【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)

 最新推荐文章于 2023-11-21 08:07:54 发布
最新推荐文章于 2023-11-21 08:07:54 发布
 阅读量1.5k
阅读量1.5k
 收藏
29
收藏
29


 点赞数
10
点赞数
10

需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、RDD的创建
Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。
1、从文件系统加载数据创建RDD
从运行结果反馈的信息可以看出,wordfile是一个String类型的RDD,或者以后可以简单称为RDD[String],也就是说,这个RDD[String]里面的元素都是String类型
scala> val test=sc.textFile("file:///export/data/test.txt")
test: org.apache.spark.rdd.RDD[String]=file:///export/data/test.txt MapPartitionsRDD[1] at textFile at <console>:24
2、从HDFS中加载数据创建RDD
scala> val testRDD=sc.textFile("/data/test.txt")
testRDD:org.apache.spark.rdd.RDD[String]=/data/test.txt MapPartitionsRDD[1] at textFile at <console>:24
上面两种创建RDD的方式是完全等价的,只不过使用了不同的目录形式
Spark可以通过并行集合创建RDD。即从一个已经存在的集合、数组上,通过SparkContext对象调用parallelize()方法创建RDD。
scala> val array=Array(1,2,3,4,5)
array: Array[Int]=Array(1,2,3,4,5)
scala> val arrRDD=sc.parallelize(array)
arrRDD: org.apache.spark.rdd.RDD[Int]=ParallelcollectionRDD[6] at parallelize at <console>:26
二、RDD的操作
Spark用Scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作处理。RDD经过一系列的“转换”操作,每一次转换都会产生不同的RDD,以供给下一次“转换”操作使用,直到最后一个RDD经过“行动”操作才会被真正计算处理,并输出到外部数据源中,若是中间的数据结果需要复用,则可以进行缓存处理,将数据缓存到内存中
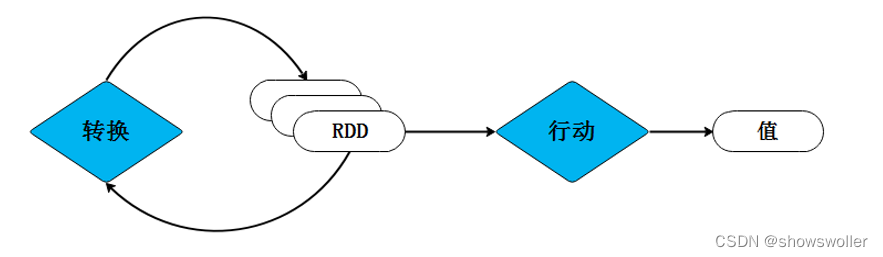
1:转换算子
RDD处理过程中的“转换”操作主要用于根据已有RDD创建新的RDD,每一次通过Transformation算子计算后都会返回一个新RDD,供给下一个转换算子使用。直到最后一个RDD经过行动操作才会被真正计算处理,并输出外部数据源中,若是中间的数据结果需要复用,则可以进行缓存处理,将数据缓存到内存中
2:行动算子
行动算子主要是将在数据集上运行计算后的数值返回到驱动程序,从而触发真正的计算。

三、词频统计实战
在Linux本地系统的根目录下,有一个words.txt文件,文件里有多行文本,每行文本都是由2个单词构成,且单词之间都是用空格分隔。现在,通过RDD统计每个单词出现的次数(即词频),具体操作过程如下图所示。
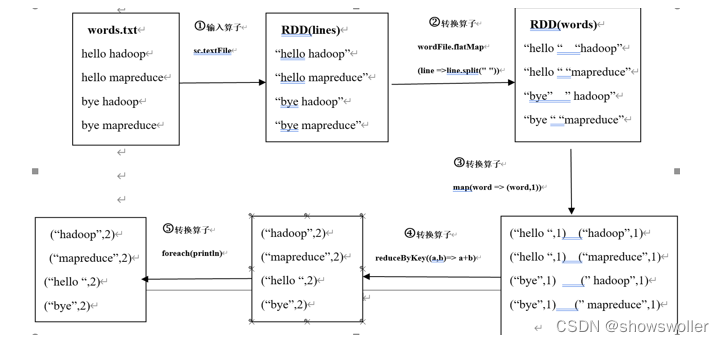
输出结果如下

四、倒排索引实战
下面我们用Spark的RDD操作实现倒排索引功能 具体操作步骤如下
1)利用IntelliJ IDEA新建一个maven工程
2)修改pom.XML添加相关依赖包
3)在工程名处点右键,选择Open Module Settings
4)配置Scala Sdk
5) 新建文件夹scala
6) 将文件夹设置成Sources Root
7) 新建scala类
程序输出结果如下

代码如下
import org.apache.spark.sql.SparkSession
object InvertedIndex {
def main(args: Array[String]): Unit = {
//获取sparkSession对象
val spark = SparkSession.builder().appName("InvertedIndex").master("local").getOrCreate()
//读取目录
val data = spark.sparkContext.wholeTextFiles("D:/file")
data.foreach(println)
val r1 = data.flatMap {
x =>
//使用分割"/''获取文件名
val doc=x._1.split("/").last
//先按行切分,在按列空格进行切分
x._2.split("\r\n").flatMap(_.split(" ").map { y => (y, doc)})}
r1.foreach(println)
//按单词分组
val result=r1.groupByKey.map{case(x,y)=>(x,y.toSet.mkString(":"))}
result.foreach(println)
}
}
创作不易 觉得有帮助请点赞关注收藏~~~
















 1066
1066










 暂无认证
暂无认证







































 到【灌水乐园】发言
到【灌水乐园】发言












emmmmm666: 已关注点赞收藏,求源码,大佬。呜呜呜
2203_75308986: 已三连,求源码
bluesky1000000_: 已关注点赞收藏,求源代码
^_^160小土豆: 求源码和文件
lipqjsjiejeke: 已点赞加关注,求数据集!谢谢!1460333498@qq.com