爬虫分析某微博账号转发影响因子

 最新推荐文章于 2024-03-10 14:33:59 发布
最新推荐文章于 2024-03-10 14:33:59 发布
 阅读量2.9k
阅读量2.9k
 收藏
17
收藏
17


 点赞数
4
点赞数
4



文章目录
- 任务
- 过程
- 角度:某博主对转发微博影响
- 数据结构
- 数据采集
- 数据处理
- 博主转发原文的数据
- 博主转发博文的数据
- 博主原文与转发数据对比
- 各数据量与粉丝量之比
- 典型博主展示
- 吴京
- vista看天下
- 华中科技大学
- 科比
任务
受一个很有想法的同学的启发,通过挖掘一个微博的转发,查看对其的转发量最有影响的因素与节点。
当然这个是需要很大规模的数据支持才能够显著说明问题,在解决这个问题的过程中,逐渐演变为对某个博主的数据分析。
过程
角度:某博主对转发微博影响
在 上一个文章的成功基础上,基本能够获取微博的任何内容。
数据结构
做为第一个测试的项目,首先对少量有价值的信息进行分析,这里选取:
| 博文数据 | 博主数据 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 转发 | 转发量 | 评论量 | 点赞量 | 发文时间 | 内容概要 | 粉丝量 | 个人信息(默认已知,不记录) | ||
| 原文 | id | 昵称 | 个人信息(可选)* | ||||||
*个人信息: 有性别、所在地概要信息及性别、所在地、星座、大学、公司等完整信息
数据采集
根据文章与书籍得知,微博移动端页面采用异步加载技术。
使用浏览器的检查(inspect,F12)功能,切换为移动端,再刷新页面(F5),获取到需要的内容链接Url。
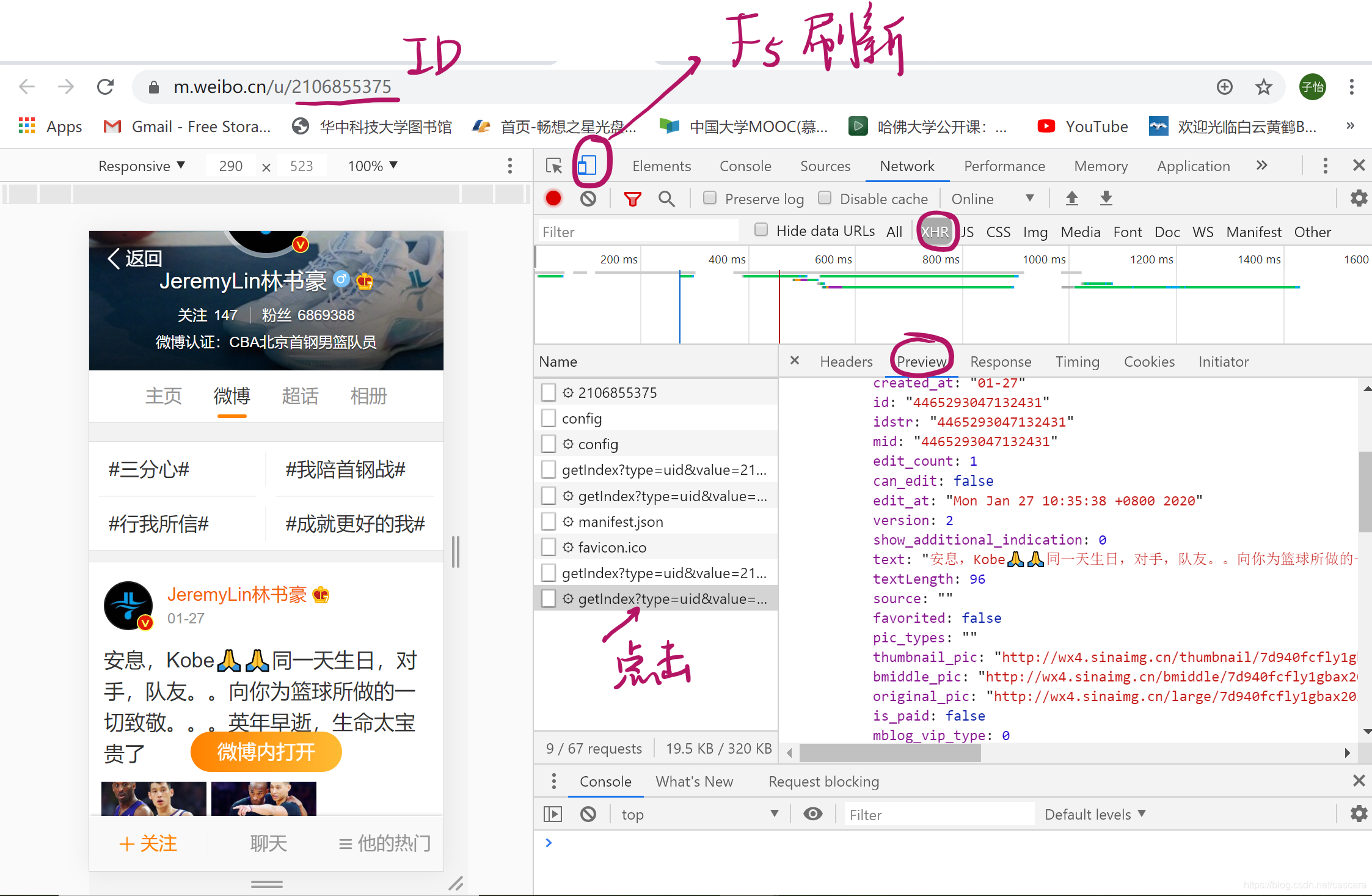
由此,可获取界面上的数据及微博的具体信息。
信息为json格式,通过构造字典囊括关键字段。
为获取一个微博博主的所有微博信息,需要构造囊括这些信息的URL。通过观察可知,格式统一为:
https://m.weibo.cn/api/container/getIndex?containerid=230413博主的id号_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page=页码数
因此构造出一系列的URL
###某微博账户的全部微博内容
def contentURL(id,pages):
i=0
urls=[]
for page in pages:
if page is not 0:
urls+=['https://m.weibo.cn/api/container/getIndex?containerid=230413'+str(id)+'_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page='+str(page)]
return urls
为灵活调整需要获取的数据信息,特将储存与建立数据列表规范化,通过在开始构建词典,将需要的数据设置为True:
#获取博文信息范围、排列
blogRangeDict={
'visible': False,#{type: 0, list_id: 0}
#发文时间
'created_at': True,#"20分钟前"
'id': False,#"4466073829119710"
'idstr': False,#"4466073829119710"
'mid': False,#"4466073829119710"
'can_edit': False,#false
'show_additional_indication': False,#0
#博文内容
'text': True,#"【情况通报】2019年12月31日,武汉市卫健部门发布关于肺炎疫情的情况通报。
'textLength': False,#452
'source': False,#"360安全浏览器"
'favorited': False,#false
'pic_types': False,#""
'is_paid': False,#false
'mblog_vip_type': False,#0
'user': False,#{id: 2418542712, screen_name: "平安武汉",…}
#转发、评论、点赞数
'reposts_count': True,#1035
'comments_count': True,#1886
'attitudes_count': True,#7508
'pending_approval_count': False,#0
'isLongText': False,#true
'reward_exhibition_type':False,# 0
'hide_flag': False,#0
'mblogtype': False,#0
'more_info_type': False,#0
'cardid': False,#"star_11247_common"
'content_auth': False,#0
'pic_num': False,#0
#若无相关信息,则显示:
'infoNoExist':'未知'
}
可以将获取到的字典格式的json数据筛选出之前定义的需要的数据,并以列表形式传递,便于之后储存在csv格式的文件中。
#将字典类型的信息格式传递为需要的信息列表
#infoDict 字典类型(json)的信息
#rangeDict 定义的需要的数据(例:blogRangeDict、userRangeDict等)
def getInfoList(infoDict,rangeDict):
infoList=[]
for item in rangeDict:
if rangeDict.get(item) is True:
content=infoDict.get(item)
infoList.append(content)
else:
infoList.append(rangeDict['infoNoExist'])
return infoList
同理,构造csv格式文件的标题
#构造csv文件标题
#rangeDict 定义的需要的数据(例:blogRangeDict、userRangeDict等)
#prefix 此标题的前缀,防止同名
def getInfoTitle(rangeDict,prefix):
titleList=[]
for item in rangeDict:
if(rangeDict.get(item) is True):
titleList.append(prefix+item)
return (titleList)
通过已构造出的一系列URL爬取数据并写入csv文件:
*注:传入的csvWriter为writer格式,例如:
fp = open(fileAddress,'w+',newline='',encoding='utf-16')
writer=csv.writer(fp)
reRatio(urls,writer)
……
若爬取至终点(页面无内容),则返回False,程序终止;否则返回True,便于程序构造下一批URL与再次爬取。
###在已有的一系列urls中进行操作
###筛选出微博转发内容进行操作
def reRatio(urls,csvWriter):
notEnd= True
#定义标题
retweetBlogTitle=getInfoTitle(blogRangeDict,'转发')#转发博文信息标题
retweetUserTitle=getInfoTitle(userRangeDict,'转发')#转发博主信息标题
originBlogTitle=getInfoTitle(blogRangeDict,'原文')#原文博文信息标题
originUserTitle=getInfoTitle(userRangeDict,'原文')#原文博主信息标题
infoTitle=getInfoTitle(infoRangeDict,'')#原文博主个人主页信息标题
#写表格的标题
if getConcreteInfoList is True:
csvWriter.writerow(retweetBlogTitle+retweetUserTitle+originBlogTitle+originUserTitle+infoTitle)
else:
csvWriter.writerow(retweetBlogTitle+retweetUserTitle+originBlogTitle+originUserTitle)
for url in urls:
response = requests.get(url,headers=headers)
resjson = json.loads(response.text)
cards=resjson['data']['cards']
#print(cards)
#结束最后
if(len(cards)==1):
notEnd=False
break
#遍历一个页面的所有微博
for card in cards:
try:
#转发博文与博主信息
retweetBlogInfoDict=card['mblog']
retweetUserInfoDict=retweetBlogInfoDict['user']
#筛选出转发的微博
try:
originBlogInfoDict=retweetBlogInfoDict['retweeted_status']
if originBlogInfoDict is not None:
#转发博文原文与博主信息
originUserInfoDict=originBlogInfoDict['user']
retweetUserID=retweetUserInfoDict['id']
originUserID=originUserInfoDict['id']
###不是转发自己的微博,则选中进行处理
if(retweetUserID!=originUserID):
infoList=[]
#转发博文数据
retweetBlogInfoList=getInfoList(retweetBlogInfoDict,blogRangeDict)
infoList+=retweetBlogInfoList
#转发博主数据
##默认已知
retweetUserInfoList=getInfoList(retweetUserInfoDict,userRangeDict)
infoList+=retweetUserInfoList
#原文博文数据
originBlogInfoList=getInfoList(originBlogInfoDict,blogRangeDict)
infoList+=originBlogInfoList
#原文博主数据
originUserInfoList=getInfoList(originUserInfoDict,userRangeDict)
infoList+=originUserInfoList
#originUserID为原文账号的ID
#可在此对id进行信息采集
if getConcreteInfoList is True:
infoDict=getInfo(isLogin,originUserID)
otherInfoList=getInfoList(infoDict,infoRangeDict)
infoList+=otherInfoList
#print(infoList)
#保存数据至csv
csvWriter.writerow(infoList)
#不断获取该博主对的影响力
#break
except:
pass
except:
pass
#延时,防止反爬
time.sleep(3)
return notEnd
主干程序:通过提供博主的id号,进行完整的数据采集操作,并保存至本地的csv文件中。
def downloadData(id):
tweeter=getExatInfo('昵称',2,int(id))
batch=0
while(1):
fileAddr=addrFile(tweeter,'batch'+str(batch))
if os.path.exists(fileAddr) is True:
print(tweeter+'已存在,跳过采集')
else:
print('文件将写入:'+fileAddr)
fp = open(fileAddr,'w+',newline='',encoding='utf-16')
writer=csv.writer(fp)
if reRatio(contentURL(id,range(20*batch,20*(batch+1))),writer) is False:
fp.close()
break
fp.close()
print('第'+str(batch)+'批数据已记录完毕')
batch+=1
运行示意如下:

获取到的数据如图:
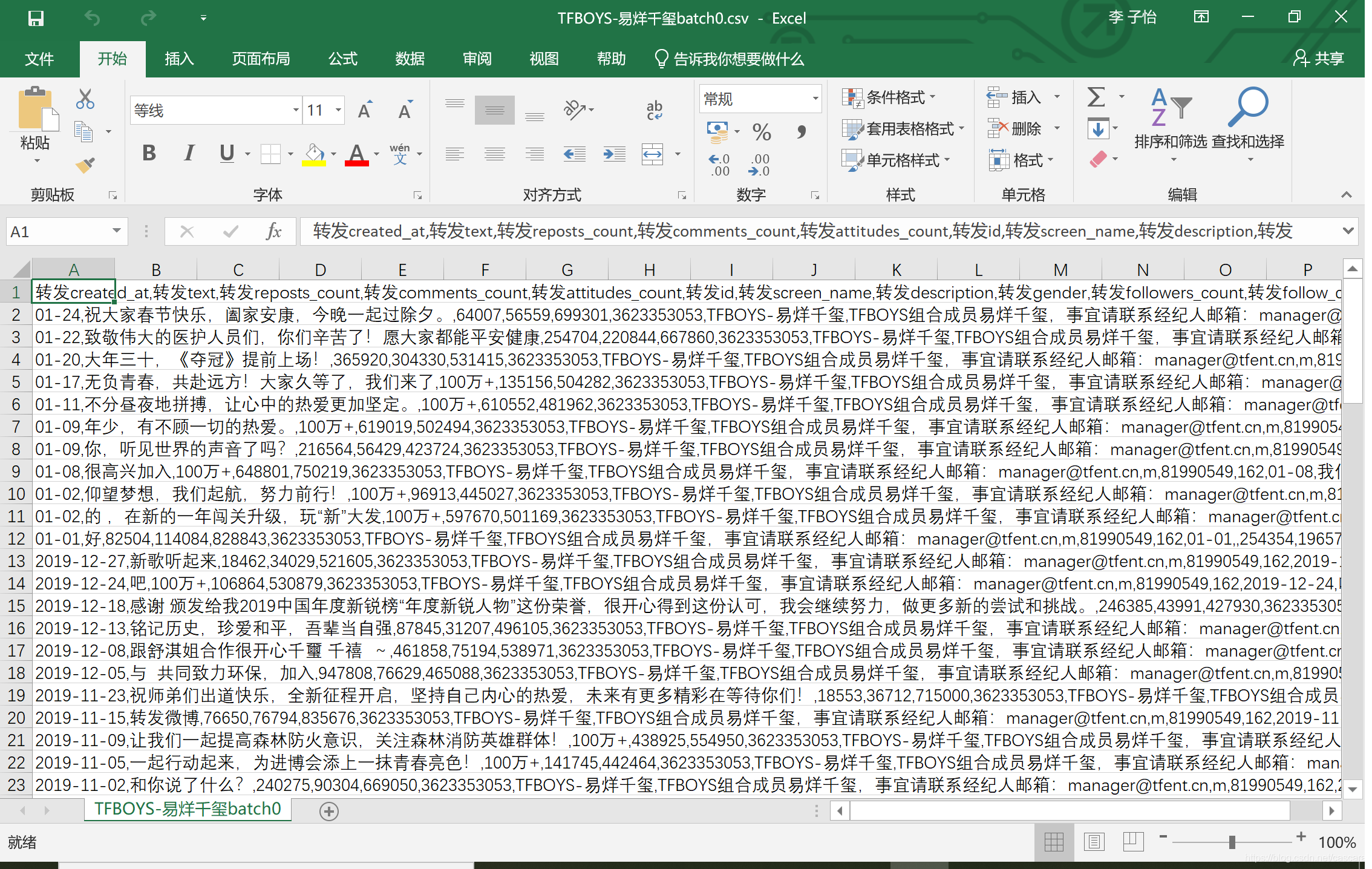

数据处理
处理数据关键在于可视化,图像能够说明一切:
在读取完爬取到的数据后,将重点的数字通过图像表现出来。
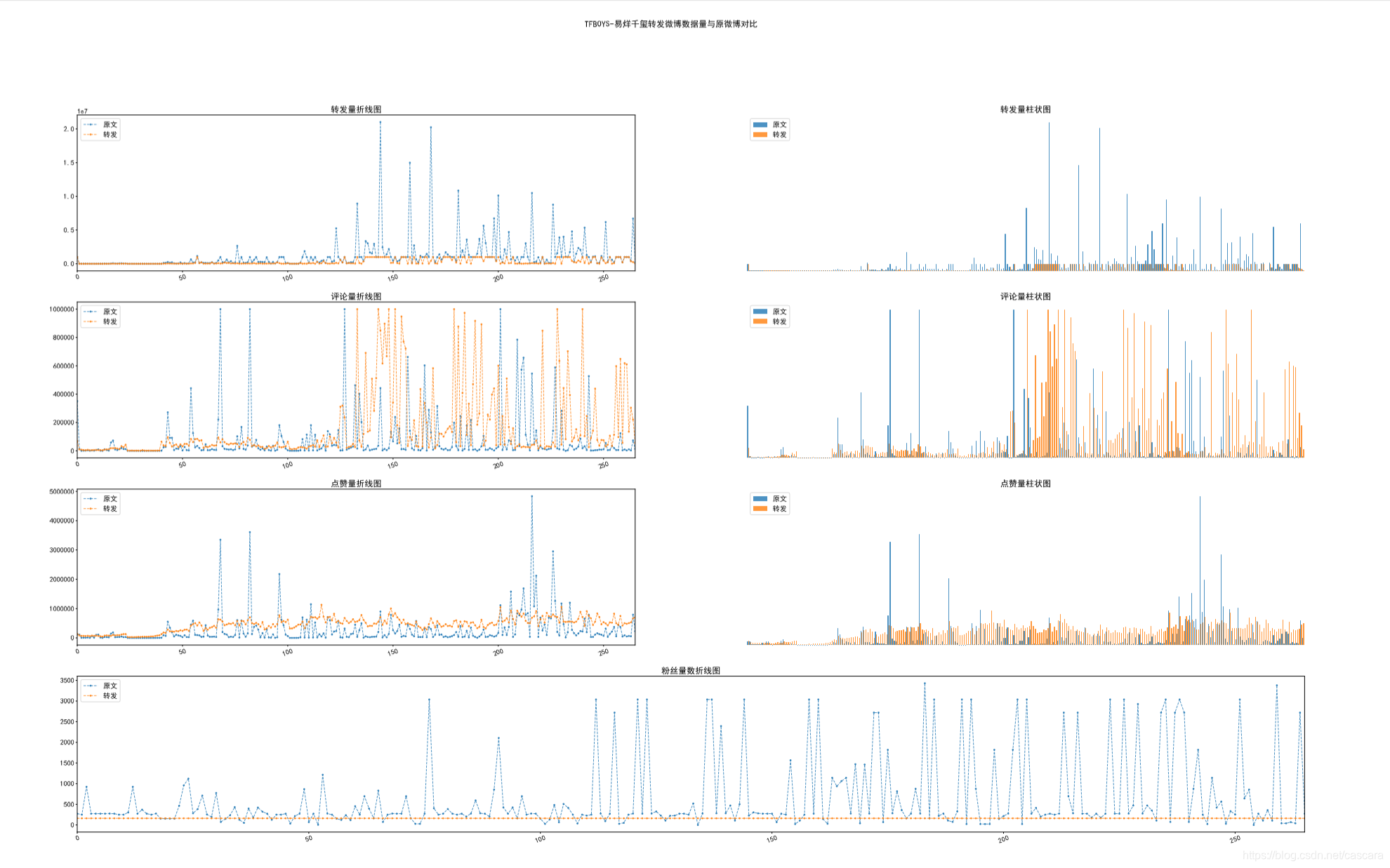
博主转发原文的数据
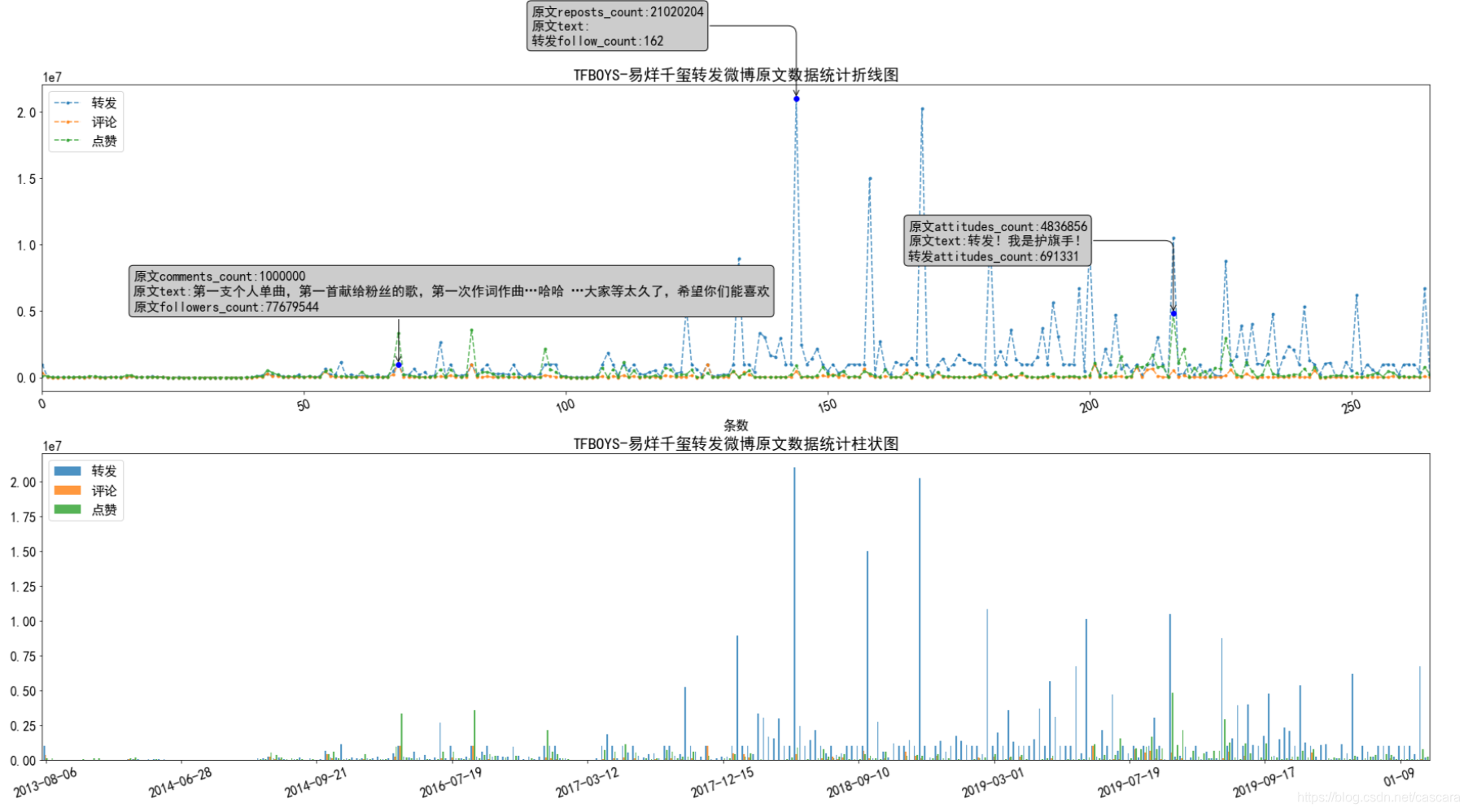
博主转发博文的数据
微博抑制流量造假,将转发与评论数的上限设定为100万,故出现如下图像,另:表情符无法显示。
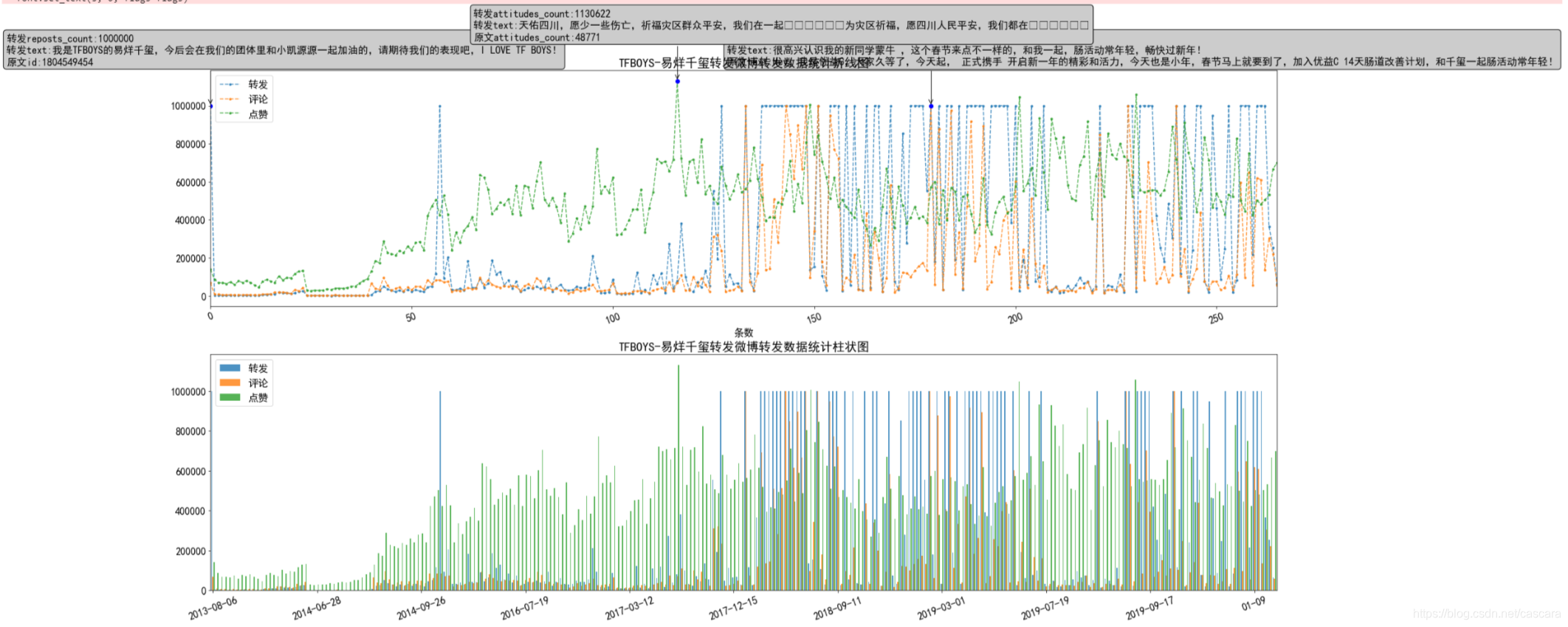
博主原文与转发数据对比
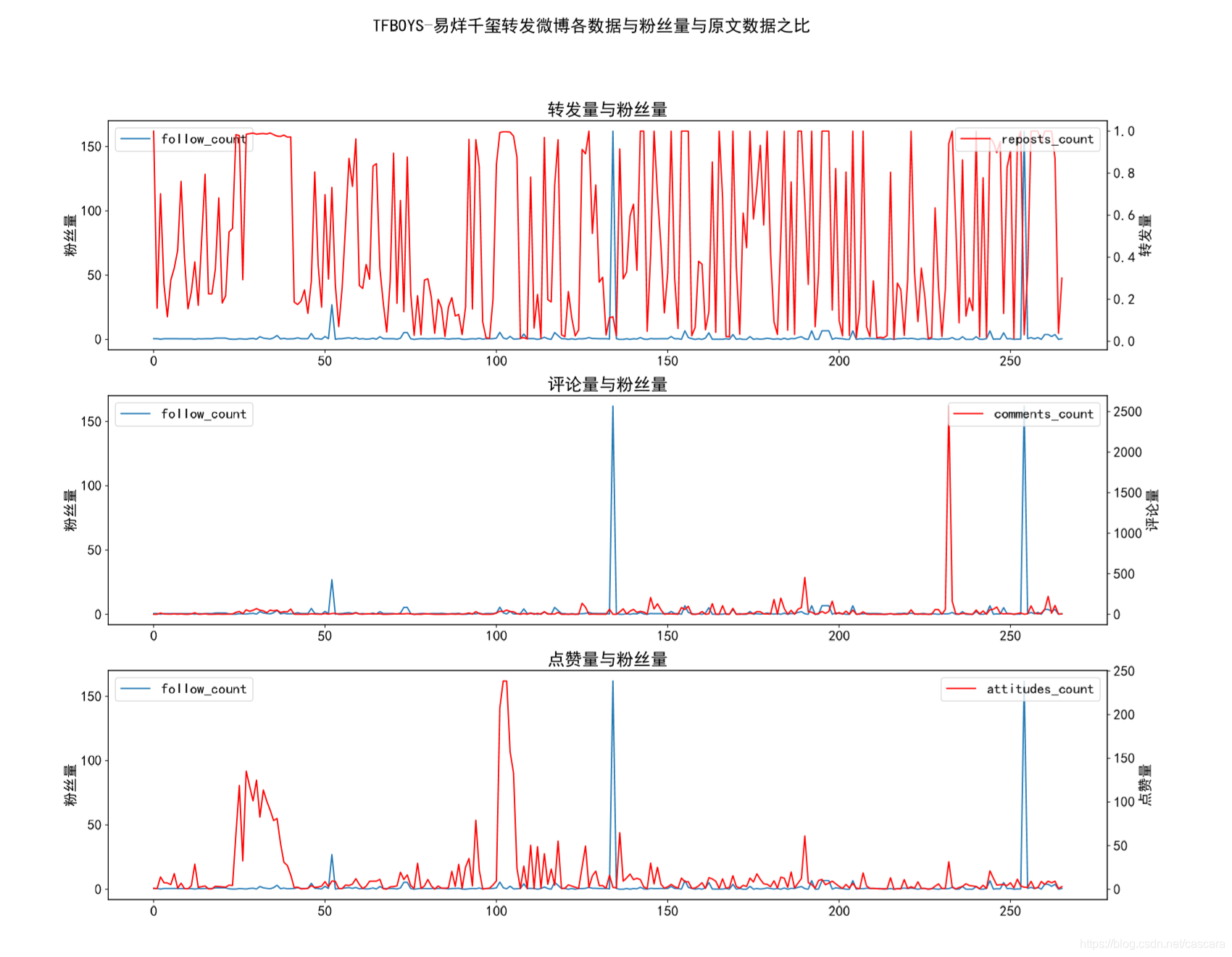
各数据量与粉丝量之比
这里是想观测何种数据与粉丝量的相关程度更强,并大致评估数据造假的程度。
不难看出,转发量的相关程度最弱。
在此,也说明一下为什么选则某博主转发的博文进行研究。考虑到一个微博在转发之后再被转发的价值性有所下降。
同时,一条信息的传播能力也和博主的影响力相关,代表影响力的即使粉丝数量。
故一个人的转发数量在高度徘徊很大说明数据造假之嫌:有多少粉丝愿意为了粉丝的热度无脑转发一些无用信息?
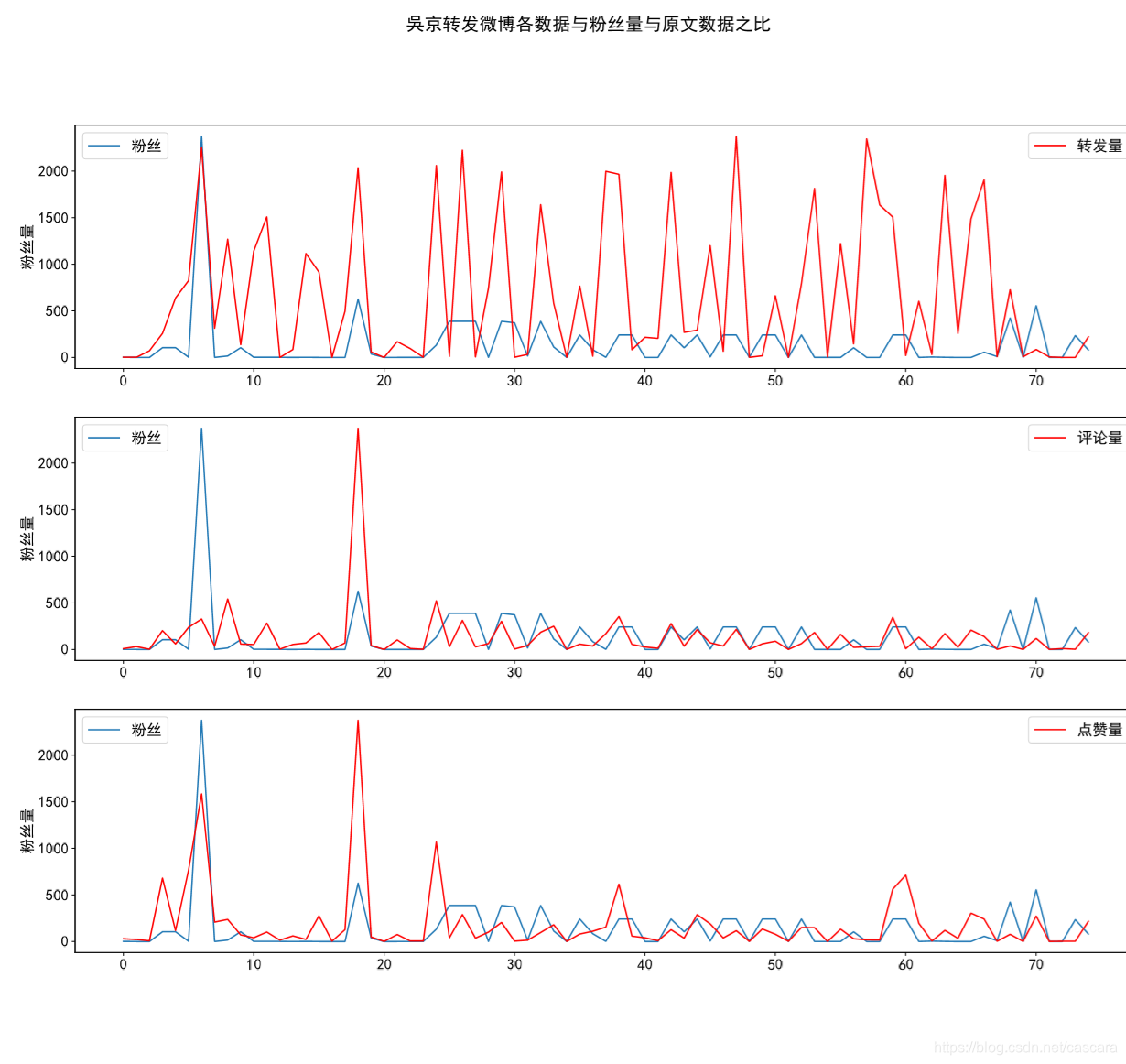
典型博主展示
以下选取不同类别博主对比:
吴京
数据量较少
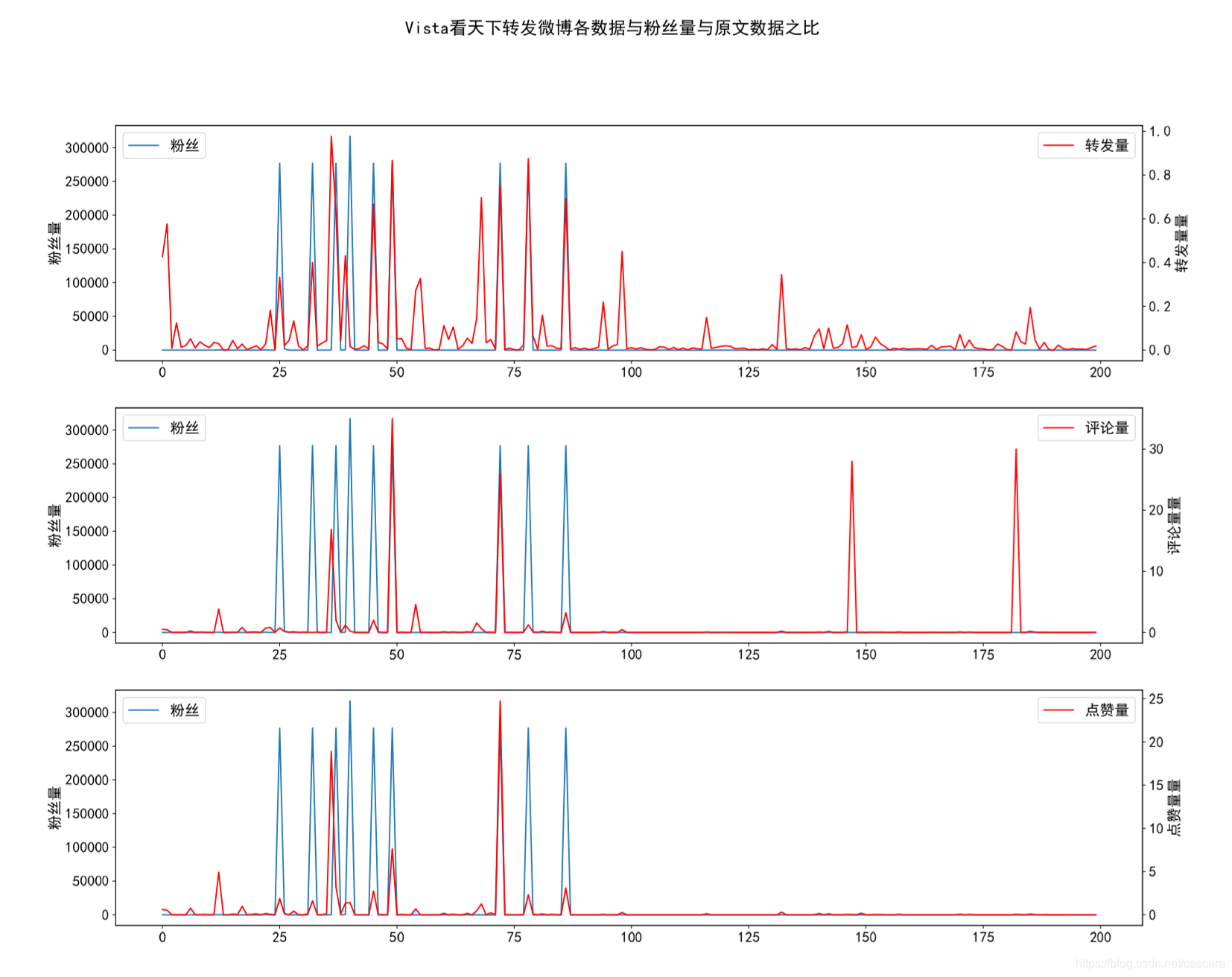
vista看天下
看到过的相关程度最好的一组数据
华中科技大学
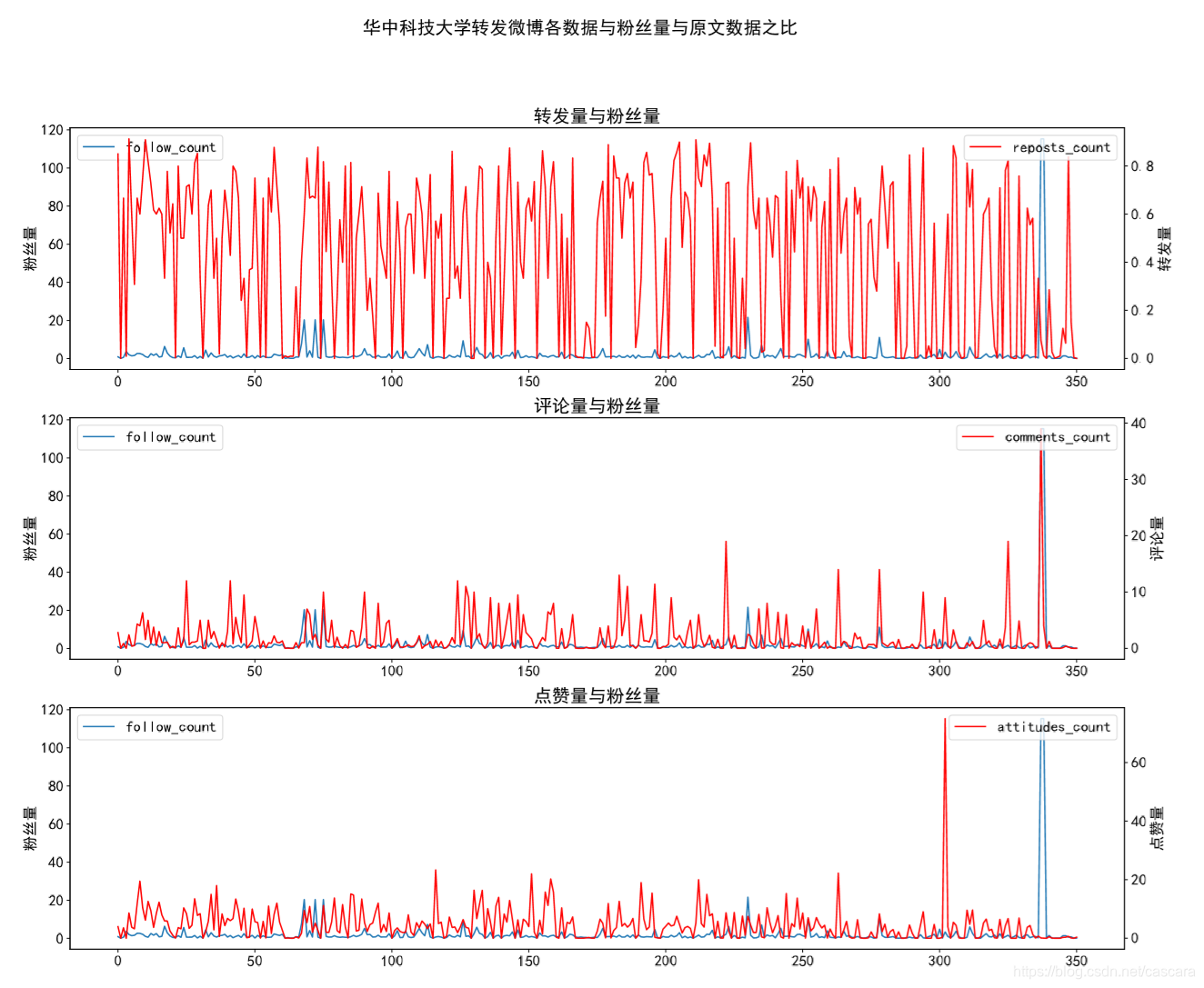
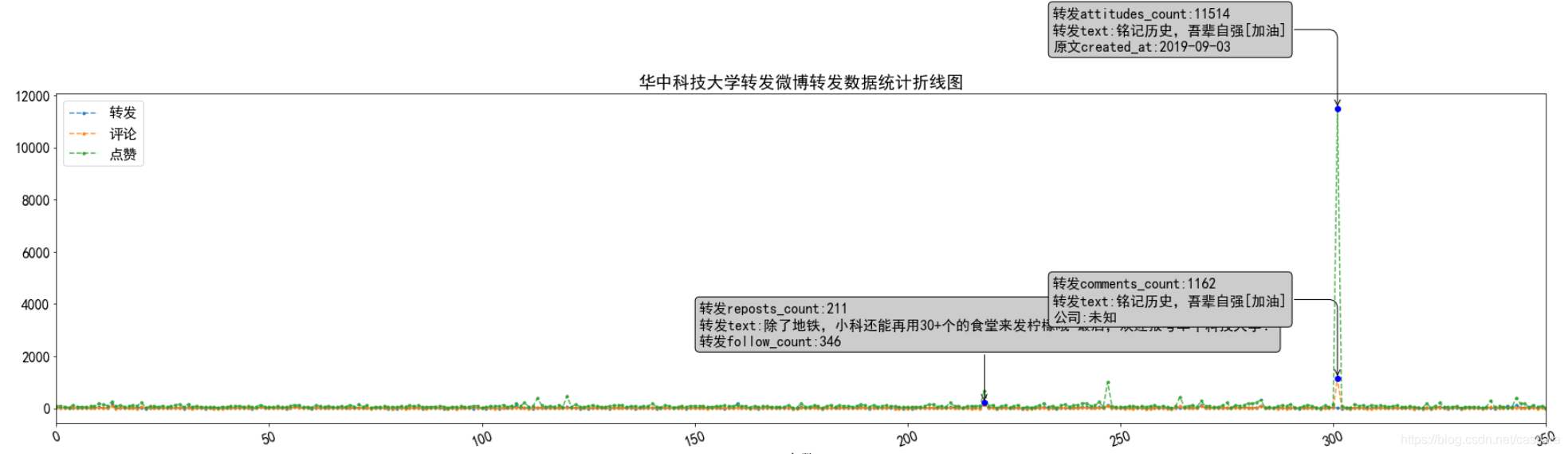
转发量的情况可以分析为一条极端微博的影响,具体观测该微博情况:来自烈士纪念日的一条微博。
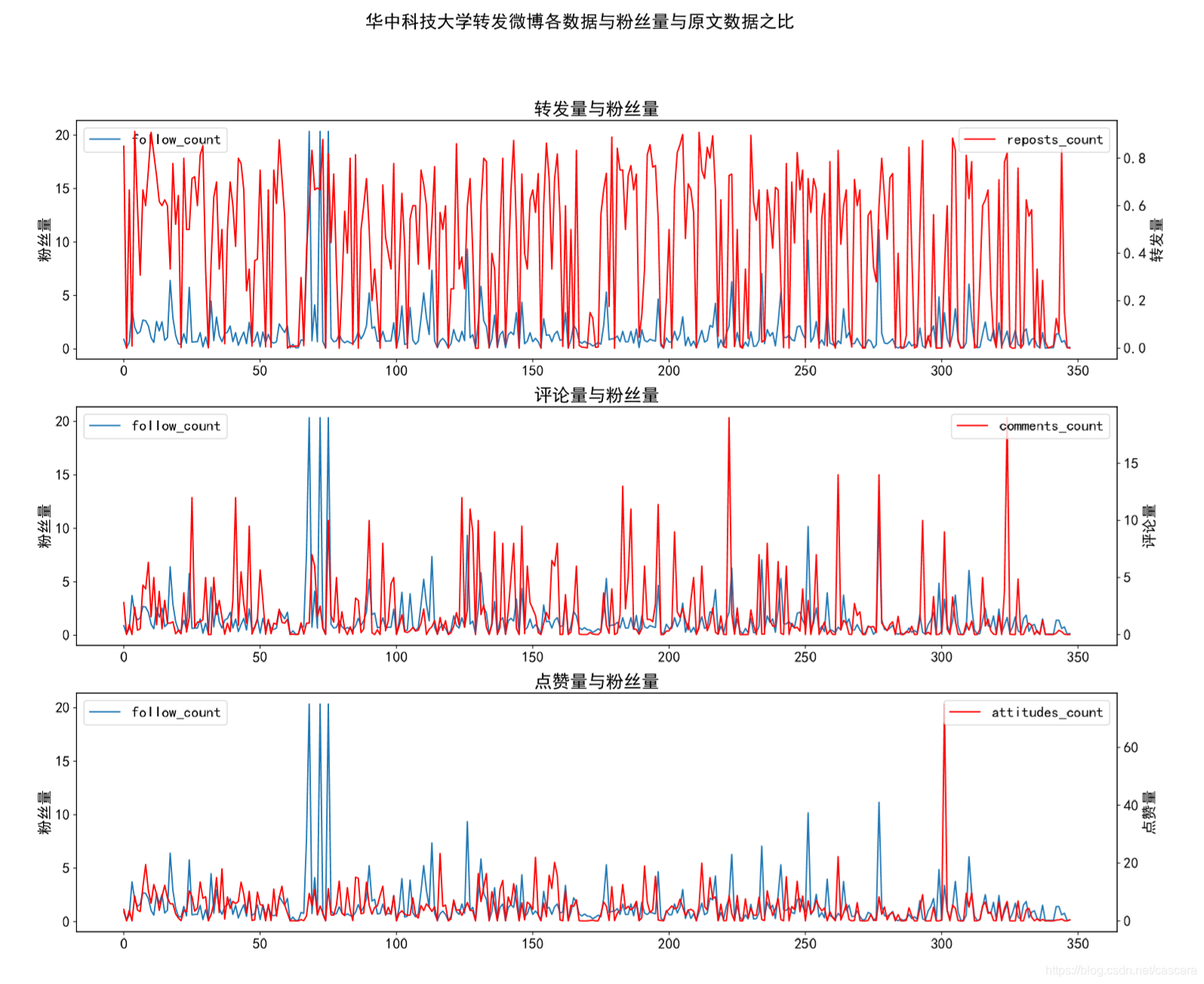
除去几个极端情况,转发量并没有更好的变化,但评论量和点赞量的拟合效果显著提高了。
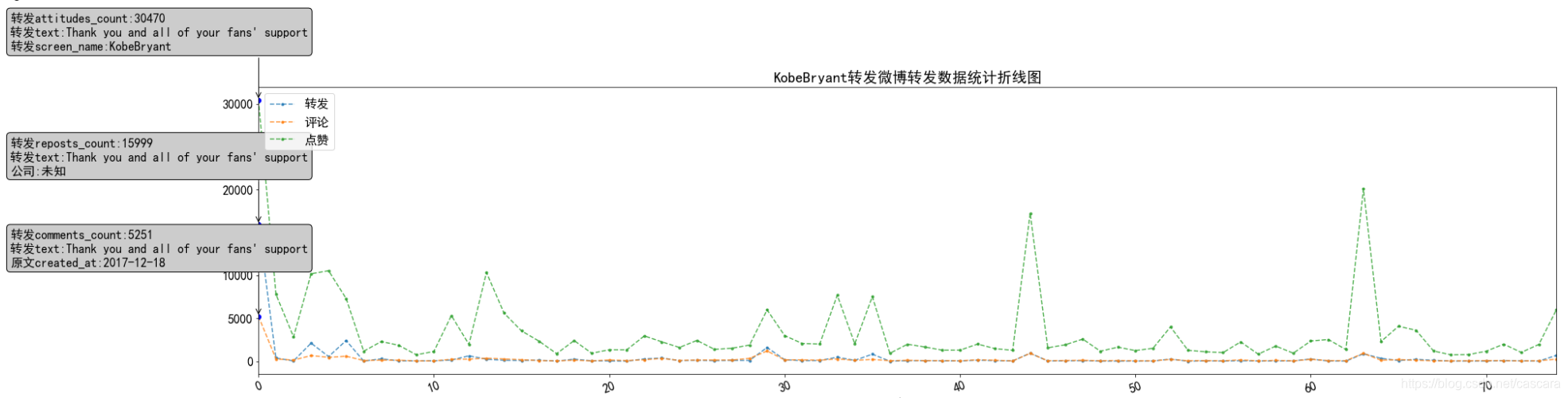
科比
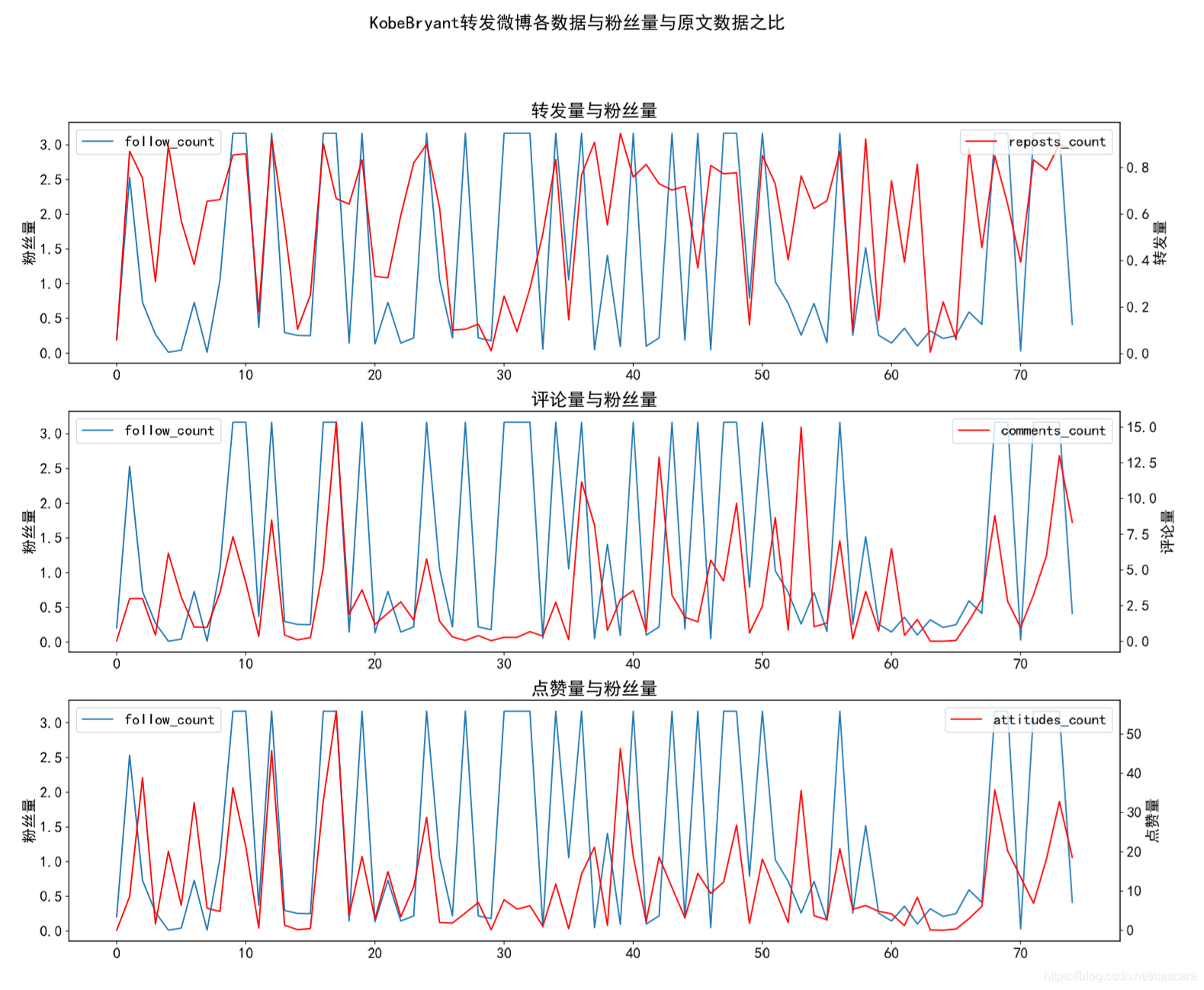
作为国外体育明星,他的微博数据热度在最初达到高峰,代表国人对其的欢迎,之后偶有波澜。














 1110
1110










 暂无认证
暂无认证
























 到【灌水乐园】发言
到【灌水乐园】发言










hello2lin: 博主,想问问如果要在节点上添加该用户转发微博时发的文本,应该怎么操作呀?
387: 你这只能处理一个属性是单个字符的简单情况,如果属性是单词完全没办法处理,太简单了
shirotaka: 博主,现在用你git的代码采集不到数据是因为微博有什么变动吗
GWZZJARVIS: 博主逆时针旋转,这个没问题,旋转一个θ, 但是后边应该是u x v而不是v x u,要不然就是顺时针旋转了 博主改一下
gg1789j: 用正则表达式提取那段运行有问题啊,