CatBoost快速入门

 最新推荐文章于 2023-01-24 22:53:04 发布
最新推荐文章于 2023-01-24 22:53:04 发布
 阅读量3.4k
阅读量3.4k
 收藏
25
收藏
25


 点赞数
1
点赞数
1

文章目录
- 备注
- 推荐阅读
- 简介
- 安装
- 初试
- 可视化
- 决策树
- 特征重要性
- 最优模型
- 调用GPU
- 参考文献
备注
该库貌似仍不稳定,我在继续训练的时候找到一个BUG Can Not Training continuation(2020.2.27 版本0.21),现在已修复了
推荐阅读
MNIST & CatBoost保存模型并预测
快速掌握CatBoost基本用法
简介
CatBoost是一款高性能机器学习开源库,基于GBDT,由俄罗斯搜索巨头Yandex在2017年开源。
那么CatBoost与其他Boosting算法如LightGBM和XGBoost相比如何呢?
在质量上,无论是fine-tuned后还是默认情况下,CatBoost的loss优于其他三个框架。
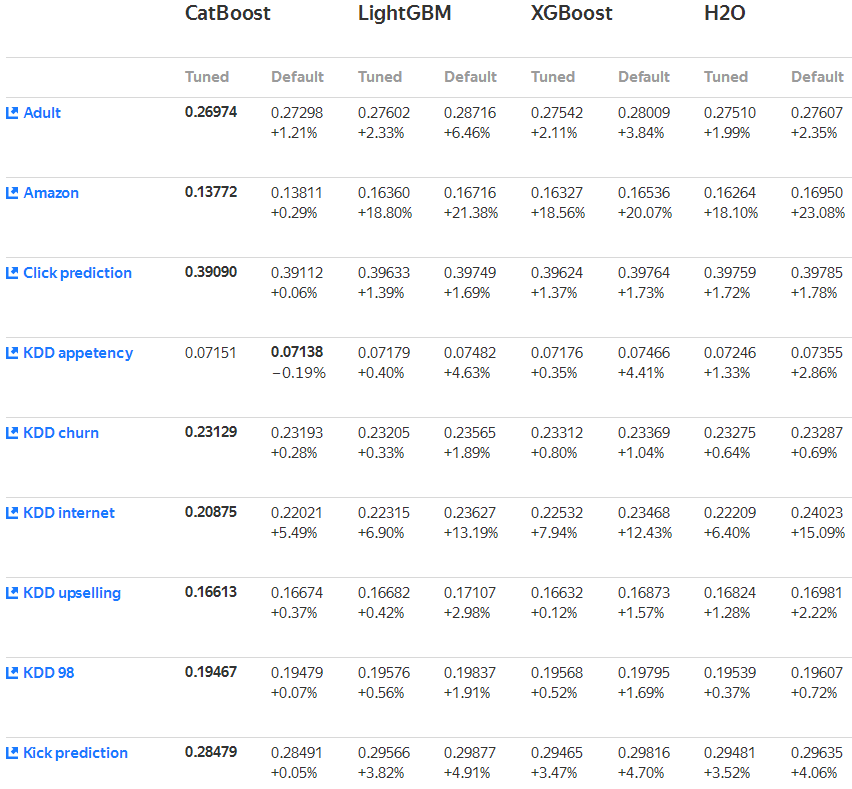
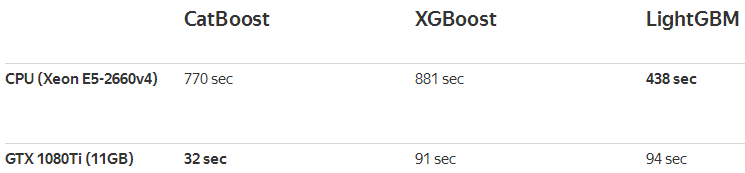
在速度上,CatBoost在Epsilon和Higgs数据集上与对手进行了比较,在GPU训练下完胜对手,在CPU训练下与LightGBM平分秋色。
Epsilon数据集(二分类2001个特征)
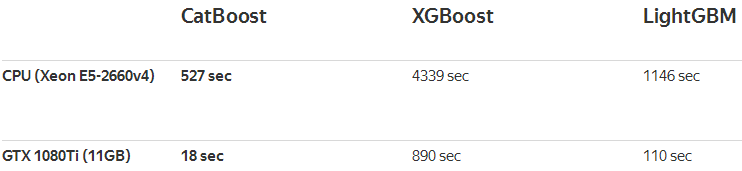
Higgs数据集(二分类29个特征)
CatBoost特点有:
- 免调参高质量
- 支持类别特征
- 快速和可用GPU
- 提高准确性
- 快速预测
更多对比参见 Battle of the Boosting Algos: LGB, XGB, Catboost,建议自己运行一遍,本人运行与原文有出入—— XGBoost、LightGBM、Catboost对比
安装
GPU开箱即用,不用额外安装其他
pip install catboost
Jupyter可视化配置
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension
初试
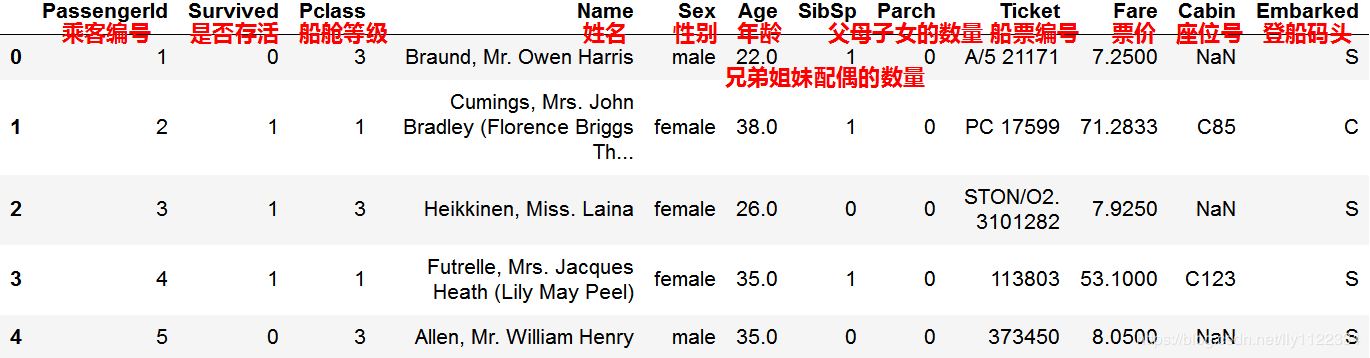
CatBoost内置数据集 Titanic,该数据集为二分类任务。
导入必要的包
from catboost.datasets import titanic
from catboost import CatBoostClassifier, Pool
from sklearn.model_selection import train_test_split
读取数据集
# 数据集
titanic_train, titanic_test = titanic()
titanic_train.head(10)
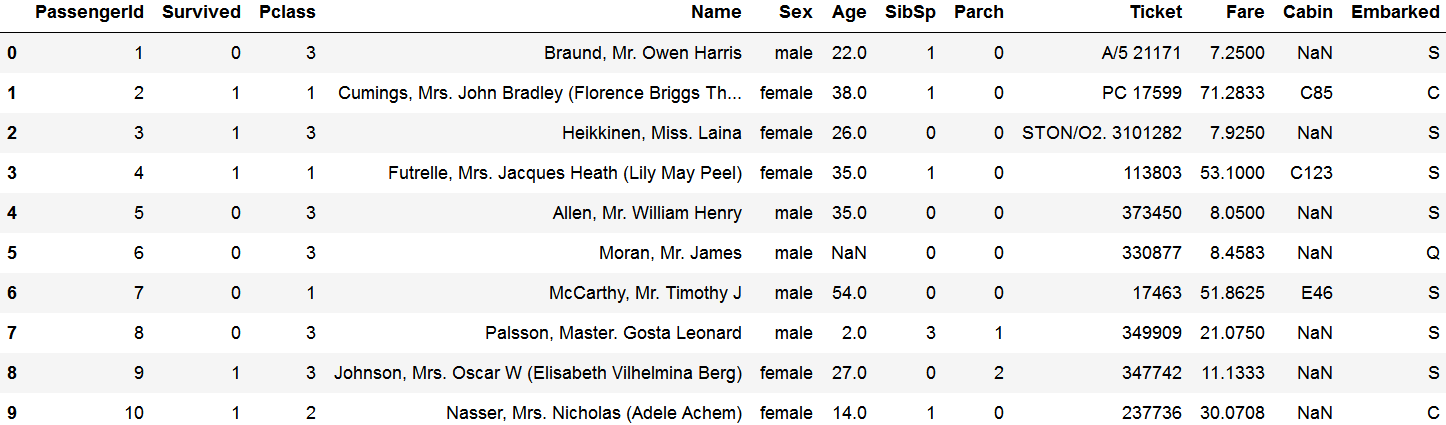
有数据为空NaN,例如乘客编号为6的年龄。
有数据是离散值,例如姓名和船票编号。
认为对模型训练作用性不大,去掉。
remove = ['PassengerId', 'Name', 'Ticket', 'Cabin']
X = titanic_train.drop(remove, axis=1) # 去掉无关信息
X = X.dropna(how='any', axis='rows') # 去掉空值
y = X.pop('Survived') # 标签
X.head()
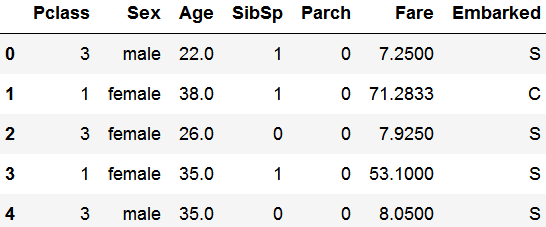
结果如上,其中船舱等级、性别和登船码头(下标为0,1,6)显然为类别特征,而恰好CatBoost支持类别特征训练。
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
创建Pool对象,这是CatBoost自带的类,便于CatBoost库进行处理。
当然,CatBoost实现了sklearn的接口,直接使用pd.DataFrame类型的X_train, X_test, y_train, y_test训练也行。
# 定义池(CatBoost最快的处理方式)
cat_features = [0, 1, 6] # 分类特征
train_pool = Pool(X_train, y_train, cat_features=cat_features)
test_pool = Pool(X_test, y_test, cat_features=cat_features)
定义CatBoost分类模型
# 定义模型
model = CatBoostClassifier()
训练,参数含义分别是:train_pool训练数据,eval_set验证集,plot可视化,silent不输出训练过程,use_best_model使用最优模型
# 训练
model.fit(train_pool, eval_set=test_pool, plot=True, silent=True, use_best_model=True) #可视化,不输出过程,最优模型
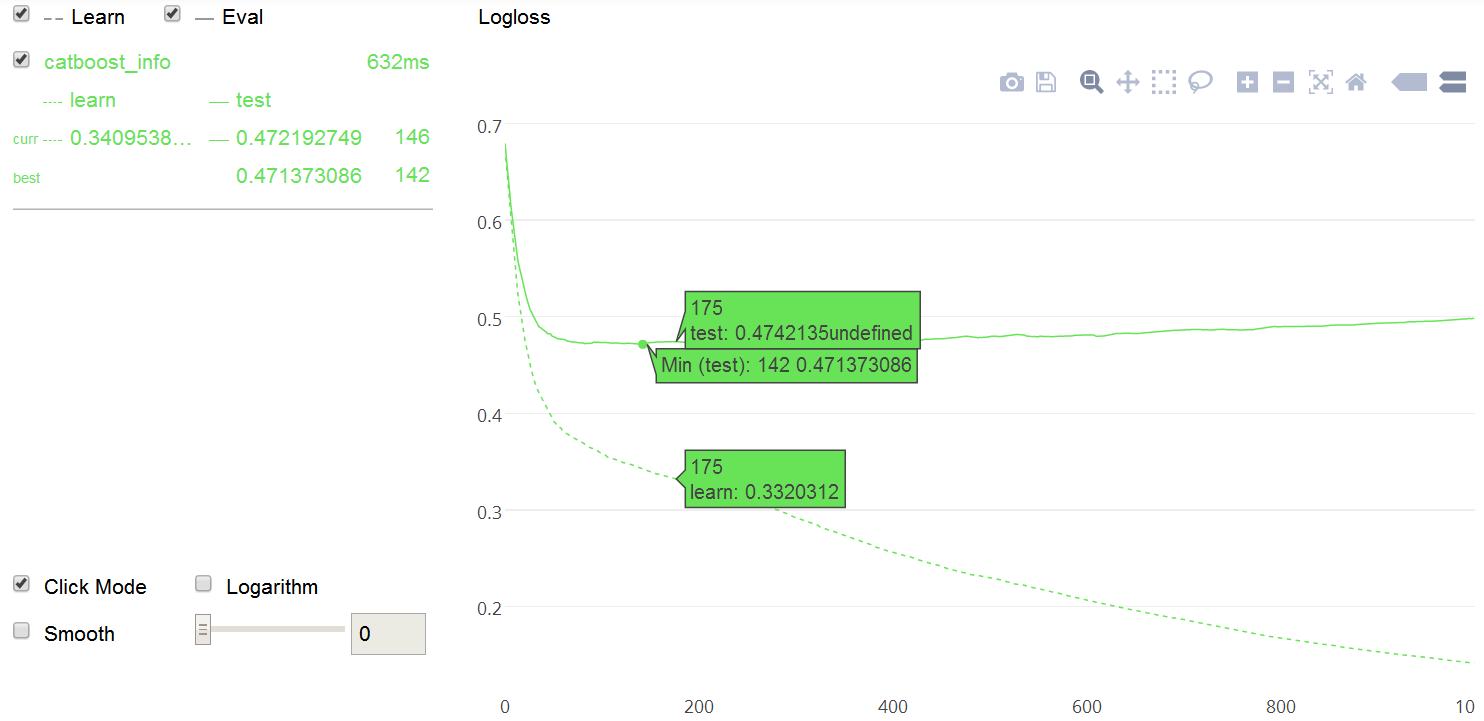
查看最优结果和准确率
model.get_best_score() # 最优loss
{'learn': {'Logloss': 0.14129628504561498},
'validation': {'Logloss': 0.471373085990394}}
model.score(test_pool) #准确率
0.8111888111888111
最后保存模型
model.save_model('titanic.model') # 保存模型
加载模型
del model
model = CatBoostClassifier()
model.load_model('titanic.model')
查看测试集数据
print(X_test[:10])
print(y_test[:10])
Pclass Sex Age SibSp Parch Fare Embarked
641 1 female 24.0 0 0 69.3000 C
496 1 female 54.0 1 0 78.2667 C
262 1 male 52.0 1 1 79.6500 S
311 1 female 18.0 2 2 262.3750 C
551 2 male 27.0 0 0 26.0000 S
550 1 male 17.0 0 2 110.8833 C
279 3 female 35.0 1 1 20.2500 S
268 1 female 58.0 0 1 153.4625 S
110 1 male 47.0 0 0 52.0000 S
554 3 female 22.0 0 0 7.7750 S
641 1
496 1
262 0
311 1
551 0
550 1
279 1
268 1
110 0
554 1
Name: Survived, dtype: int64
使用模型进行预测
model.predict(X_test[:10]) #预测
可以看到前5个都对了,后5个错得有点多
array([1, 1, 0, 1, 0, 0, 0, 1, 0, 0], dtype=int64)
使用模型进行概率预测
model.predict_proba(X_test[:10]) #预测概率
array([[0.02731782, 0.97268218],
[0.03240048, 0.96759952],
[0.63710499, 0.36289501],
[0.03272136, 0.96727864],
[0.80136214, 0.19863786],
[0.64224485, 0.35775515],
[0.64860225, 0.35139775],
[0.06276485, 0.93723515],
[0.64481127, 0.35518873],
[0.58364375, 0.41635625]])
继续训练
new_model = CatBoostClassifier()
new_model.fit(test_pool, plot=True, silent=True, init_model='titanic.model') # 继续训练
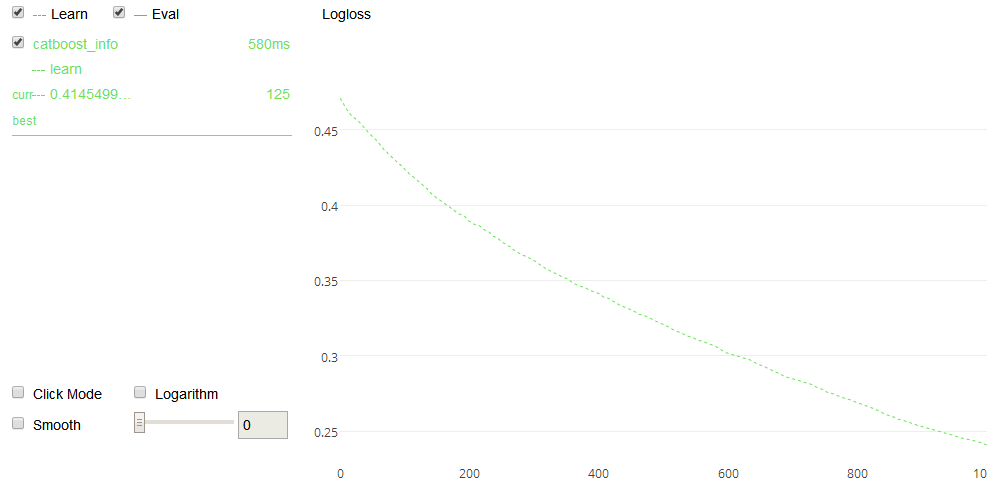
可视化
fit()时加入参数plot=True
model.fit(X_train, y_train, plot=True)
决策树
调用 plot_tree(),tree_idx为树的索引
model.plot_tree(tree_idx=0, pool=test_pool)
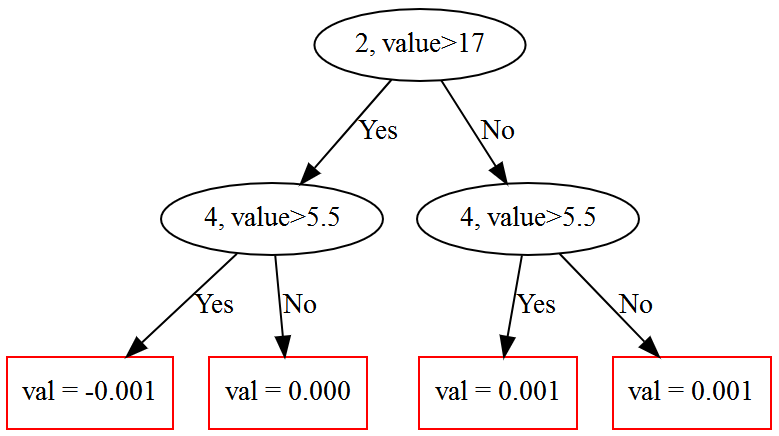
特征重要性
调用模型属性model.feature_importances_
for i,j in zip(X.columns, model.feature_importances_):
print('{}: {:.2f}%'.format(i,j))
Pclass: 18.62%
Sex: 46.79%
Age: 12.47%
SibSp: 4.68%
Parch: 2.16%
Fare: 10.65%
Embarked: 4.63%
%matplotlib inline
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def feature_importances(df, model):
max_num_features=10
feature_importances = pd.DataFrame(columns = ['feature', 'importance'])
feature_importances['feature'] = df.columns
feature_importances['importance'] = model.feature_importances_
feature_importances.sort_values(by='importance', ascending=False, inplace=True)
feature_importances = feature_importances[:max_num_features]
plt.figure(figsize=(12, 6));
sns.barplot(x="importance", y="feature", data=feature_importances);
plt.title('CatBoost features importance');
feature_importances(X, model)
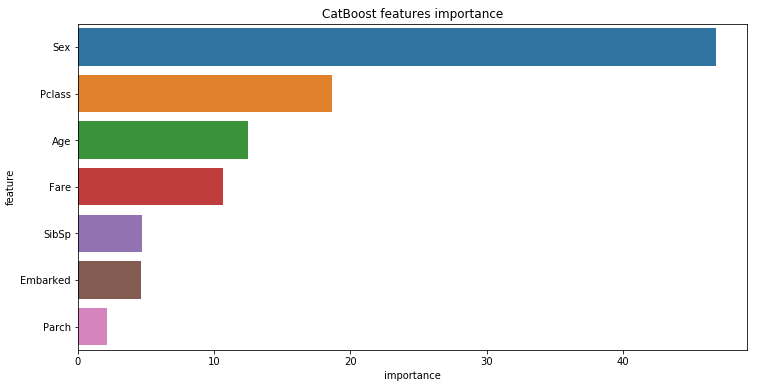
看来最决定生死的前三个因素是性别、船舱等级和年龄。
最优模型
fit()时加入参数use_best_model=True
model.fit(X_train, y_train, use_best_model=True)
调用GPU
定义模型时加入参数task_type="GPU"
model = CatBoostClassifier(task_type="GPU")
model.fit(X_train, y_train)
如果需要GPU支持,系统编译器必须与CUDA Toolkit兼容。
若报错请自行编译 CatBoost Build from source on Windows
参考文献
- CatBoost - open-source gradient boosting library
- Quick start - CatBoost. Documentation
- CatBoost tutorials
- 机器学习算法之Catboost
- MNIST & Catboost保存模型并预测
















 6187
6187











 Python领域优质创作者
Python领域优质创作者




























 到【灌水乐园】发言
到【灌水乐园】发言












nobut: 哥们你好,请问找到类似代码没
九度微凉: 博主你好,我encode运行成功,但decode始终有问题,问题是Secret bits: [1. 0. 0. 0. 0. 0. 1. 0. 0. 1. 0. 1. 1. 1. 1. 0. 0. 1. 0. 1. 0. 0. 0. 0. 1. 1. 0. 0. 1. 0. 1. 0. 1. 1. 0. 1. 0. 1. 0. 1. 0. 1. 0. 1. 0. 0. 1. 0. 0. 1. 0. 1. 1. 0. 1. 0. 0. 1. 0. 1. 1. 0. 0. 1. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 1. 0. 1. 0. 1. 0. 0. 0.] Packet binary: 100000100101111001010000110010101101010101010010010110100101100100000111000100010001000110101000 Data: bytearray(b'\x82^P\xca\xd5RZ'), ECC: bytearray(b'Y\x07\x11\x11\xa8') Bitflips: -1,是哪里的问题呢
2401_83177883: 靴靴大佬
2401_84606608: 老板在官网上没看到下载位置,能出个详细教程吗
2401_84606608: 老板,我的 mx 播放器 版本号,是 1.75.5(armv8 neon)在使用时候,音频不支持 eac3,网上查找需要下载一个 MX_FFmpeg,但是我在官网没找到下载位置,求给个下载位置