Go语言的‘包’和‘文件’操作规则

 于 2023-07-19 13:42:45 发布
于 2023-07-19 13:42:45 发布
 阅读量377
阅读量377
 收藏
2
收藏
2


 点赞数
点赞数

Go语言的‘包’和‘文件’操作规则
-
Go语言工作空间:编译工具对源码目录有严格要求,每个工作空间 (workspace) 必须由bin、pkg、src三个目录组成。
-
src ---- 项目源码目录,里面每一个子目录,就是一个包,包内是Go语言的源码文件。
pkg ---- Go语言编译的.a 中间文件存放目录,可自动生成。
bin ---- Go语言编译可执行文件存放目录,可自动生成。 -
”包“用于支持模块化、封装、编译隔离和重用,相当于类库。一个包的源代码保存在一个或者多个以.go结尾的文件中,它所在目录名的尾部就是包的导入路径。
-
一个文件夹下面直接包含的文件只能归属一个包,同一个包的文件不能在多个文件夹下;同一文件夹下的第一个文件包名是bbb,那其他的也得是bbb。行话来说:同级别源文件的包的声明必须一致。
包名为
main的包是应用程序的入口包,这种包编译后会得到一个可执行文件(.exe),而编译不包含main包的源代码则不会得到可执行文件。 -
包的声明和所在的文件夹最好同名(也可以不一样)
-
main函数要放在mian包下,否则根本没法执行,和第4条呼应
Go语言“包”的访问规则
包可以让我们通过控制哪些名字是外部可见的来隐藏内部实现信息。标识符必须是对外可见的,即(public)。在Go语言中是通过标识符的首字母大/小写来控制标识符的对外可见(public)/不可见(private)的。在一个包内部只有首字母大写的标识符才是对外可见的。
// 演示如何在一个包中声明,由另一个包来调用
// 主函数
package main
import (
"fmt"
"test2/crm/first"
)
func main() {
fmt.Println("main函数的执行")
first.GetConn()
}
// 被调用
package first
import "fmt"
func GetConn() {
fmt.Println("开始执行", 111)
}
// 执行结果
[Running] go run "d:\gostudy\src\test2\crm\main\mian.go"
main函数的执行
开始执行 111
- 引用包时,包名是从 G O P A T H / s r c 后开始计算,使用 / 进行路径分隔, GOPATH/src后开始计算,使用/进行路径分隔, GOPATH/src后开始计算,使用/进行路径分隔,GOPATH已经在环境变量中设置好了
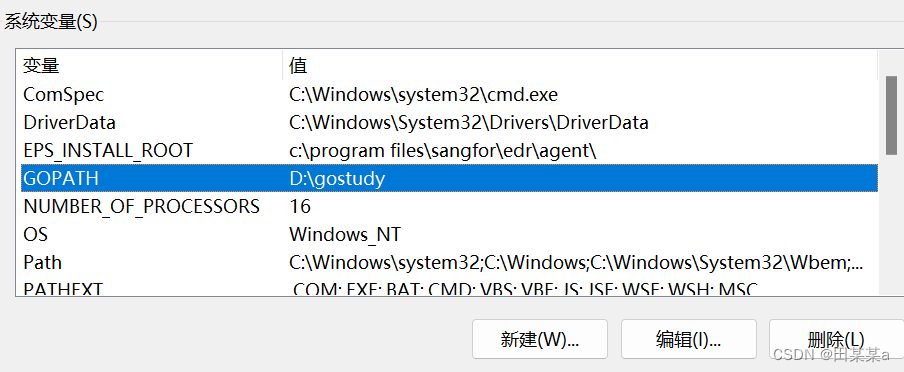
问题----->发现无法导入包

原因是GOPATH和自己设置的不一样?为什么?
编译器中显示的路径,说明GOPATH一直到 /src , 因此需要从/src之后开始导入
而我的路径是这样的:

因此报错信息中会在Project1之前出现一次/src。文件路径没设置好。估计只有初学者才会犯的低级错误吧。
- 包名和上级文件夹的名字不一致时(亦可以)
// 文件1
import (
"Project1/test1/cal"
"fmt"
)
func main() {
fmt.Println("main函数的执行")
// 函数前的定位用包名,即使import的文件名不一致也没有关系
kk.GetConn()
}
// 文件2
// 被调用
package kk
import "fmt"
func GetConn() {
fmt.Println("开始执行", 111)
}
// 最好是起个别名
// 文件1
import (
// 在这里
kk "Project1/test1/cal"
"fmt"
)
func main() {
fmt.Println("main函数的执行")
// 函数前的定位用包名,即使import的文件名不一致也没有关系
kk.GetConn()
}
函数的执行顺序
package main
import "fmt"
var num int = test()
func test() int {
fmt.Println("test函数执行")
return 10
}
func init() {
fmt.Println("先执行")
}
func main() {
fmt.Println("后执行")
}
匿名函数:我只用一次
发现:
-
匿名函数不用写函数名字
-
函数参数可以直接在结尾传递
package main
import "fmt"
// 匿名函数
func main() {
// 定义匿名函数: 定义的同时再调用
result := func(num1 int, num2 int) int {
return num1 + num2
}(10, 20)
fmt.Println(result)
}
闭包:
package main
import "fmt"
// 函数功能:求和
// 函数名字 getSum,参数为空
// getSum函数返回一个函数,该函数的参数是int类型,返回值也是int类型
func getSum() func(int) int {
var sum int = 0
// func(num int):getSum函数的参数
// int:函数的返回值
return func(num int) int {
sum = sum + num
return sum
}
}
// 非闭包
func getSum2(num int) int {
var sum int = 0
sum += num
return sum
}
// 闭包:返回的匿名函数+匿名函数以外的变量num
func main() {
f := getSum()
// 为啥匿名函数的那个变量会一直保持?因为num本身就是个匿名函数内部的临时变量啊,作用域为什么会延伸到函数外?因为匿名函数
// 怎么才能写出闭包?用匿名函数
// 优点:
// 缺点:内存使用量大
fmt.Println(f(1)) // 1
fmt.Println(f(2)) // 3
fmt.Println(f(3)) // 6
fmt.Println(f(4)) // 10
fmt.Println("---------------------------------")
fmt.Println(getSum2(1)) // 1
fmt.Println(getSum2(2)) // 2
fmt.Println(getSum2(3)) // 3
}
问题:
1. 为什么会实现值不变(闭包的工作流程)
2. 怎么使用
```go
f(4)) // 10
fmt.Println("---------------------------------")
fmt.Println(getSum2(1)) // 1
fmt.Println(getSum2(2)) // 2
fmt.Println(getSum2(3)) // 3
}
问题:
1. 为什么会实现值不变(闭包的工作流程)
2. 怎么使用
闭包复习
package main
import "fmt"
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5}) // 1.传参
fmt.Println("等待一会") // 6.输出
fmt.Println("结果:", sumFunc()) // 7.调用函数sumFunc()
}
func lazySum(arr []int) func() int { // 2.接入参数
fmt.Println("先获取函数,不求结果") // 3.打印
var sum = func() int { // 4.定义变量sum
fmt.Println("求结果...") // 8.打印
result := 0
for _, v := range arr { // 9.进入循环
result = result + v
}
return result // 10.返回result
}
return sum // 5.返回变量sum,是一个函数,由sumFunc接收
}
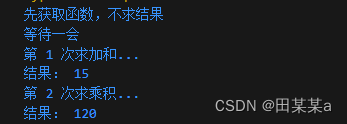
package main
import "fmt"
func main() {
sumFunc, productSFunc := lazyCalculate([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
fmt.Println("结果:", productSFunc())
}
func lazyCalculate(arr []int) (func() int, func() int) {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
count++
fmt.Println("第", count, "次求加和...")
result := 0
for _, v := range arr {
result = result + v
}
return result
}
var product = func() int {
count++
fmt.Println("第", count, "次求乘积...")
result := 1
for _, v := range arr {
result = result * v
}
return result
}
return sum, product
}
执行结果:
2.1 好处
纯函数没有状态,而闭包则是让函数轻松拥有了状态。但是凡事都有两面性,一旦拥有状态,多次调用,可能会出现不一样的结果,就像是前面测试的 case 中一样。那么问题来了:
Q:如果不支持闭包的话,我们想要函数拥有状态,需要怎么做呢?
A: 需要使用全局变量,让所有函数共享同一份变量。
但是我们都知道全局变量有以下的一些特点(在不同的场景,优点会变成缺点):
常驻于内存之中,只要程序不停会一直在内存中。
污染全局,大家都可以访问,共享的同时不知道谁会改这个变量。
闭包可以一定程度优化这个问题:
不需要使用全局变量,外部函数局部变量在闭包的时候会创建一份,生命周期与函数生命周期一致,闭包函数不再被引用的时候,就可以回收了。
闭包暴露的局部变量,外界无法直接访问,只能通过函数操作,可以避免滥用。
2.2 坏处
函数拥有状态,如果处理不当,会导致闭包中的变量被误改,但这是编码者应该考虑的问题,是预期中的场景。
闭包中如果随意创建,引用被持有,则无法销毁,同时闭包内的局部变量也无法销毁,过度使用闭包会占有更多的内存,导致性能下降。一般而言,能共享一份闭包(共享闭包局部变量数据),不需要多次创建闭包函数,是比较优雅的方式。
defer关键字
在Go语言中,程序遇到defer语句,不会立即执行defer后的语句,而是将这些语句压入一个栈中,然后继续执行函数后面的语句。
啥时候用呢?
比如想关闭某个使用的资源,在使用的时候直接随手defer,因为defer有延迟执行机制(函数执行完毕再执行defer压入栈的语句),所以用完随手写了关闭,省事
package main
import "fmt"
func main() {
fmt.Println(add(30, 60))
}
func add(num1 int, num2 int) int {
// 这两句啥时候执行?
// 既然压入栈了,那就讲究一个先入后出,先2后1
//
defer fmt.Println("num1 = ", num1) // 1
defer fmt.Println("num2 = ", num2) // 2
var sum int = num1 + num2
fmt.Println("sum = ", sum)
return sum
}
// 输出
// sum = 90
// num2 = 60
// num1 = 30
// 90
把两个语句压入栈的同时,其相应的值也会压入(拷贝)到栈里
package main
import "fmt"
func main() {
fmt.Println(add(30, 60))
}
func add(num1 int, num2 int) int {
// 这两句啥时候执行?
// 既然压入栈了,那就讲究一个先入后出,先2后1
defer fmt.Println("num1 = ", num1) // 1
defer fmt.Println("num2 = ", num2) // 2
// 第二种情况
num1 += 90 // 120
num2 += 90 // 150
var sum int = num1 + num2 // 270
fmt.Println("sum = ", sum)
return sum
}
// 输出
// sum = 270
// num2 = 60
// num1 = 30
// 270
插入一个:for-range:键值循环
Go的字符串
[]rune()
rune 类型是 Go 语言的一种特殊数字类型,定义是type rune = int32;官方对它的解释是:rune 是类型 int32 的别名,在所有方面都等价于它,用来区分字符值跟整数值。使用单引号定义 ,返回采用 UTF-8 编码的 Unicode 码点(就是能转换)。Go 语言通过 rune 处理中文,支持国际化多语言。
如我们要指定截取字符串的长度,因为golang的string底层就是一个byte数组,我们直接取数组的前N个即可完成这个需求
//要求截取前4个字符串,最后是"xs25"
var str = "xs25.cn"
fmt.Println(str[:4])
//运行后的结果:xs25
但这个如果在字符串中存在中文会不会有问题呢,我们以“小手25是什么”
//要求截取前4个字符串,最后是"小手25"
var str = "小手25是什么"
fmt.Println(str[:4])
//结果: 小�
为什么会出现乱码呢?golang的string底层是一个byte数组实现,中文字符串在unicode下占2个字节,在utf-8下占3个字节。
var str = "小手25是什么"
fmt.Println(len(str)) //17
fmt.Println(str[:8]) //”小手25“共占8个字节
//结果:小手25
这时可以使用 []rune(str)这样的方式转换成一个切片,转换后我们取切片的前几个不就可以了吗。
var str = "小手25是什么"
k := []rune(str)
fmt.Println(len(k)) //17
fmt.Println(string(k[:4]))
情景1:返回子串第一次出现的索引
k := strings.Index("agolang", "go")
fmt.Println(k)
// 返回索引值,如果没有返回-1
情景2:替换字符串中的指定字符
// 把goangjavagogo中的所有"go",替换为"golang",-1表示全部替换,1表示替换1个,2表示2个
str1 := strings.Replace("goangjavagogo","go","golang",-1)
Go的日期和时间(重点)
func main() {
now := time.Now()
// Now()返回值是一个结构体,类型是:
fmt.Printf("输出为%v~~~,\n对应的类型为%T\n", now, now)
fmt.Println(now)
}
// 输出
// 输出为2023-06-30 11:12:02.21199 +0800 CST m=+0.002571701~~~,
// 对应的类型为time.Time
不要后面的一串
package main
import (
"fmt"
"time"
)
func main() {
now := time.Now()
// Now()返回值是一个结构体,类型是:
fmt.Printf("输出为%v~~~,\n对应的类型为%T\n", now, now)
fmt.Println("年, %v ", now.Year())
fmt.Println("月, %v ", int(now.Month()))
fmt.Println("日, %v ", now.Day())
fmt.Println("时, %v ", now.Hour())
fmt.Println("分, %v ", now.Minute())
fmt.Println("秒, %v ", now.Second())
}
日期的格式化
fmt.Printf("当前的年月日:%d:%d:%d 时分秒:%d:%d:%d", now.Year(), now.Month(), now.Day(),now.Hour(), now.Minute(), now.Second())
// --------------------------------------------
当前的年月日:2023:6:30 时分秒:11:22:53
// 接收上述字符串
// Sprintf不直接输出到终端,而是返回该字符串
str := fmt.Sprintf("当前的年月日:%d:%d:%d 时分秒:%d:%d:%d", now.Year(), now.Month(), now.Day(),now.Hour(), now.Minute(), now.Second())
fmt.Printf(str)
GoLang神奇的日期
// 标准化输出当前时间
datastr := now.Format("2006/01/02 15:04:05")
// 2023/06/30 13:14:36
内置函数(自带的)
func new(Type) *Type
内建函数new分配内存。其第一个实参为类型,而非值。其返回值为指向该类型的新分配的零值的指针。(对应的类型的指针)
num := new(int)
fmt.Printf("num的类型:%T ,num的值是:%v ,num的地址:%v, num指针指向的值是:%v",
num, num, &num, num)
}
//num的类型:*int,num的值是(num这个变量承载的值的地址):0xc000018098,(num变量自身的地址):0xc00000a028,num指针指向的值是(也是num这个变量承载的值的地址):0xc000018098
异常处理机制(提高程序的鲁棒性)
发现程序中出现panic,程序被中断,无法继续执行

1. 错误处理/捕获机制
defer + recover
func recover
func recover() interface{}
内建函数recover允许程序管理恐慌过程中的Go程。在defer的函数中,执行recover调用会取回传至panic调用的错误值,恢复正常执行,停止恐慌过程。若recover在defer的函数之外被调用,它将不会停止恐慌过程序列。在此情况下,或当该Go程不在恐慌过程中时,或提供给panic的实参为nil时,recover就会返回nil(程序如果正常的话)。
示例
package main
import "fmt"
func main() {
test()
fmt.Println("正常")
fmt.Println("继续执行")
}
func test() {
// 捕获机制,利用defer+recover
defer func() { // defer后加上匿名函数的调用
// 调用recover内置函数
err := recover()
// 如果没有错误,返回值为零值;如果不返回零值,说明有错误
if err != nil {
fmt.Println("错误已捕获")
// 看看啥错误
fmt.Println("err是", err)
}
}()
num1 := 10
num2 := 0
result := num1 / num2
fmt.Println(result)
}
// 输出
错误已捕获
err是 runtime error: integer divide by zero
正常
继续执行
2. Go语言的自定义错误(啥意思?)
自己提前预判错误,然后给出解决方案
需要调用error下的New函数
func New
func New(text string) error // 会返回一个error
使用字符串创建一个错误,请类比fmt包的Errorf方法,差不多可以认为是New(fmt.Sprintf(…))。
package main
import (
"errors"
"fmt"
)
func main() {
err := test2()
if err != nil {
fmt.Println("自定义错误:", err)
}
fmt.Println("正常")
fmt.Println("继续执行")
}
func test2() (err error) {
num1 := 10
num2 := 0
if num2 == 0 {
// errors下的New接受一个自定义的字符串,指示错误类型,然后返回一个error类型
return errors.New("除数不为空")
} else {
result := num1 / num2
fmt.Println(result)
return nil
}
}
-
出现错误,没必要继续执行了
func panic
func panic(v interface{}) // 传入一个具体的错误
内建函数panic停止当前Go程的正常执行。当函数F调用panic时,F的正常执行就会立刻停止。F中defer的所有函数先入后出执行后,F返回给其调用者G。G如同F一样行动,层层返回,直到该Go程中所有函数都按相反的顺序停止执行。之后,程序被终止,而错误情况会被报告,包括引发该恐慌的实参值,此终止序列称为恐慌过程。
func main() {
err := test2()
if err != nil {
fmt.Println("自定义错误:", err)
panic(err) // 传入后,下面的都不会执行了,开始报错
}
fmt.Println("正常")
fmt.Println("继续执行")
}















 829
829










 暂无认证
暂无认证

















 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 非常祝贺您写了第9篇博客!标题中的内容也非常吸引人,特别是SQL的分组和单行查询。这些内容对于学习MySQL基础非常有帮助。您的努力和持续创作精神值得称赞。 不过,我想谦虚地给出下一步的创作建议。既然您已经涉及到了SQL的分组和单行查询,或许您可以考虑进一步拓展主题,例如介绍JOIN操作或者更高级的查询技巧。这样可以帮助读者更全面地理解和应用MySQL。 再次恭喜您的成果,期待您未来更多精彩的博客!
CSDN-Ada助手: 恭喜您写完了第10篇博客!标题“MySQL基础学习4-连接”看起来非常有意思,我很期待阅读您的最新一篇博文。在连接这个主题上,您是否考虑过添加一些实际案例或者示例代码来帮助读者更好地理解连接的概念呢?这样能够让读者更加深入地掌握MySQL的连接功能。再次恭喜您的持续创作,我期待着您下一篇博客的发布!
CSDN-Ada助手: 恭喜您写完了第11篇博客!标题看起来非常有趣,我立刻就想去了解多表连接与子查询了。您的持续创作真是令人鼓舞,我真心希望您能继续分享您的知识和经验。作为下一步的创作建议,或许您可以考虑深入研究一些高级的MySQL技巧或者分享一些实际案例,这样能更好地帮助读者应用所学。再次恭喜您,期待您的下一篇博客!
CSDN-Ada助手: 恭喜您写了第12篇博客!标题为“MySQL基础学习6-表的操作”的文章内容非常有深度和实用性。通过您的分享,我对MySQL表的操作有了更清晰的理解。希望您能继续保持创作的热情,为我们带来更多关于MySQL的精彩内容。 同时,我想给出一些建议,希望对您的下一步创作有所帮助。在探讨表的操作的同时,或许可以结合实例和案例,让读者更好地理解如何应用这些操作来解决实际问题。此外,您还可以考虑分享一些高级的表操作技巧或者与其他数据库系统的对比分析,以丰富读者的知识和视野。期待您的下一篇文章!