使用TF-idf方式提取关键词和权重,并且依次显示出来。如果你不做特殊指定的话,默认显示数量为20个关键词。
for keyword, weight in extract_tags(data, withWeight=True):
print('%s %s' % (keyword, weight))
显示内容之前,会有一些提示,不要管它。
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.547 seconds.
Prefix dict has been built succesfully.
然后列表就出来了:
优步 0.280875594782
司机 0.119951947597
乘客 0.105486129485
师傅 0.0958888107815
张师傅 0.0838162334963
目的地 0.0753618512886
网约车 0.0702188986954
姐姐 0.0683412127766
自己 0.0672533110661
上车 0.0623276916308
活儿 0.0600134354214
天津 0.0569158056792
10 0.0526641740216
开优步 0.0526641740216
事儿 0.048554456767
李师傅 0.0485035501943
天津人 0.0482653686026
绕路 0.0478244723097
出租车 0.0448480260748
时候 0.0440840298591
我看了一下,觉得关键词提取还是比较靠谱的。当然,其中也混入了个数字10,好在无伤大雅。
如果你需要修改关键词数量,就需要指定topK参数。例如你要输出10个关键词,可以这样执行:
for keyword, weight in extract_tags(data, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
下面我们尝试另一种关键词提取方式——TextRank。
for keyword, weight in textrank(data, withWeight=True):
print('%s %s' % (keyword, weight))
关键词提取结果如下:
优步 1.0
司机 0.749405996648
乘客 0.594284506457
姐姐 0.485458741991
天津 0.451113490366
目的地 0.429410027466
时候 0.418083863303
作者 0.416903838153
没有 0.357764515052
活儿 0.291371566494
上车 0.277010013884
绕路 0.274608592084
转载 0.271932903186
出来 0.242580745393
出租 0.238639889991
事儿 0.228700322713
单数 0.213450680366
出租车 0.212049665481
拉门 0.205816713637
跟着 0.20513470986
注意这次提取的结果,与TF-idf的结果有区别。至少,那个很突兀的“10”不见了。
但是,这是不是意味着TextRank方法一定优于TF-idf呢?
这个问题,留作思考题,希望在你认真阅读了后面的原理部分之后,能够独立做出解答。
如果你只需要应用本方法解决实际问题,那么请跳过原理部分,直接看讨论吧。
原理
我们简要讲解一下,前文出现的2种不同关键词提取方式——TF-idf和TextRank的基本原理。
为了不让大家感到枯燥,这里咱们就不使用数学公式了。后文我会给出相关的资料链接。如果你对细节感兴趣,欢迎按图索骥,查阅学习。
先说TF-idf。
它的全称是 Term Frequency - inverse document frequency。中间有个连字符,左右两侧各是一部分,共同结合起来,决定某个词的重要程度。
第一部分,就是词频(Term Frequency),即某个词语出现的频率。
我们常说“重要的事说三遍”。
同样的道理,某个词语出现的次数多,也就说明这个词语重要性可能会很高。
但是,这只是可能性,并不绝对。
例如现代汉语中的许多虚词——“的,地,得”,古汉语中的许多句尾词“之、乎、者、也、兮”,这些词在文中可能出现许多次,但是它们显然不是关键词。
这就是为什么我们在判断关键词的时候,需要第二部分(idf)配合。
逆文档频率(inverse document frequency)首先计算某个词在各文档中出现的频率。假设一共有10篇文档,其中某个词A在其中10篇文章中都出先过,另一个词B只在其中3篇文中出现。请问哪一个词更关键?
给你一分钟思考一下,然后继续读。
公布答案时间到。
答案是B更关键。
A可能就是虚词,或者全部文档共享的主题词。而B只在3篇文档中出现,因此很有可能是个关键词。
逆文档频率就是把这种文档频率取倒数。这样第一部分和第二部分都是越高越好。二者都高,就很有可能是关键词了。
TF-idf讲完了,下面我们说说TextRank。
相对于TF-idf,TextRank要显得更加复杂一些。它不是简单做加减乘除运算,而是基于图的计算。
下图是原始文献中的示例图。
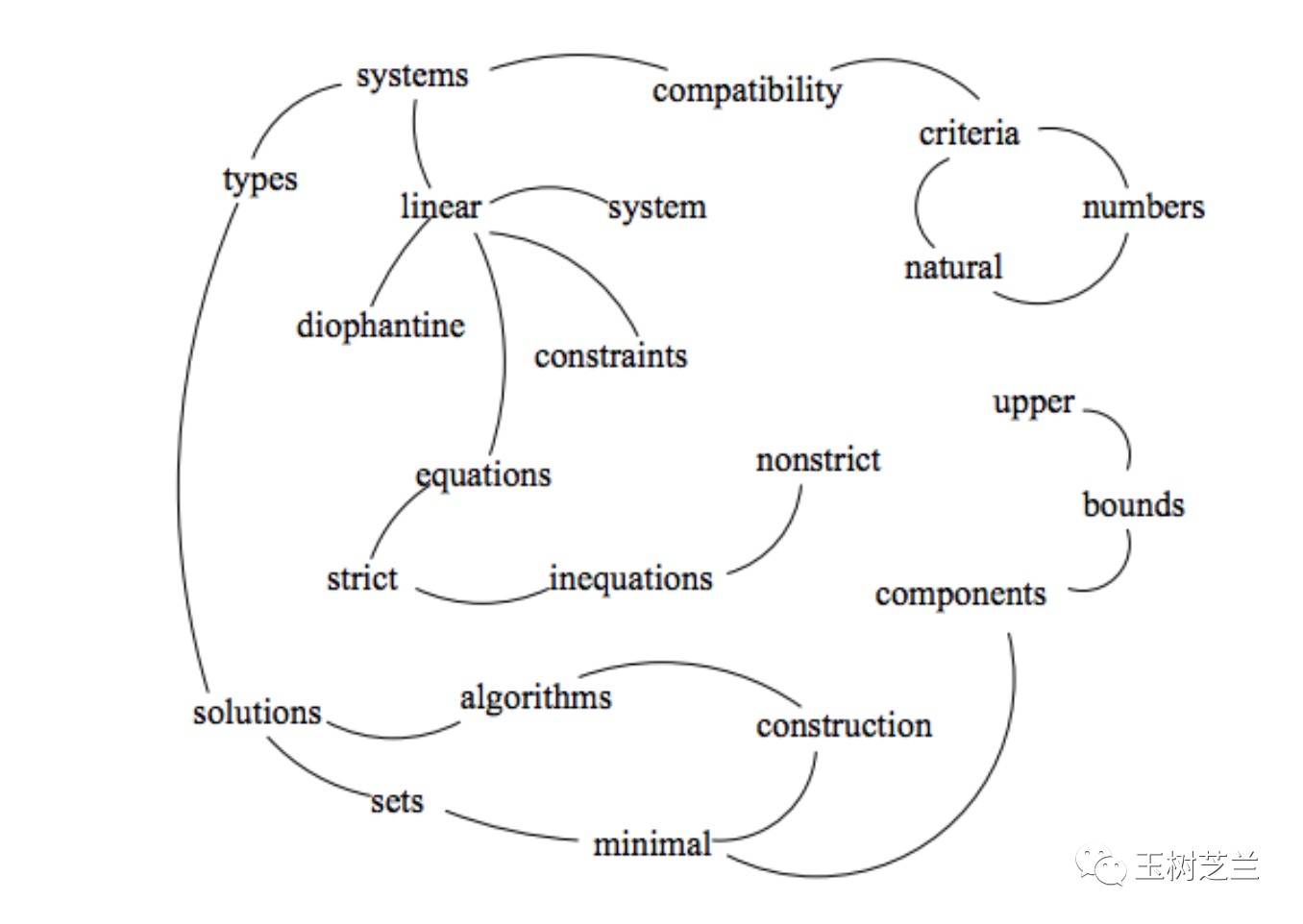
TextRank首先会提取词汇,形成节点;然后依据词汇的关联,建立链接。
依照连接节点的多少,给每个节点赋予一个初始的权重数值。
然后就开始迭代。
根据某个词所连接所有词汇的权重,重新计算该词汇的权重,然后把重新计算的权重传递下去。直到这种变化达到均衡态,权重数值不再发生改变。这与Google的网页排名算法PageRank,在思想上是一致的。

根据最后的权重值,取其中排列靠前的词汇,作为关键词提取结果。
如果你对原始文献感兴趣,请参考以下链接:
TF-idf原始文献链接。
TextRank原始文献链接。
讨论
小结一下,本文探讨了如何用Python对中文文本做关键词提取。具体而言,我们分别使用了TF-idf和TextRank方法,二者提取关键词的结果可能会有区别。
你做过中文关键词提取吗?使用的是什么工具?它的效果如何?有没有比本文更高效的方法?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
如果你对我的文章感兴趣,欢迎点赞,并且微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果本文可能对你身边的亲友有帮助,也欢迎你把本文通过微博或朋友圈分享给他们。让他们一起参与到我们的讨论中来。
如果喜欢我的文章,请微信扫描下方二维码,关注并置顶我的公众号“玉树芝兰”。

如果你希望支持我继续输出更多的优质内容,欢迎微信识别下方的赞赏码,打赏本文。感谢支持!

欢迎微信扫码加入我的“知识星球”圈子。第一时间分享给你我的发现和思考,优先解答你的疑问。















 1万+
1万+










 暂无认证
暂无认证










 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: Python入门 技能树或许可以帮到你:https://edu.csdn.net/skill/python?utm_source=AI_act_python
chenxia89: 王老师,为啥文章都是只有一半啊
The_kisses: 那五个模式怎么集齐呀
单翼天使S: 演示数据集能分享一下吗