hadoop中MapReduce和yarn的基本原理讲解

 最新推荐文章于 2024-04-03 16:33:34 发布
最新推荐文章于 2024-04-03 16:33:34 发布
 阅读量2.1k
阅读量2.1k
 收藏
20
收藏
20


 点赞数
5
点赞数
5

目录
1.1 执行流程
1.2 工作原理
Map任务处理
Reduce任务处理
MR的Shuffle过程
1.3 运行流程分析
2 yarn
2.1简介
2.2 组成
1. ResourceManager
2. NodeManager
3.ApplicationMaster(AM)
4. Container
2.3 工作原理
1 MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
记住这2点:
1、MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
2、MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
1.1 执行流程
由图我们可以看到, MapReduce存在以下4个独立的实体。
1. JobClient:运行于client node,负责将MapReduce程序打成Jar包存储到HDFS,并把Jar包的路径提交到Jobtracker,由Jobtracker进行任务的分配和监控。
2. JobTracker:运行于name node,负责接收JobClient提交的Job,调度Job的每一个子task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
3. TaskTracker:运行于data node,负责主动与JobTracker通信,接收作业,并直接执行每一个任务。
4. HDFS:用来与其它实体间共享作业文件。
各实体间通过以下过程完成一次MapReduce作业。
- JobClient通过RPC协议向JobTracker请求一个新应用的ID,用于MapReduce作业的ID
- JobTracker检查作业的输出说明。例如,如果没有指定输出目录或目录已存在,作业就不提交,错误抛回给JobClient,否则,返回新的作业ID给JobClient
- JobClient将作业所需的资源(包括作业JAR文件、配置文件和计算所得得输入分片)复制到以作业ID命名的HDFS文件夹中
- JobClient通过submitApplication()提交作业
- JobTracker收到调用它的submitApplication()消息后,进行任务初始化
- JobTracker读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个TaskTracker
- askTracker通过心跳机制领取任务(任务的描述信息)
- TaskTracker读取HDFS上的作业资源(JAR包、配置文件等)
-
TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)
-
TaskTracker将Reduce结果写入到HDFS当中
1.2 工作原理
Map任务处理
- 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数
- 重写map(),对第一步产生的<k,v>进行处理,转换为新的<k,v>输出
- 对输出的key、value进行分区
- 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中
- (可选) 对分组后的数据进行归约
Reduce任务处理
- 多个map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点上
- 对多个map的输出进行合并、排序。
- 重写reduce函数实现自己的逻辑,对输入的key、value处理,转换成新的key、value输出
- 把reduce的输出保存到文件中
MR的Shuffle过程
MapReduce计算模型主要由三个阶段构成:Map、Shuffle、Reduce。Map是映射,负责数据的过滤分类,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果;为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,这个过程就是Shuffle。Shuffle过程包含Map Shuffle和Reduce Shuffle。
1)Map Shuffle
在Map端的shuffle过程就是对Map的结果进行分区、排序、分割,然后将属于同一个分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。分区有序的含义是Map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排序(默认),大致流程如下:
2)Reduce Shuffle
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(这些通知在心跳机制中进行)。所以,对于指定作业来说,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
1.3 运行流程分析

流程分析:
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数
2 yarn
2.1简介
Yarn是Hadoop集群的资源管理系统。Hadoop2.0对MapReduce框架做了彻底的设计重构,我们称Hadoop2.0中的MapReduce为MRv2或者Yarn。 它的目标是将这两部分功能分开,也就是分别用两个进程来管理这两个任务:
Yarn/MRv2最基本的想法是将原JobTracker主要的资源管理和job调度/监视功能分开作为两个单独的守护进程。有一个全局的ResourceManager(RM)和每个Application有一个ApplicationMaster(AM),Application相当于map-reduce job或者DAG jobs。ResourceManager和NodeManager(NM)组成了基本的数据计算框架。ResourceManager协调集群的资源利用,任何client或者运行着的applicatitonMaster想要运行job或者task都得向RM申请一定的资源。ApplicatonMaster是一个框架特殊的库,对于MapReduce框架而言有它自己的AM实现,用户也可以实现自己的AM,在运行的时候,AM会与NM一起来启动和监视tasks。
核心思想:将MP1中JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进程来实现。
1)ResourceManager:负责整个集群的资源管理和调度。
2)ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
YARN的出现,使得多个计算框架可以运行在一个集群当中。
1)每个应用程序对应一个ApplicationMaster。
2)目前可以支持多种计算框架运行在YARN上面比如MapReduce、Storm、Spark、Flink等。
2.2 组成
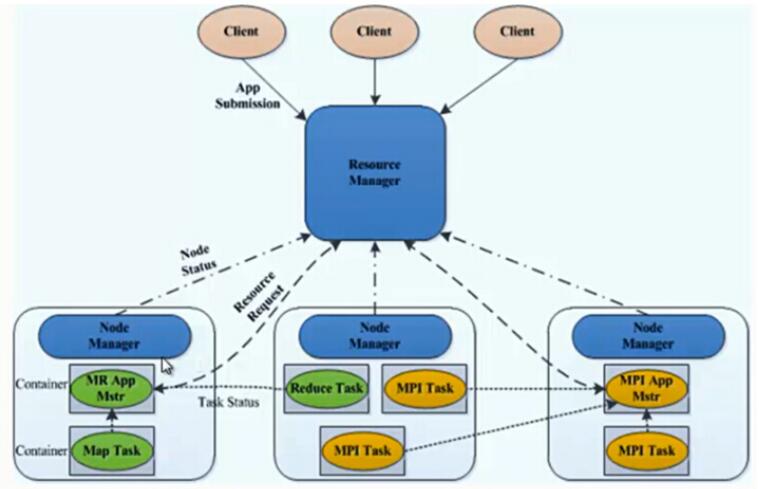
从 YARN 的架构图来看,它主要由ResourceManager、NodeManager、ApplicationMaster和Container等以下几个组件构成。
ResourceManager:一个Cluster只有一个,负责资源调度、资源分配等工作。
NodeManager:运行在DataNode节点,负责启动Application和对资源的管理。
JobHistoryServer:负责查询job运行进度及元数据管理。
Containers:Container通过ResourceManager分配。包括容器的CPU、内存等资源。
Application Master:ResourceManager将任务给Application Master,然后Application Master再将任务给NodeManager。每个Application只有一个Application Master,运行在Node Manager节点,Application Master是由ResourceManager指派的。
job:是需要执行的一个工作单元:它包括输入数据、MapReduce程序和配置信息。job也可以叫作Application。
task:一个具体做Mapper或Reducer的独立的工作单元。task运行在NodeManager的Container中。
Client:一个提交给ResourceManager的一个Application程序。
1. ResourceManager
RM 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:
调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排
给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色, ResourceManager 承担了 JobTracker 的角色。
(1)调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作。
(2)应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
2. NodeManager
NodeManager管理一个YARN集群中的每个节点。NodeManager提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1通过插槽管理Map和Reduce任务的执行,而NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。YARN继续使用HDFS层。它的主要 NameNode用于元数据服务,而DataNode用于分散在一个集群中的复制存储服务。
1)单个节点上的资源管理;
2)处理来自ResourceManager上的命令;
3)处理来自ApplicationMaster上的命令。
3.ApplicationMaster(AM)
ApplicationMaster管理一个在YARN内运行的应用程序的每个实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
1)负责数据的切分;
2)为应用程序申请资源并分配给内部的任务;
3)任务的监控与容错。
4. Container
对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息。比如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
要使用一个YARN集群,首先需要来自包含一个应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
2.3 工作原理
客户端程序向ResourceManager提交应用并请求一个ApplicationMaster实例
ResourceManager找到可以运行一个Container的NodeManager,并在这个Container中启动ApplicationMaster实例
ApplicationMaster向ResourceManager进行注册,注册之后客户端就可以查询ResourceManager获得自己ApplicationMaster的详细信息,以后就可以和自己的ApplicationMaster直接交互了
在平常的操作过程中,ApplicationMaster根据resource-request协议向ResourceManager发送resource-request请求
当Container被成功分配之后,ApplicationMaster通过向NodeManager发送container-launch-specification信息来启动Container, container-launch-specification信息包含了能够让Container和ApplicationMaster交流所需要的资料
应用程序的代码在启动的Container中运行,并把运行的进度、状态等信息通过application-specific协议发送给ApplicationMaster
YARN工作原理简述

Client提交作业到 YARN 上;
Resource Manager选择一个Node Manager,启动一个Container并运行Application Master实例;
Application Master根据实际需要向Resource Manager请求更多的Container资源(如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务);
Application Master通过获取到的Container资源执行分布式计算。
YARN工作原理详述

1. 作业提交
client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业 (第 1 步) 。新的作业 ID(应用 ID) 由资源管理器分配 (第 2 步)。作业的 client 核实作业的输出, 计算输入的 split, 将作业的资源 (包括 Jar 包,配置文件, split 信息) 拷贝给 HDFS(第 3 步)。最后, 通过调用资源管理器的 submitApplication() 来提交作业 (第 4 步)。
2. 作业初始化
当资源管理器收到 submitApplciation() 的请求时, 就将该请求发给调度器(scheduler), 调度器分配 container, 然后资源管理器在该 container 内启动应用管理器进程, 由节点管理器监控 (第 5 步)。MapReduce 作业的应用管理器是一个主类为 MRAppMaster 的 Java 应用,其通过创造一些 bookkeeping 对象来监控作业的进度, 得到任务的进度和完成报告 (第 6 步)。然后其通过分布式文件系统得到由客户端计算好的输入 split(第 7 步),然后为每个输入 split 创建一个 map 任务, 根据 mapreduce.job.reduces 创建 reduce 任务对象。
3. 任务分配
如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务。如果不是小作业, 那么应用管理器向资源管理器请求 container 来运行所有的 map 和 reduce 任务 (第 8 步)。这些请求是通过心跳来传输的, 包括每个 map 任务的数据位置,比如存放输入 split 的主机名和机架 (rack),调度器利用这些信息来调度任务,尽量将任务分配给存储数据的节点, 或者分配给和存放输入 split 的节点相同机架的节点。
4. 任务运行
当一个任务由资源管理器的调度器分配给一个 container 后,应用管理器通过联系节点管理器来启动 container(第 9 步)。任务由一个主类为 YarnChild 的 Java 应用执行, 在运行任务之前首先本地化任务需要的资源,比如作业配置,JAR 文件, 以及分布式缓存的所有文件 (第 10 步。最后, 运行 map 或 reduce 任务 (第 11 步)。YarnChild 运行在一个专用的 JVM 中, 但是 YARN 不支持 JVM 重用。
5. 进度和状态更新
YARN 中的任务将其进度和状态 (包括 counter) 返回给应用管理器, 客户端每秒 (通 mapreduce.client.progressmonitor.pollinterval 设置) 向应用管理器请求进度更新, 展示给用户。
6. 作业完成
除了向应用管理器请求作业进度外, 客户端每 5 分钟都会通过调用 waitForCompletion() 来检查作业是否完成,时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后, 应用管理器和 container 会清理工作状态, OutputCommiter 的作业清理方法也会被调用。作业的信息会被作业历史服务器存储以备之后用户核查。














 584
584










 暂无认证
暂无认证






































 到【灌水乐园】发言
到【灌水乐园】发言










qq_34728706: 只要Yong GC,S1和S0就会切换吧,不需要等到S0中的数据满
~being~: 很全面,感谢博主!
Bugbugggg: 讲的很透彻!!谢谢大佬的分享!!
nixinqi: 这个修改完在登陆进去里面下载的软件和配置会没有吗 我试过了很多都不行
快乐小王子之帅气哥哥: 写的好深入呀