图文详解 MapReduce 工作流程

 已于 2023-05-29 21:48:40 修改
已于 2023-05-29 21:48:40 修改
 阅读量9.9w
阅读量9.9w
 收藏
1.1k
收藏
1.1k


 点赞数
182
点赞数
182

前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见 大数据技术体系
正文
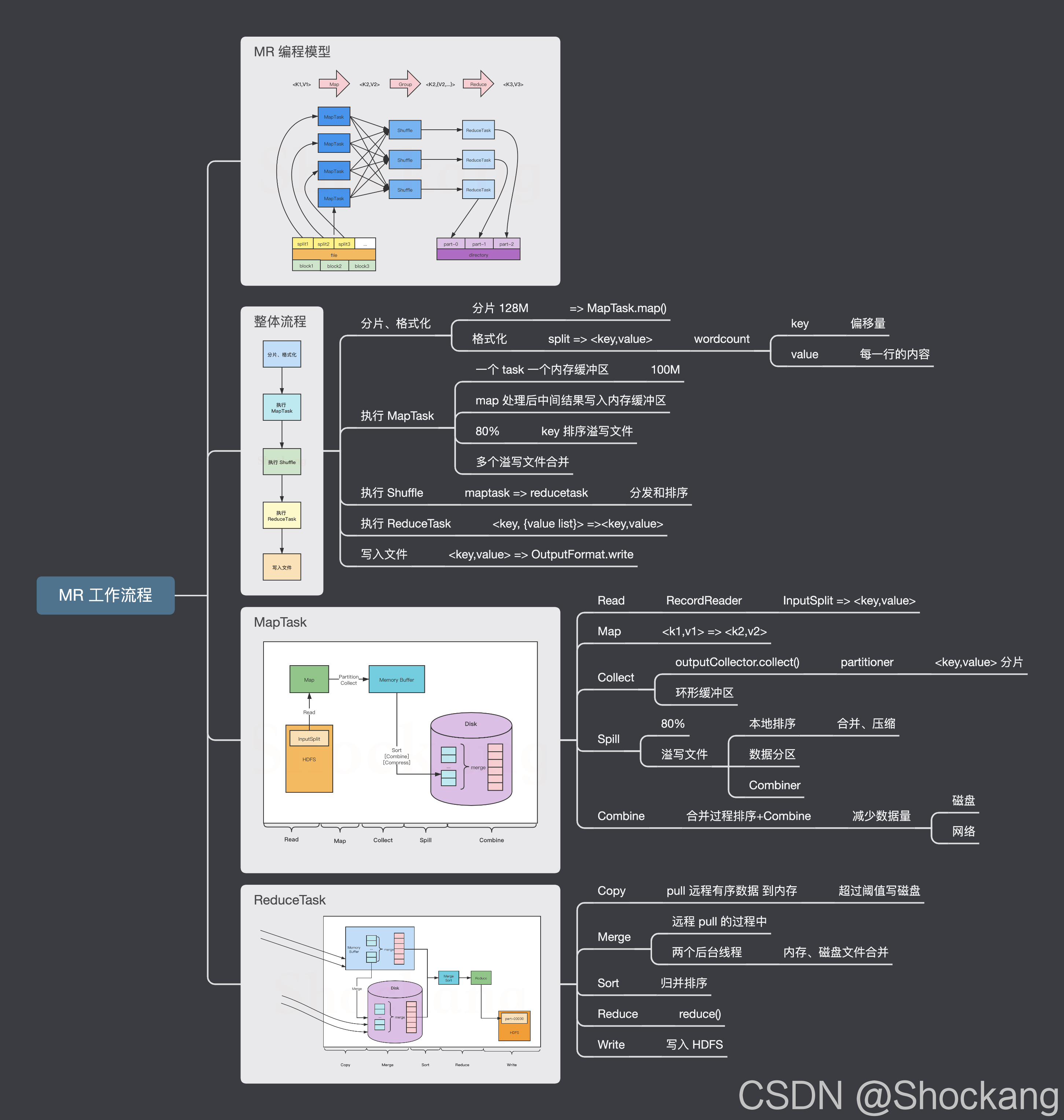
MapReduce 编程模型
MapReduce 编程模型开发简单且功能强大,专门为并行处理大规模数据量而设计,接下来,通过一张图来描述 MapReduce 的工作过程,如图所示。
关于 MapReduce 编程模型的更多细节请参考我的这篇博客—— MapReduce 编程模型到底是怎样的?
整体流程
在上图中, MapReduce 的工作流程大致可以分为5步,具体如下:
分片、格式化数据源
输入 Map 阶段的数据源,必须经过分片和格式化操作。
- 分片操作:指的是将源文件划分为大小相等的小数据块( Hadoop 2.x 中默认 128MB ),也就是分片( split ),
Hadoop 会为每一个分片构建一个 Map 任务,并由该任务运行自定义的 map() 函数,从而处理分片里的每一条记录; - 格式化操作:将划分好的分片( split )格式化为键值对<key,value>形式的数据,其中, key 代表偏移量, value 代表每一行内容。
执行 MapTask
每个 Map 任务都有一个内存缓冲区(缓冲区大小 100MB ),输入的分片( split )数据经过 Map 任务处理后的中间结果会写入内存缓冲区中。
如果写人的数据达到内存缓冲的阈值( 80MB ),会启动一个线程将内存中的溢出数据写入磁盘,同时不影响 Map 中间结果继续写入缓冲区。
在溢写过程中, MapReduce 框架会对 key 进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件,如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
执行 Shuffle 过程
MapReduce 工作过程中, Map 阶段处理的数据如何传递给 Reduce 阶段,这是 MapReduce 框架中关键的一个过程,这个过程叫作 Shuffle 。
Shuffle 会将 MapTask 输出的处理结果数据分发给 ReduceTask ,并在分发的过程中,对数据按 key 进行分区和排序。
执行 ReduceTask
输入 ReduceTask 的数据流是<key, {value list}>形式,用户可以自定义 reduce()方法进行逻辑处理,最终以<key, value>的形式输出。
写入文件
MapReduce 框架会自动把 ReduceTask 生成的<key, value>传入 OutputFormat 的 write 方法,实现文件的写入操作。
MapTask
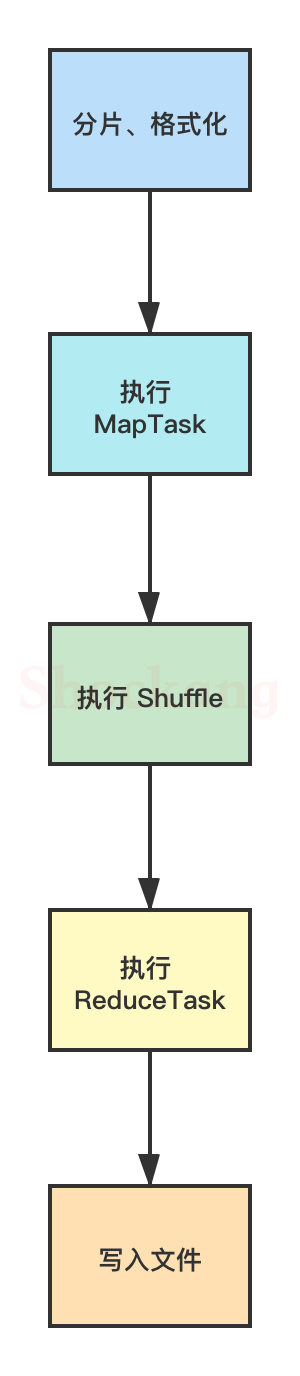
- Read 阶段: MapTask 通过用户编写的 RecordReader ,从输入的 InputSplit 中解析出一个个 key / value 。
- Map 阶段:将解析出的 key / value 交给用户编写的 Map ()函数处理,并产生一系列新的 key / value 。
- Collect 阶段:在用户编写的 map() 函数中,数据处理完成后,一般会调用 outputCollector.collect() 输出结果,在该函数内部,它会将生成的 key / value 分片(通过调用 partitioner ),并写入一个环形内存缓冲区中(该缓冲区默认大小是 100MB )。
- Spill 阶段:即“溢写”,当缓冲区快要溢出时(默认达到缓冲区大小的 80 %),会在本地文件系统创建一个溢出文件,将该缓冲区的数据写入这个文件。
将数据写入本地磁盘前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
写入磁盘之前,线程会根据 ReduceTask 的数量,将数据分区,一个 Reduce 任务对应一个分区的数据。
这样做的目的是为了避免有些 Reduce 任务分配到大量数据,而有些 Reduce 任务分到很少的数据,甚至没有分到数据的尴尬局面。
如果此时设置了 Combiner ,将排序后的结果进行 Combine 操作,这样做的目的是尽可能少地执行数据写入磁盘的操作。
- Combine 阶段:当所有数据处理完成以后, MapTask 会对所有临时文件进行一次合并,以确保最终只会生成一个数据文件
合并的过程中会不断地进行排序和 Combine 操作,
其目的有两个:一是尽量减少每次写人磁盘的数据量;二是尽量减少下一复制阶段网络传输的数据量。
最后合并成了一个已分区且已排序的文件。
ReduceTask

- Copy 阶段: Reduce 会从各个 MapTask 上远程复制一片数据(每个 MapTask 传来的数据都是有序的),并针对某一片数据,如果其大小超过一定國值,则写到磁盘上,否则直接放到内存中
- Merge 阶段:在远程复制数据的同时, ReduceTask 会启动两个后台线程,分别对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘文件过多。
- Sort 阶段:用户编写 reduce() 方法输入数据是按 key 进行聚集的一组数据。
为了将 key 相同的数据聚在一起, Hadoop 采用了基于排序的策略。
由于各个 MapTask 已经实现对自己的处理结果进行了局部排序,因此, ReduceTask 只需对所有数据进行一次归并排序即可。
- Reduce 阶段:对排序后的键值对调用 reduce() 方法,键相等的键值对调用一次 reduce()方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到 HDFS 中
- Write 阶段: reduce() 函数将计算结果写到 HDFS 上。
合并的过程中会产生许多的中间文件(写入磁盘了),但 MapReduce 会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到 Reduce 函数。














 8103
8103











 暂无认证
暂无认证







































 到【灌水乐园】发言
到【灌水乐园】发言










扛着火车兜风i: 我的老哥哥,你太6了
2301_78790639: 没用,我需要的是步骤和命令,你这个纯文字有什么用?
普通网友: 学到了!我也写了一篇获取【大厂面试真题解析、核心开发学习笔记、最新全套讲解视频、实战项目源码讲义、学习路线简历模板】的文章
q842508326: 但是这样的话hive和spark又冲突了,spark的guava版本是低版本
-.-不爱江山爱大饼萌。: 我也想问