NLP学习(二)—中文分词技术

 最新推荐文章于 2022-08-17 23:52:55 发布
最新推荐文章于 2022-08-17 23:52:55 发布
 阅读量1k
阅读量1k
 收藏
7
收藏
7


 点赞数
点赞数

本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
这篇内容主要是讲解的中文分词,词是一个完整语义的最小单位。分词技术是词性标注、命名实体识别、关键词提取等技术的基础。本篇博文会主要介绍基于规则的分词、基于统计的分词、jieba库等内容。
一直在说中文分词,那中文分词和欧语系的分词有什么不同或者说是难点的呢?
主要难点在于汉语结构与印欧体系语种差异甚大,对词的构成边界方面很难进行界定。比如,在英语中,单词本身就是“词”的表达,一篇英文文章就是“单词”加分隔符(空格)来表示的,而在汉语中,词以字为基本单位的,但是一篇文章的语义表达却仍然是以词来划分的。因此,在处理中文文本时,需要进行分词处理,将句子转化为词的表示。这个切词处理过程就是中文分词,上通过计算机自动识别出句子的词,在词间加人边界标记符,分隔出各个词汇。整个过租看似简单,然而实践起来却很复杂,主要的困难在于分词歧义。
接下来正式开始内容的介绍和学习…
二、 内容
自中文自动分词被提出以来,历经将近30年的探索,提出了很多方法,可主要归纳为 “规则分词”“统计分词”和“混合分词(规则+统计)”这三个主要流派。规则分词是最早兴起的方法,主要是通过人工设立词库,按照一定方式进行匹配切分,其实现简单高效,但对新词很难进行处理。随后统计机器学习技术的兴起,就有了统计分词,能够较好应对新词发现等特殊场景。然而实践中,单纯的统计分词也有缺陷,那就是大过于依赖语料的质量,因此实践中多是采用这两种方法的结合,即混合分词。
2.1 规则分词
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不予切分。
按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法。
2.1.1 正向最大匹配
正向最大匹配(Maximum Match Method, MM法)的基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字中重新进行匹配处理。如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。如图2.1所示

图 2.1 正向最大匹配算法流程图
其算法描述如下:
1)从左向右取待切分汉语句的m个字符作为匹配字段,m为机器词典中最长词条的字符数。
2)在找机器词典并进行匹配。若匹配成功, 则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉, 剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
2.1.2 逆向最大匹配
逆向最大匹配(Reverse Maximum Match Method,RMM法)的基本原理与MM法相同,不同的是分词切分的方向与MM法相反。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(i为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精度。所以,逆向最大匹配法比正向最大匹配法的误差要小。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
实例代码如下:
# 逆向最大匹配
class IMM(object):
def __init__(self, dic_path):
self.dictionary = set()
self.maximum = 0
# 读取词典
with open(dic_path, 'r', encoding='utf8') as f:
for line in f:
line = line.strip()
if not line:
continue
self.dictionary.add(line)
if len(line) > self.maximum:
self.maximum = len(line)
def cut(self, text):
result = []
index = len(text)
while index > 0:
word = None
for size in range(self.maximum, 0, -1):
if index - size < 0:
continue
piece = text[(index - size):index]
if piece in self.dictionary:
word = piece
result.append(word)
index -= size
break
if word is None:
index -= 1
return result[::-1]
def main():
text = "南京市长江大桥"
tokenizer = IMM('./data/imm_dic.utf8')
print(tokenizer.cut(text))
if __name__ == '__main__':
main()
运行结果如下:
[‘南京市’, ‘长江大桥’]
2.1.3 双向最大匹配
双向最大匹配法(Bidirectction
Matching method)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。
据SunM.S.和Benjamin K.T. ( 1995)的研究表明,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,使用正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因。
2.2 统计分词
随着大规模语料库的建立,统计机器学习方法的研究与发展,基于统计的中文分词算法渐渐成为主流。其主要思想是把每个词看做是由词的最小单位的各个字组成的,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词。因此我们就可以利用字与字相邻出现的频率来反应成词的可靠度,统计语料中相邻共现的各个字的组合的频度,当组合频度高于某一个临界值时,我们便可认为此字组可能会构成一个词语。
基于统计的分词,一般要做如下两步操作:
1)建立统计语言模型。
2)对句子进行单词划分,然后对划分结果进行概率计算,获得概率最大的分词方式。这里就用到了统计学习算法,如隐含马尔可夫(HMM)、条件随机场(CRF)等。
接下来重点讲解一下这两步骤的关系:这是重点哦,重点,重点。
①的目的是判断分词结果是否有歧义。②的目的是选择出分词结果概率最大(最优)的内容,并将结果依次排序记录。 如图2.2所示

图 2.2 语言模型和HMM模型关系
刚才已经说了,①的前提是要有已经分词过的预料,也就是②提供给它的最优分词结果。当①发现②给它的预料有歧义,则会要求②提供次优的结果进行分析,知道选择出没有歧义的内容。
2.2.1 语言模型
语言模型在信息检素、机器翻译、语音识别中承担着重要的任务。用概率论的专业术语描述语言模型就是:为长度为m的字符串确定其概率分布P(w1,w2,…,wm), 其中w1到wm依次表示文本中的各个词语。一般采用链式法则计算其概率值:
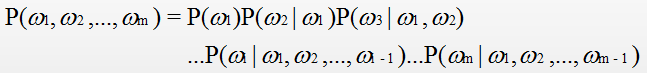
当文本过长时,公式右部从第三项起的每一项计算难 度都很大。为解决该问题,有人提出n元模型(n-gram model)降低该计算难度。所谓n元模型就是在估算条件概率时,忽略距离大于等于n的上文词的影响,因此P的计算可简化为:
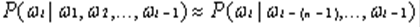
当n=1时成为一元模型。此时整个句子整个句子的概率可表示为:
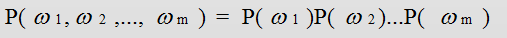
观察可知,在一元语言模型中,整个句子的概率等于各个词语概率的乘积。言下之意就是各个词之间都是相互独立的。这无疑是完全损失了句中的词序信息,所以一元模型的效果并不理想。
当n=2时称为二元模型(bigram model)

当n=3时称为三元模型(bigram model)
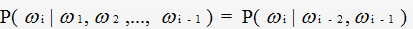
显然当n≥2时,该模型是可以保留一定的词序信息的,而且n越大,保留的词序信息越丰富,但计算成本也呈指数级增长。
一般使用频率计数的比例来计算n 元条件概率: 这点非常重要,非常重要,非常重要

式中count(wi-(n-1),…,wi-1)表示词语wi-(n-1),…,wi-1在语料库中出现的总次数。
由此可见,当n越大时,模型包含的词序信息越丰富,同时计算量随之增大。与此同时,长度越长的文本序列出现的次数也会减少,如按照上式估计n元条件概率时,就会出现分子分母为零的情况。因此,一般在 n元模型中需要配合相应的平滑算法解决该问题,如拉普拉斯平滑算法等,让分母+1或者一个很小的数字,这样可以保证分母不为零。
2.2.2 HMM模型
在具体了解隐含马尔科夫模型在NLP中的应用前,先来看一下到底什么是HMM。隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。
下面用一个简单的例子来阐述:
如图2.3所示,假设有三个不同的骰子。第一个骰子是平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。

图 2.3 HMM示例
开始掷骰子,先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是所用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
如图2.4所示,一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。

图2.4 隐含马尔可夫模型
如图2.5所示,同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。

图2.5 隐含状态转换关系
2.2.2.1 HMM模型介绍
既然已经了解了什么是隐含马尔可夫模型(HMM),现在来介绍HMM是如何在中文分词里面的应用。实际上HMM是将分词作为字在字串中的序列标注任务来实现的。其基本思路是:每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),现规定每个字最多只有四个构词位置:即B (词首) 、M (词中) 、E (词尾)和S (单独成词),那么下面句子(1)的分词结果就可以直接表示成如(2)所示的逐字标注形式:
(1) 中文/分词/是/文本处理/不可或缺/的/一步!
(2) 中/B文/E分/B词/E是/S文/B本/M处/M理/E不/B可/M或/M缺/E的/S一/B步/E!/S
用数学抽象表示如下:λ = λ1λ2…λn代表输人的句子,n为句子长度,λi表示字,O=O1O2.,On代表输出的标签,那么理想的输出即为,式1:
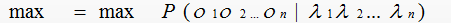
在分词任务上,o即为B、M、E、S这4种标记,λ为诸如“中”“文”等句子中的每个字(包括标点等非中文字符)。
需要注意的是,P(o/λ ) 是关于2n个变量的条件概率,且n不固定。因此,几乎无法对P(o/λ ) 进行精确计算。重要重要重要这里引人观测独立性假设,即每个字的输出仅仅与当前字有关,于是就能得到下式2:
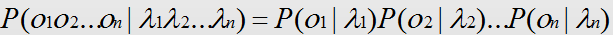
现在开始尝试着理解一下式1和式2,:式1实际上就是在已知显式一句汉字的情况下,求该汉字的最大概率的构词组合,其中构词组合就是隐含马尔可夫的隐含状态链;式2是引入了独立性假设之后,对式1进行简化,即已知每一个字去他的构词位置。
很显然,对于P(o/λ )这样的概率是很难求出来的,也就是说,根据通过已知去直接给出未知的概率,这样根本不可能实现。所以一定要对P(o/λ )进行转化,这里就顺其自然的引入了贝叶斯公式:
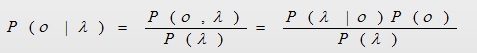
通过贝叶斯公式就可以将未知的P(o/λ ),通过已知的内容:P(λ/0)在词库中汉字λ作为o的构词位置的概率是多少;P(o)构词位置o的概率;以及P(λ )汉字在词库中的概率;通过这三个已知量去求未知量P(o/λ )。
接下来继续求解P(λ/0)*P(o),在这里要继续做马尔可夫假设,即:每个字的输出仅仅与当前字有关,得到下式:

对于P(o):
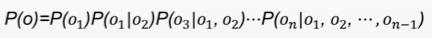
做其次马尔可夫假设,即:每个输出仅仅与上一个输出有关,可以得到:

于是通过上面的分析就可以得到:
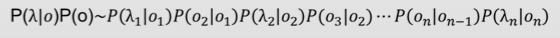
在HMM中,将P(λ k/ok)称为发射概率,P(Ok/Ok-1) 称为转移概率。通过设置某些 ,可以排除类似BBB、EM等不合理的组合。
2.2.2.2 Viterbi(维特比算法)介绍
在HMM中,求解MaxP(λ/o) P(o)的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个 oi ,那么从初始节点到 oi-1点的路径必然也是一个最优路径一因为每一个节点 oi只会影响前后两个 P(oi-1/oi)和P(oi/oi+1)。
根据这个思想,可以通过递推的方法,在考虑每个oi时只需要求出所有经过各oi-1 的候选点的最优路径,然后再与当前的 oi 结合比较。这样每步只需要算不超过 l2次,就可以逐步找出最优路径。Viterbi 算法的效率是O(n*l2 ),l是候选数目最多的节点 的候选数目,它正比于n,这是非常高效率的。
在介绍维特比算法是,提到了,它是一个动态规划方法的应用。首先介绍一下什么是DP动态规划:
在介绍动态规划算法之前,不妨先看一下小例子:青蛙一次只能蹦上1个或2个台阶,现在有10个台阶,请问青蛙上这10个台阶有多少种蹦法?
来分析一下,假设青蛙现在还差一次就能到达第10个台阶,那么青蛙现在只能在第8个台阶上,或者第9个台阶上,也就是说,青蛙在第8个台阶上蹦2个台阶,或者在第9个台阶上蹦1个台阶。至于在第8个台阶上蹦1个台阶之后再蹦1个台阶,是考虑在后一种情况中。那么青蛙蹦上第10个台阶的蹦法即为:F(10) = F(8) + F(9)。依次类推,F(9) = F(7) + F(8), F(8) = F(6)+F(7)。那么我们可以得到一个通用公式:
F(N) = F(N-2) + F(N-1); (N>2)
F(1) = 1;
F(2) = 2;
但是这样的解答显然不够完美。为什么呢?如果此时楼梯数,从10变成了100,那么以上代码的数量级就大的多了。
为什么呢?本质上是由递归的缺点决定的:递归太深容易造成堆栈的溢出。递归写起来虽然很方便,代码结构层次清晰,而且可读性高,但是这些都不能遮盖住递归最大的缺点:太占资源。因为递归需要保护现场,由于递归需要系统堆栈,所以空间消耗要比非递归代码要大很多。而且,如果递归深度太大,系统很有可能是撑不住的。
我们来分析以上上述递归的执行过程:
F(10) = F(8) + F(9);
F(10) = F(6) + F(7) + F(7) + F(8);
F(10) = F(6) + F(7) + F(7) + F(6) + F(7);
F(10) = F(4) + F(5) + F(5) + F(6) + F(5) + F(6) + F(4) + F(5) + F(5) + F(6);
…
最终的结果是:为了计算F(10), 需要计算1次F(9), 2次F(8), 3次F(7), 4次F(6), 5次F(5), 6次F(4)…快写不下去了。通过分析我们知道,这种递归求解的时间复杂度达到了O(2^N)。F(N)的计算中存在大量重叠的子问题,可想而知,当N为100时,各个F(n)得计算多少次了。有没有办法让每个状态都只计算一次,然后将结果保存,用于下一次计算呢?这样既可以降低CPU的使用率,可以降低系统栈的开销,因为无需堆栈来保存递归的现场。答案是肯定的,动态规范算法就能很好地解决这种问题。动态规划(简称DP)是一种通过存储部分结果从而实现高效递归算法的算法,它本质上来说是一种用空间去换取时间的策略;思想是把一个大问题进行拆分,细分为多个小的子问题,并且能够从这些小的子问题的解中推导出原问题的解,这个大的问题要满足一下两个重要性质才能运用动态规划算法来解决:
- 最优子结构(即大问题拆分后的小问题的解是仍然是最优解)
- 子问题重叠,即拆分后的子问题并不总是新的问题,这些问题会被重复多次计算。
动态规划正是将每个子问题的解存储在表中,再次遇到相同的问题时只需要查表而不需要重新计算,从而获得高效的算法。
接下里还是通过上述的“爬楼梯问题”为例介绍DP动态规划的思想。根据动态规划的思想,首先,将问题分段,过程如下:
F(1) = 1;
F(2) = 2;
F(N) = F(N-2) + F(N-1);
我们从头开始按顺序求解子阶段。
F(1) = 1;
F(2) = 2;
F(3) = F(1) + F(2) = 1 + 2 = 3;
.
.
F(10) = F(8) + F(9) = 34 + 55 = 89;
通过递推,用两个变量记录每次前面的两个状态的最优解,当用到这个最优解的时候,再拿出来就可以了。
DP思想的Python代码实现如下:
def upstair(n):
temp1 = 1
temp2 = 2
if (n < 1):
return 0;
if(n < 3):
return n
else:
int
sum = 0
i = 3
for i in range(n+1):
sum = temp1 + temp2
temp1 = temp2
temp2 = sum
i+=1
return sum
if __name__ == '__main__':
print("nums of up stairs : " + str(upstair(1)));
print("nums of up stairs : " + str(upstair(2)));
print("nums of up stairs : " + str(upstair(3)));
print("nums of up stairs : " + str(upstair(10)));
介绍完了动态规划,接下来正式开始介绍Viterbi算法:
首先定义变量δt(i):表示时刻t状态为i的所有路径中的概率最大值,公式如下:

这个算法猛地看起来很是头痛,接下来,一点一点的通过一个例子来介绍:
通过上面讲解的HMM,可以得出以下内容:
初始概率分布:
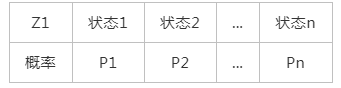
上面这个n维的向量就是初始概率分布,记做π。
转移矩阵:

上面这些nn的矩阵被称为状态转移矩阵,用Ann表示。
观测矩阵:

这可以用一个nm的矩阵表示,也就是观测矩阵,记做Bnm。
由于HMM用上面的π,A,B就可以描述了,于是我们就可以说:HMM由初始概率分布π、状态转移概率分布A以及观测概率分布B确定,为了方便表达,把A, B, π 用 λ 表示,即:
λ = (A, B, π)
当然还有观测序列O = {o1,o2, …, oT}。
现在进行问题描述:
假设有3个盒子,编号为1,2,3,每个盒子都装有红白两种颜色的小球,数目如下:
| 盒子号 | 1 | 2 | 3 |
|---|---|---|---|
| 红球数 | 5 | 4 | 7 |
| 白球数 | 5 | 6 | 3 |
然后按照下面的方法抽取小球,来得到球颜色的观测序列:
1,按照 π=(0.2, 0.4, 0.4) 的概率选择1个盒子,从盒子随机抽出1个球,记录颜色后放回盒子;
2,按照下图A选择新的盒子,按照下图B抽取球,重复上述过程;

对于上面的内容:
- A的第i行是选择到第i号盒子,第j列是转移到j号盒子,如:第一行第二列的0.2代表:上一次选择1号盒子后这次选择2号盒子的概率是0.2。
- B的第i行是选择到第i号盒子,第j列是抽取到j号球,如:第二行第一列的0.4代表:选择了2号盒子后抽取红球的概率是0.4。
现在求,观测序列为O=(红,白,红)时,最大可能依次从哪些盒子里选出来的呢,也就是试求最优状态序列,即最优路径I*=
(i1*, i2*, i3*)?
还是一步一步的来:
(1)初始化:
t=1时,对每个状态i, i=1, 2, 3,求状态为i观测o1为红的概率,记此概率为δ1(i),则:
δ1(i) = πibi(o1)=πibi(红), i = 1, 2, 3
代入实际数据
δ1(1) = 0.10,δ1(2) =0.16,δ1(3) = 0.28
记ψ1(i) = 0,i = 1, 2, 3。
其中δt(i):表示时刻t状态为i的所有路径中的概率最大值,δ1(1) 就表示在t1时刻,状态1下观测值为红色的概率,依次类推
求出状态2,3。也就是说i的最大值是状态数。πi表示的初始状态为i时的概率,如π1表示从选择第一个箱子的概率为0.2;
ψ1(i)的初始值必须为零,如为任意正整数,这表示该节点为最大的概率值。
(2)递推(这一部分才是核心内容,即当t=n时)
t=2时,对每个状态i,求在t=1时状态为j观测为红并且在t=2时状态为i观测为白的路径的最大概率,记概率为δ2(t),则根据:
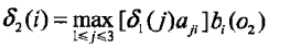
同时,对每个状态i, i = 1, 2, 3,记录概率最大路径的前一个状态j:
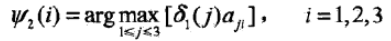
关于arg max的意思是:
arg max f(x): 当f(x)取最大值时,x的取值
arg min f(x):当f(x)取最小值时,x的取值
就有:

类似于上面的青蛙跳楼梯的例子,这里是通过δt(i)来记录上一次算出来的最大值,而且这个最大值是计算每条路径后,保存的每个状态的最大值。通过ψt(i) ,来保存t时刻,对每个状态i, 记录概率最大路径的前一个状态j;通过δt(i),ψt(i)这两个内容记录,当下次再使用前一个状态时,就可以很好地直接拿出来用。同时,这里面记录的内容都是最优解,最终组合的结果也会是最优解。
(3)求最优路径的终点
以P表示最优路径的概率,则
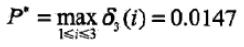
刚才已经说了,δt(i)表示的表示时刻t状态为i的所有路径中的概率最大值,也就是说当t为最终时间节点时,找到Tmax时δt(i)的最大值就是最优解
最优路径的终点是i3
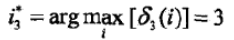
接下来通过做到arg max[δtmax(i)]就可以找到最终的最优路径终点节点,这里不要忘了arg maxf(i)的值,是返回使分f(i)最大的i的值,也就是这里的i节点
(4)逆向找i2*,i1*:
在t=2时,i2* = ψ3(i3*) =ψ3(3) = 3
在t=1时,i1* = ψ2(i2*) =ψ2(3) = 3
于是求得最优路径,即最有状态序列I* = (i1*,i2*, i3*) = (3, 3, 3)。
这里面需要注意的是,it*= ψt+1(i+t*)也就是说为啥是计算t时间的最优节点时,选择的却是计算t+1时的值,因为这个工程是逆向寻找最优节点。所以要根据t+1的解来进行推导
最终的状态图2.6如下所示:

图2.6
三、 总结
本篇内容主要介绍了基于规则的分词:正向最大匹配法、逆向最大匹配法、双向最大匹配法。基于统计的分词介绍了语言模型和HMM隐含马尔可夫算法,并且介绍了语言模型和HMM隐含马尔可夫算法的关系。详细讲解了Viterbi算法。














 750
750
























 到【灌水乐园】发言
到【灌水乐园】发言










不咸的鱼59: 请问alink的版本是多少呢?
沧海寄馀生: 自己写好吗 构建pherf全部是抄袭的