02. Web请求过程分析

 已于 2023-01-18 01:43:55 修改
已于 2023-01-18 01:43:55 修改
 阅读量338
阅读量338
 收藏
3
收藏
3


 点赞数
2
点赞数
2

目录
前言
一个简单的例子
1. 服务器渲染
2. 前端JS渲染
得出结论
总结
Web请求全过程剖析
前言
上一小节我们实现了一个简单的网页源代码抓取工作,那么从根源出发,网页是如何访问的?源代码是怎么传输到我们这里的?本小节将讲述网页请求过程的分析,这样有助于我们后面遇到各种各样形形色色网站时能够得心应手地处理,也有了入手的基本准则。
那么我们在浏览器输入网址后,直到看到网页整体内容,这期间究竟发生了什么?
一个简单的例子
还是以百度搜索为例:在访问百度搜索时,浏览器会把这一次请求送到百度的服务器,由服务器接受到这个请求,然后加载出对应的数据,返回给我们的浏览器,然后进行显示。听起来好像是一些废话,但是这里有一个极为重要的细节:百度服务器返回给我们的不是直接显示的页面,而是我们上节所提到的页面源代码(由html,css,js组成),再由浏览器把页面源代码执行,最后把执行结果展示给用户。
具体过程如下图所示:
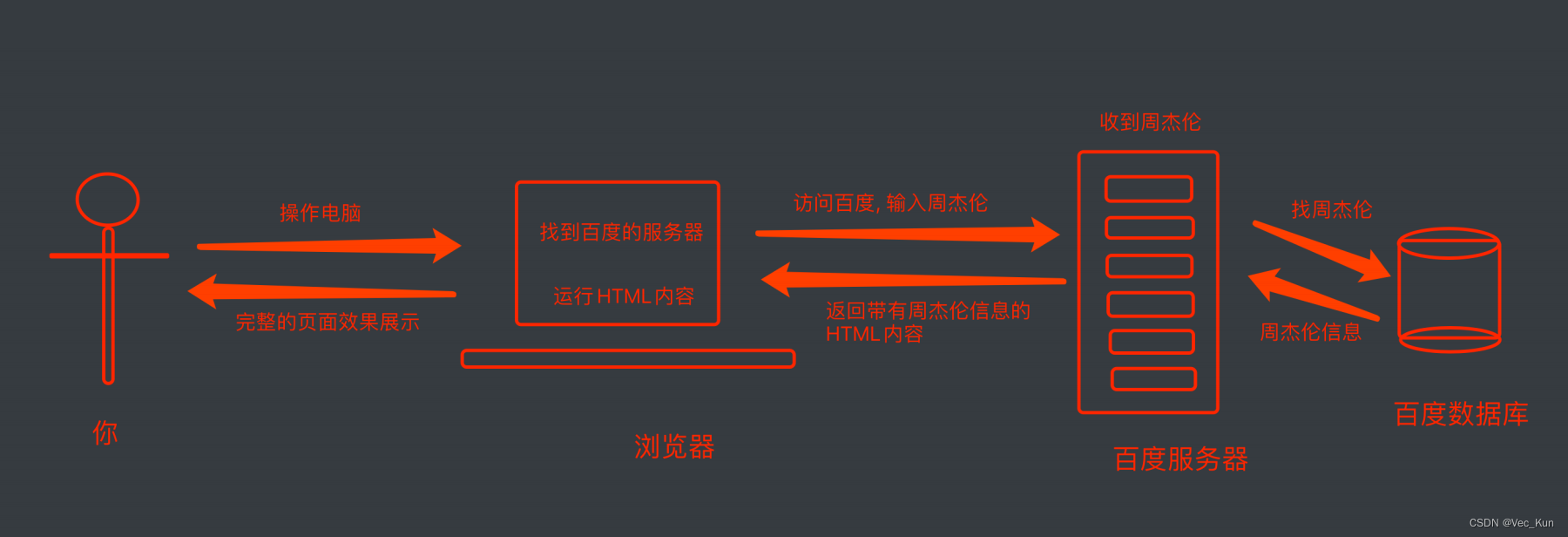
接下来就要介绍另一个重要的概念了。我们请求到的页面源代码包含所有数据吗?也就是说,我们当前页面显示的所有数据都在源代码中包含吗?这就要说到”页面渲染“过程了。
我们常见的页面渲染过程有两种
1. 服务器渲染
这个最容易理解,也是最直白最简单的。其含义就是我们在请求到服务器的时候,服务器会直接将数据全部写入html'中,我们的浏览器就能直接拿到带有数据的html内容(按F12打开浏览器调试工具)。比如:
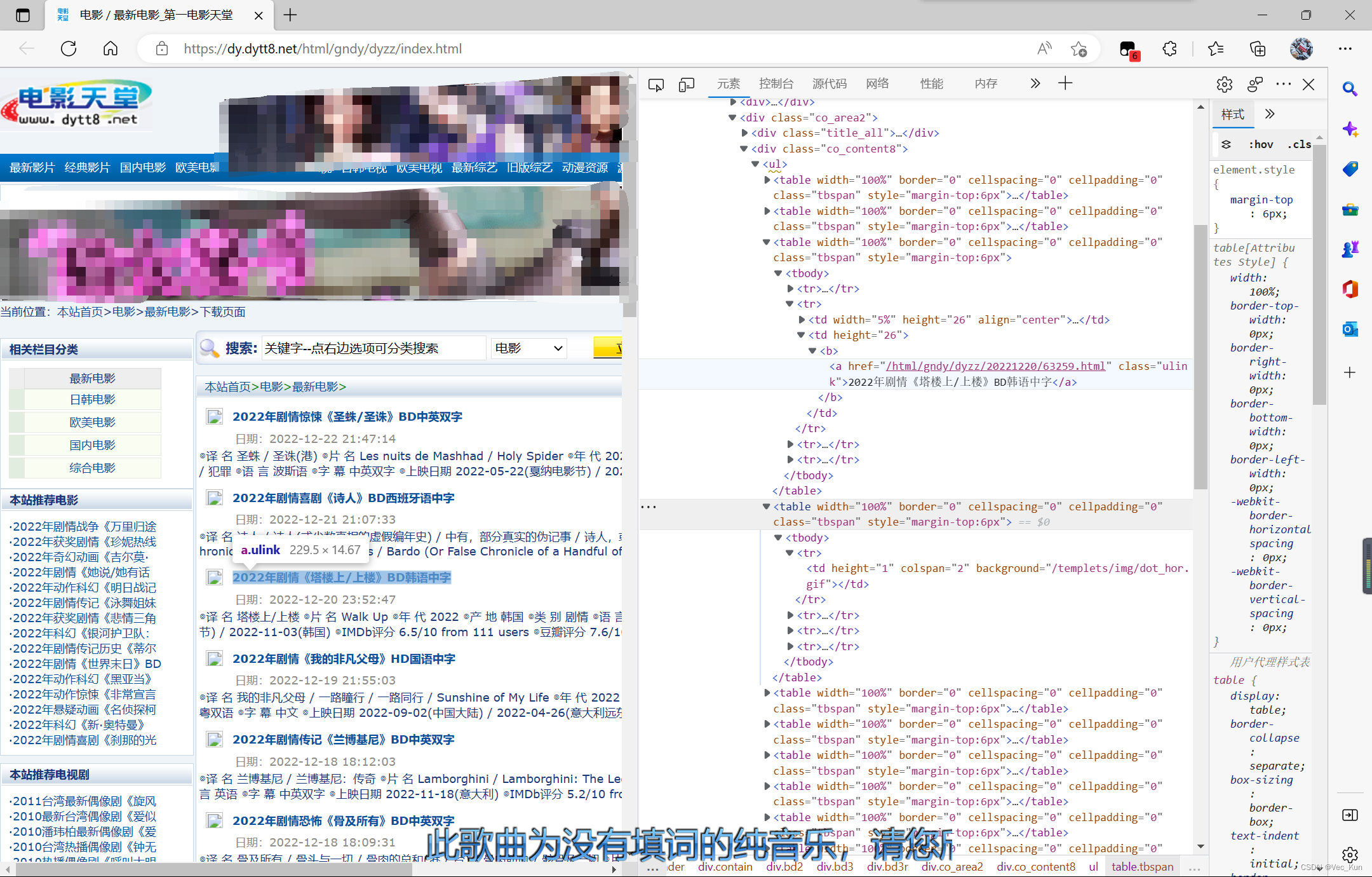
由于数据是直接写在html中的,所以我们能看到的数据都在页面源代码中有迹可循,这种网页一般也相对容易抓取到页面内容。
2. 前端JS渲染
这种就稍显麻烦了,这种机制一般是第一次请求服务器返回一堆HTML框架结构,然后再次请求到真正保存数据的服务器,再由这个服务器返回数据,最后在浏览器上对数据进行加载,如下图:

这样做的好处是网站服务器能够缓解压力,并且分工明确,方便维护。典型例子是JD:
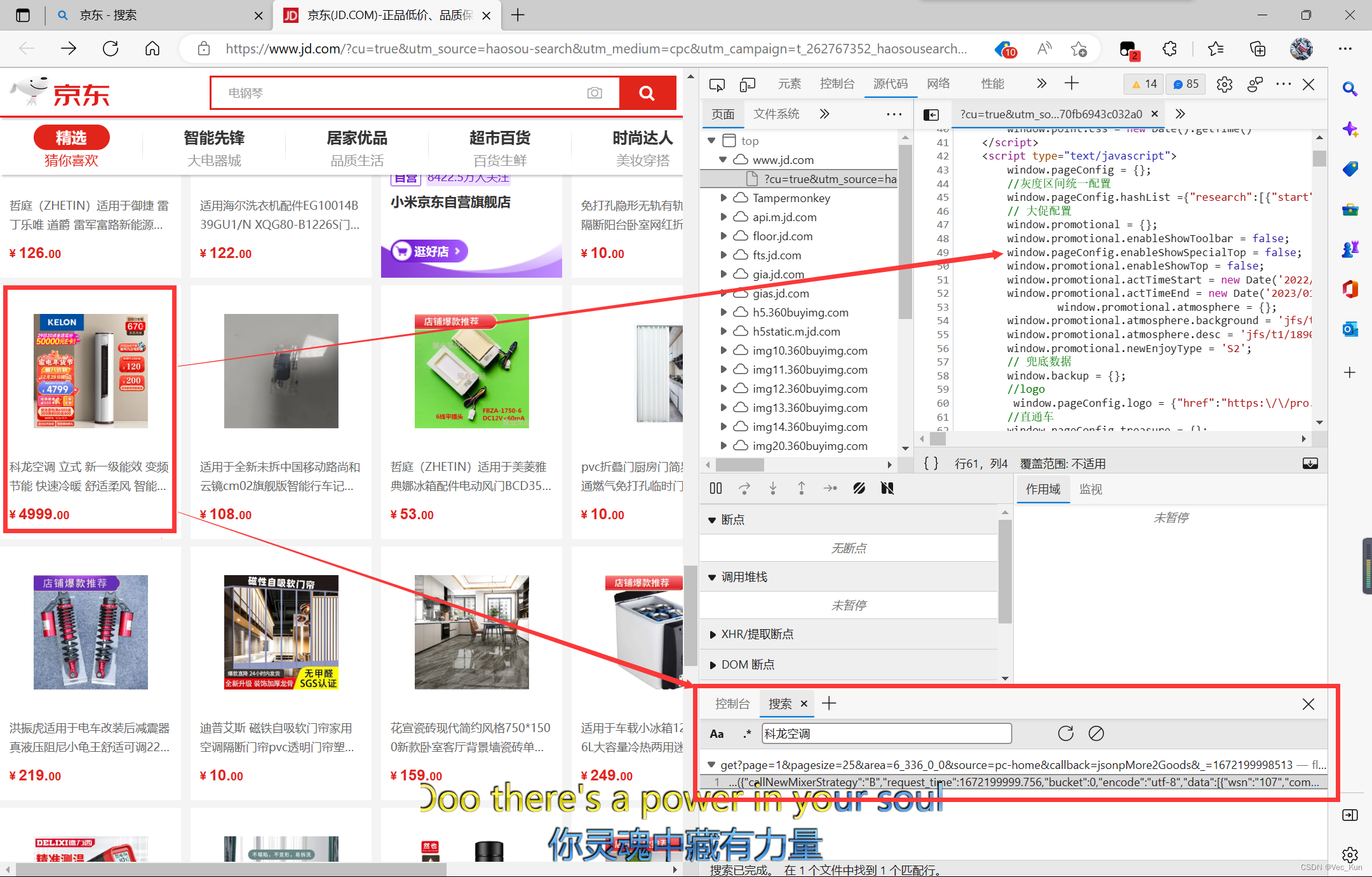
可以看到这件商品在源代码中是没有显示的,但是页面上却有此商品的显示,那么数据是何时加载进来的呢?通过搜索,我们找到一个json文件,说明数据是存放在其他文件中,并不在源代码中直接存在,这个文件是通过其他请求得来。双击打开显示如下:

其实,我们页面滚动的时候,JD就在加载数据了,要想看到这个过程,还是需要借助浏览器的调试工具(F12):

选择“网络”项 ,点击禁止按钮,可以清空当前网络活动的缓存,方便我们观察网站的下一步活动。
此时我们向下滚动,可以看到刚刚新请求到的文件:
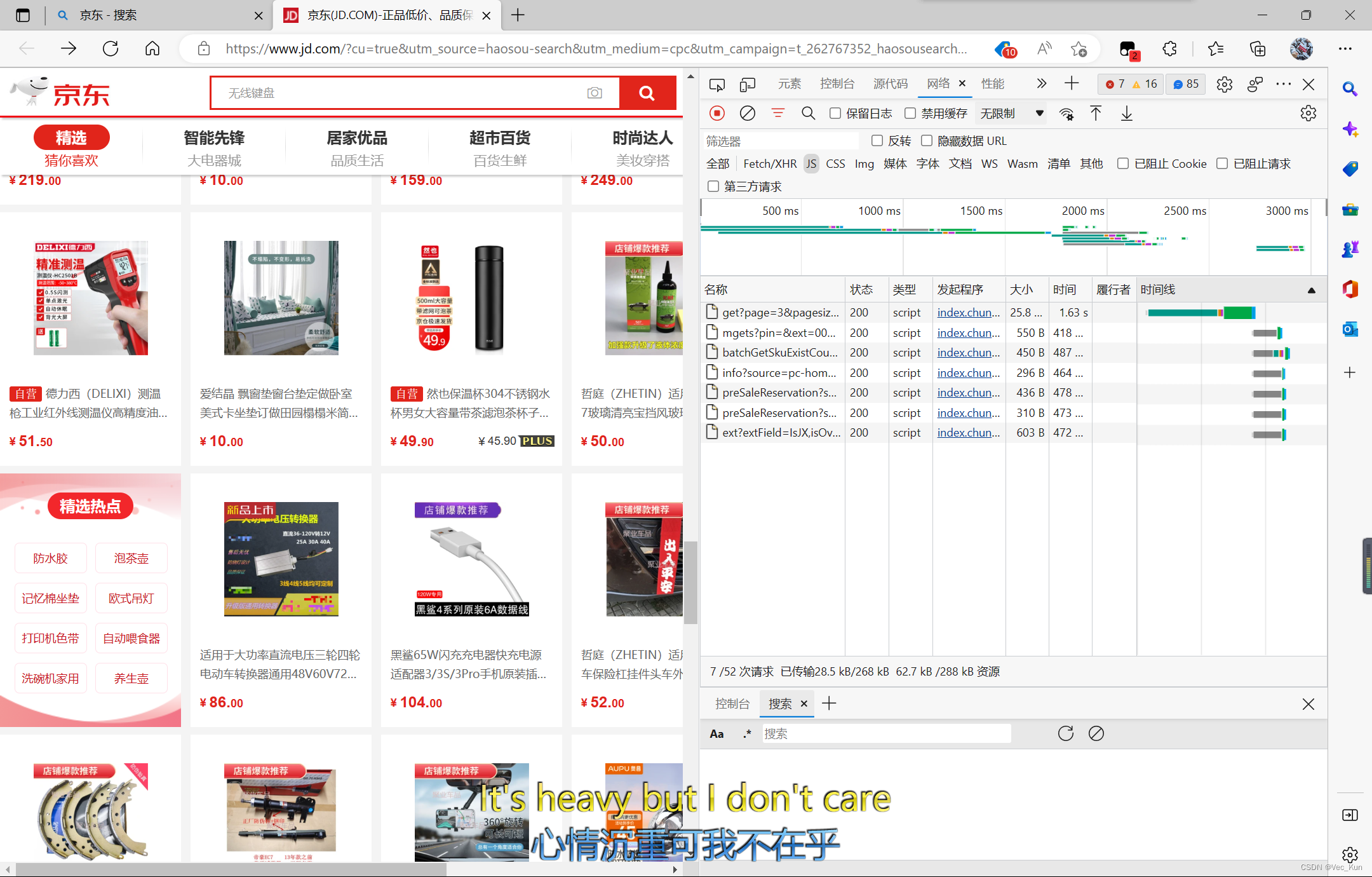
所以页面上看到的内容是后加载进来的,第一次请求的源代码只是这个网站的框架,没有内容。相信大家在网络加载缓慢的时候也遇到过这种情况,先加载出网页的框架,随后才加载出图片和其他内容,这就是多次请求的结果。
得出结论
说到这两种渲染方式,我只是想告诉各位,我们的数据不仅仅来自于页面源代码,更多时候会存放到另一个请求中,我们在爬取 这类数据的时候要多花心思找到目的请求,从而拿到想要的数据。
总结
# 1、服务器渲染:在服务器那边直接把数据和html整合在一起,一并返回给浏览器,在页面源代码中能看到数据(一次请求+反馈)
# 2、客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示,在页面源代码中不显示数据
# 客户端渲染情况下要获取数据,必须熟练使用浏览器抓包工具(检查/F12),找到对应请求数据的html文件
















 4013
4013










 全栈领域新星创作者
全栈领域新星创作者


































 到【灌水乐园】发言
到【灌水乐园】发言












m0_74217718: 学长 归结处好像写反了 应该是liming/x
haoyu1561: 呜呜大佬贴贴
2301_80657628: 我的意思是可不可以在登陆跟预定之间加一个步骤,使其人为的填写身份证跟验证码后,继续进行预定操作,现在的程序在登陆后会直接出错,没办法继续预定
2301_80657628: 麻烦问一下,现在必须要身份证跟验证码才能进行登录,那进行自动购票的时候是否可以自行提前登录,然后购买吗?还是说这个自动购票无法实现了
A lifetime of war: 学长,神!!!