python爬虫案例(F12网页解析)
最新推荐文章于 2024-03-07 17:00:27 发布

前端交互仔
 最新推荐文章于 2024-03-07 17:00:27 发布
最新推荐文章于 2024-03-07 17:00:27 发布
 阅读量2.6k
阅读量2.6k
 收藏
9
收藏
9
 点赞数
3
点赞数
3
最新推荐文章于 2024-03-07 17:00:27 发布
阅读量2.6k
收藏
9

 点赞数
3
点赞数
3









http://www.voidcn.com/article/p-hqgyidlc-bpz.html




user-Agent表示用户代理

cookie是服务器为了标识每一个客户端保存在本地的内容。


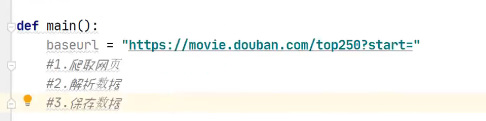
 就是定义下我们的程序入口的位置
就是定义下我们的程序入口的位置




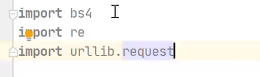
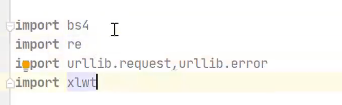
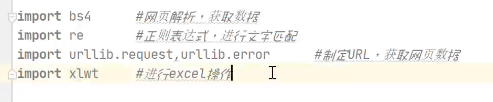
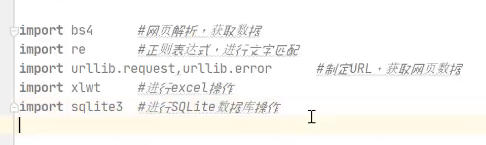
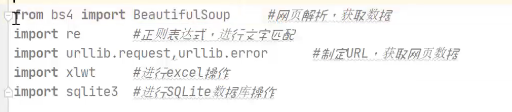
直接用urllib获取数据,urllib里面已经整合了urllib2了















 550
550










 暂无认证
暂无认证






























 到【灌水乐园】发言
到【灌水乐园】发言










回眸一笑吟离歌: 安全组 对外起到拦截过滤,还能同组下节点实现组内互通。 也够用
前端交互仔: 看我主页方式
昆兰274: 您好,问一下这个网页的字体如何修改?就比如我想改成落下来的是中文、英文或者其他国家的字体应该修改哪一块?
2301_80449080: 👀不懂,可能是我了解的太少了
usp1994: 画一个姑娘陪着我