【Spark编程基础】

小手の冰凉
 已于 2023-04-03 09:40:24 修改
已于 2023-04-03 09:40:24 修改
 阅读量995
阅读量995
 收藏
6
收藏
6
 点赞数
点赞数
已于 2023-04-03 09:40:24 修改
阅读量995
收藏
6

 点赞数
点赞数
于 2023-03-06 09:42:53 首次发布

文章目录
- 大数据技术概述
- 1.1 大数据时代
- 1.1.1第三次信息化浪潮
- 1.1.2信息科技为大数据时代提供技术支撑
- 1.1.3数据产生方式的变革促成大数据时代的来临
- 1.2 大数据概念
- 1.2.1 数据量大
- 1.2.2 数据类型繁多
- 1.2.3 处理速度快
- 1.2.4 价值密度低
- 1.3 大数据的影响
- 1.4 大数据关键技术
- 1.5 大数据计算模式
- 1.6 代表性大数据技术
- 1.6.1 Hadoop
- 1.6.2 Spark
- 1.6.3 Flink
- 1.6.4 Beam
- 第2章 Spark设计与运行原理
- 2.1 Spark概述
- 2.1.1 Spark简介
- 2.1.2 Spark与Hadoop对比
- 2.2 Spark生态系统
- 2.3 Spark运行架构
- 2.3.1 基本概念
- 2.3.2 架构设计
- 2.3.3 Spark运行基本流程
- 2.3.4 RDD设计与运行原理
- 2.4 Spark的部署方式
- 第3章 Spark环境搭建和使用方法
- 3.1 安装Spark
- 3.1.1 基础环境
- 3.1.2 下载安装文件
- 3.1.3 配置相关文件
- 3.1.4 Spark 和 Hadoop 的交互
- 3.2 在 PySpark 中运行代码
- 3.2.1 PySpark 命令
- 3.3 开发 Spark 独立应用程序
- 3.3.1 安装编译打包工具
- 3.4 Spark集群环境搭建
- 3.5 在集群上运行Spark应用陈旭
- 3.5.1 启动Spark集群
- 3.5.2 采用独立集群管理器
- 3.5.3 采用Hadoop YARN管理器
- 第4章 RDD编程
- 4.1 RDD编程基础
- 4.1.1 RDD创建
- 4.1.2 RDD操作
- 4.1.3 持续化
- 4.1.4 分区
- 4.1.5 一个综合案例
- 4.2 键值对RDD
- 4.3 数据读写
- 4.3.1 文件数据读写
- 4.3.2 读写HBase数据
- 4.4 综合案例
- Tip of SparkPython
- 4.4.1 案例1:求TOP值
- 4.4.2 案例2:文件排序
- 4.4.3 案例3:二次排序
大数据技术概述
1.1 大数据时代
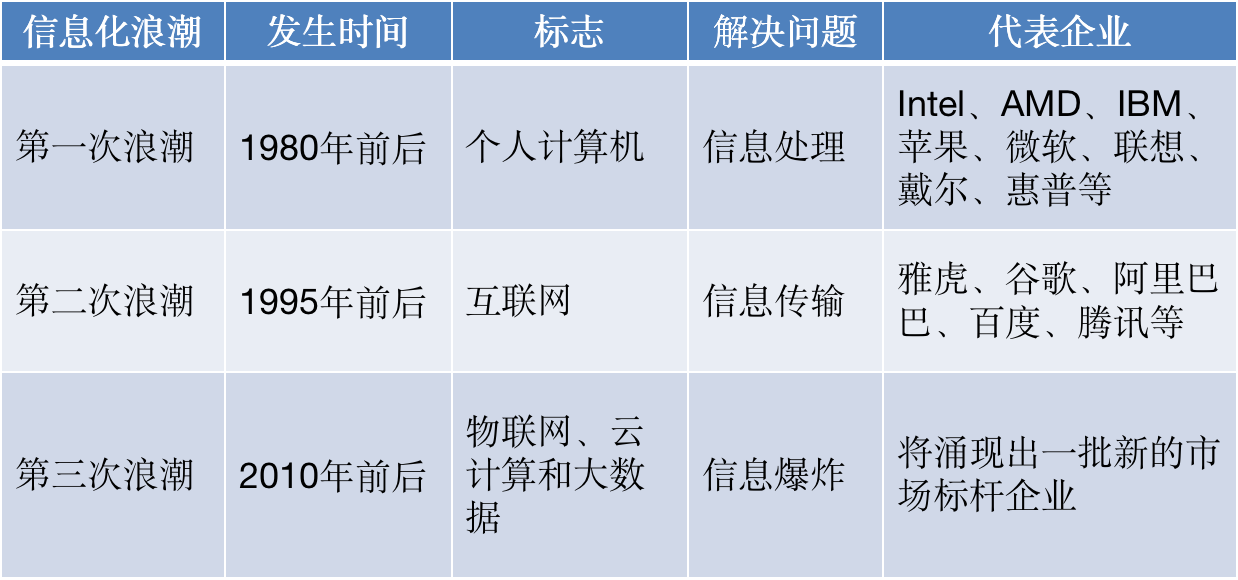
1.1.1第三次信息化浪潮
- 根据IBM前首席执行官郭士纳的观点,IT领域每隔十五年就会迎来一次重大变革
1.1.2信息科技为大数据时代提供技术支撑
-
- 存储设备容量不断增加
-
- CPU处理能力大幅提升
-
- 网络带宽不断增加
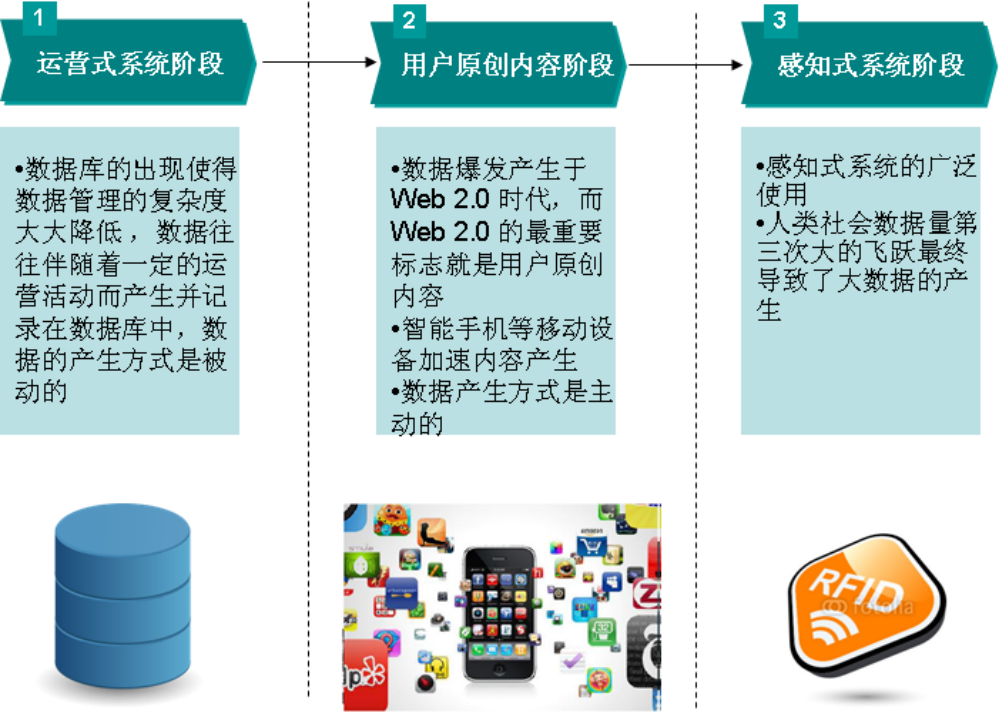
1.1.3数据产生方式的变革促成大数据时代的来临
1.2 大数据概念
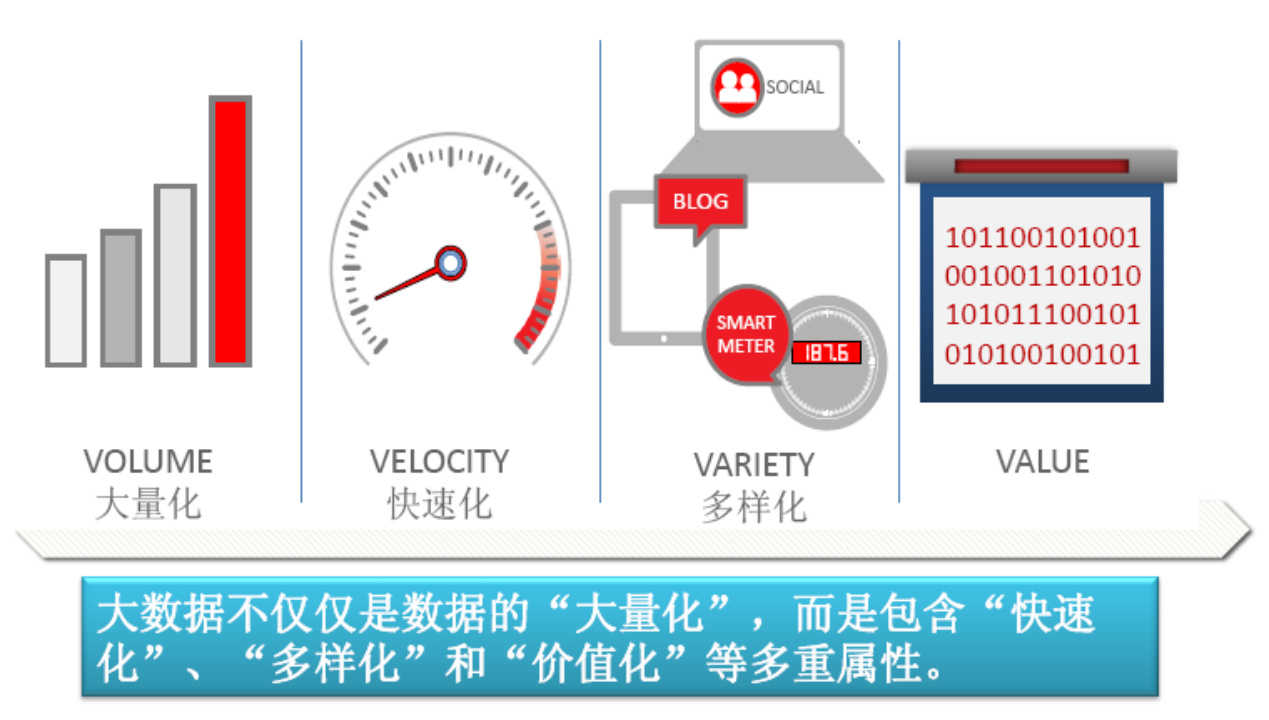
1.2.1 数据量大
- 根据IDC作出的估测,数据一直都在以每年50%的速度增长,也就是说每两年就增长一倍(大数据摩尔定律)(已失效)
- 人类在最近两年产生的数据量相当于之前产生的全部数据量
- 预计到2020年,全球将总共拥有35ZB的数据量,相较于2010年,数据量将增长近30倍
1.2.2 数据类型繁多
- 大数据是由结构化和非结构化数据组成的
- 10%的结构化数据,存储在数据库中
- 90%的非结构化数据,它们与人类信息密切相关
- 应用:
- 科学研究:基因组;LHC 加速器;地球与空间探测
- 企业应用:Email、文档、文件;应用日志;交易记录
- Web 1.0数据:文本、图像、视频
- Web 2.0数据:查询日志/点击流、Twitter/ Blog / SNS、Wiki
1.2.3 处理速度快
- 从数据的生成到消耗,时间窗口非常小,可用于生成决策的时间非常少
- 1秒定律:这一点也是和传统的数据挖掘技术有着本质的不同
1.2.4 价值密度低
- 价值密度低,商业价值高
- 以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒,但是具有很高的商业价值
1.3 大数据的影响
- 图灵奖获得者、著名数据库专家Jim Gray 博士观察并总结人类自古以来,在科学研究上,先后历经了实验、理论、计算和数据四种范式
- 在思维方式方面,大数据完全颠覆了传统的思维方式:
- 全样而非抽样
- 效率而非精确
- 相关而非因果
1.4 大数据关键技术
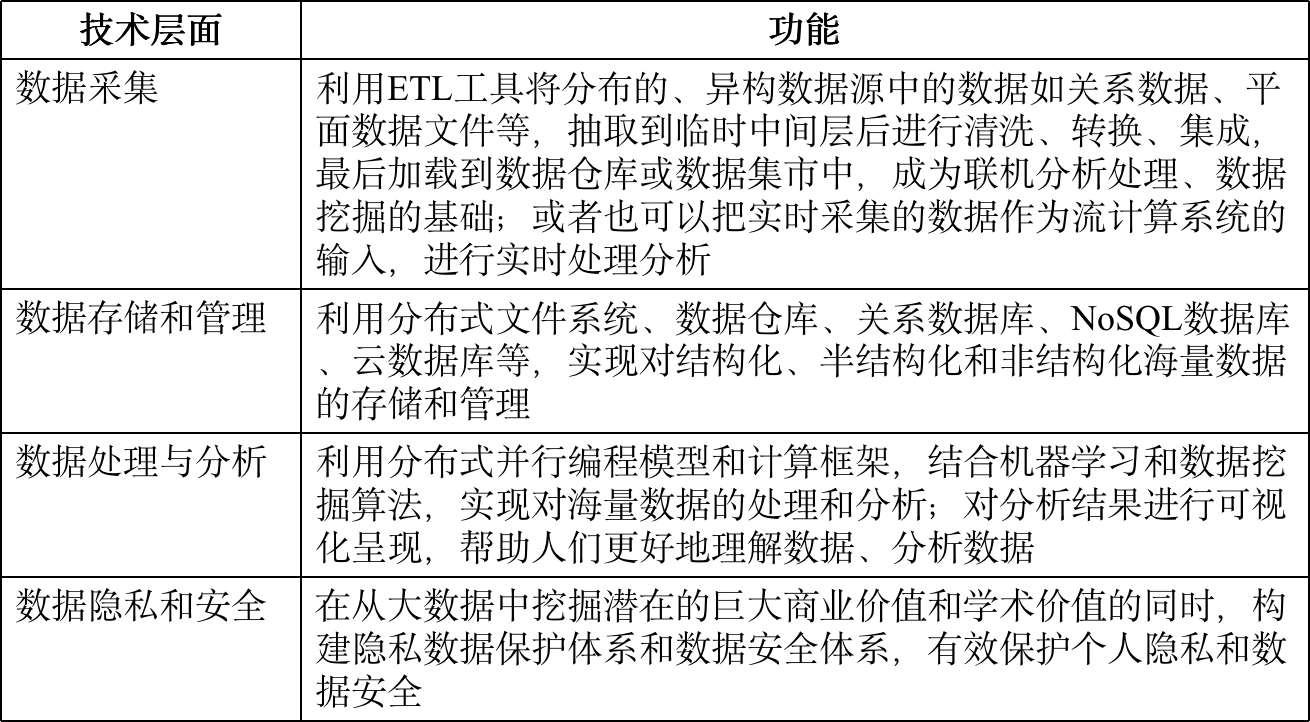
- 两大核心技术

1.5 大数据计算模式
- 大数据计算模式及其代表产品

1.6 代表性大数据技术
1.6.1 Hadoop
-
Hadoop
- Hadoop生态系统

- Hadoop生态系统
-
Hadoop - MapReduce
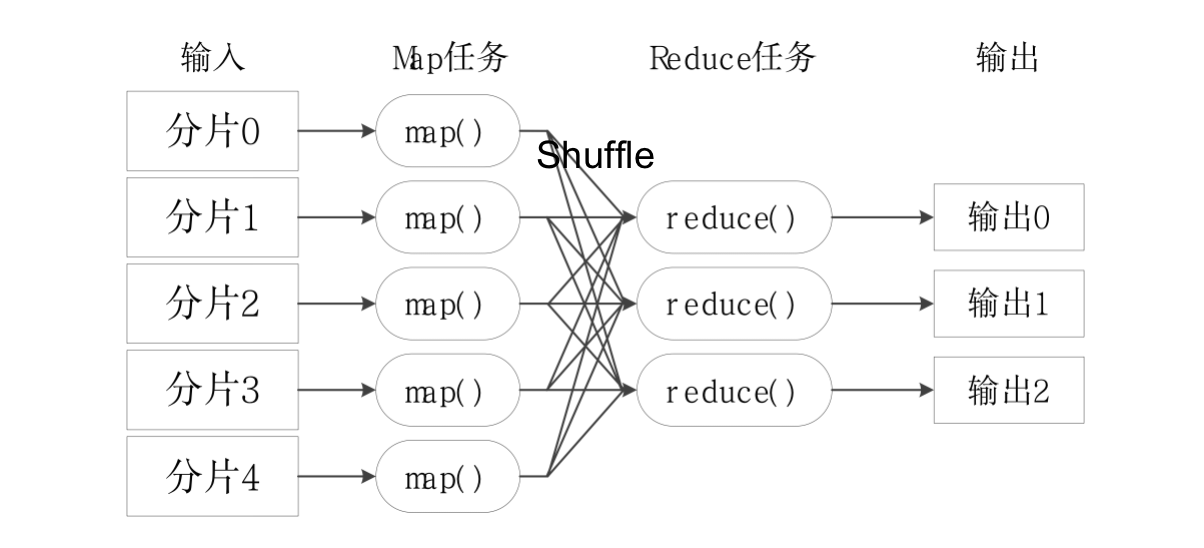
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
- 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
- MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
- MapReduce工作流程:
-
Hadoop - YARN
- YARN的目标就是实现“一个集群多个框架”
- 一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架
- MapReduce实现离线批处理
- 使用Impala实现实时交互式查询分析
- 使用Storm实现流式数据实时分析
- 使用Spark实现迭代计算
- 这些产品通常来自不同的开发团队,具有各自的资源调度管理机制
- 为避免不同类型应用之间互相干扰,企业把内部的服务器拆分成多个集群,分别安装运行不同的计算框架,即“一个框架一个集群”
- 导致问题:
- 集群资源利用率低
- 数据无法共享
- 维护代价高
- YARN的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架
- 由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩
- 可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率
- 不同计算框架可以共享底层存储,避免了数据集跨集群移动
-
在YARN上部署各种计算框架

1.6.2 Spark
- Spark架构图
- Spark生态系统
1.6.3 Flink
1.6.4 Beam
第2章 Spark设计与运行原理
2.1 Spark概述
2.1.1 Spark简介
- Spark特点:运行速度快、容易使用、通用性、运行模式多样
2.1.2 Spark与Hadoop对比
- Hadoop存在的缺点:
- 表达能力有限
- 磁盘IO开销大
- 延迟高
- Spark优点:
- 编程模型更灵活
- 迭代运算效率更高
- 任务调度机制更优
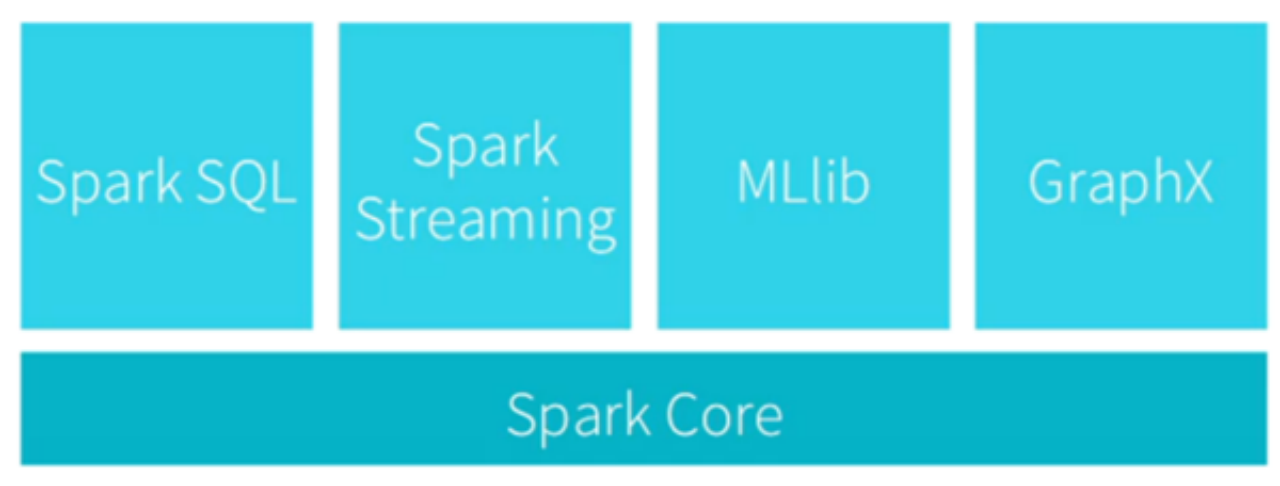
2.2 Spark生态系统
- 大数据处理包括三个类型:
- 复杂的批量数据处理
- 基于历史数据的交互式查询
- 基于实时数据流的数据处理
- 带来的问题:
- 数据转换
- 成本
- 资源调配
- Spark生态系统
- Spark设计遵循理念:一个软件栈满足不同应用场景
- 提供内存计算框架,支持:SQL即席查询、实时流式计算、机器学习、图计算
- Spark可部署在资源管理器YARN之上,提供一站式大数据解决方案
- Spark生态系统支持 批处理、交互式查询、流数据处理
2.3 Spark运行架构
2.3.1 基本概念
2.3.2 架构设计
2.3.3 Spark运行基本流程
2.3.4 RDD设计与运行原理
2.4 Spark的部署方式
第3章 Spark环境搭建和使用方法
3.1 安装Spark
3.1.1 基础环境
- 虚拟机:Ubuntu 22.04
- 【 Hadoop的安装参考「hadoop docs」】(特别是遇到错误问题)
- 机器命名 hadoop 1 2 3, master, slaver 1 2 3
- 安装 JDK17 / JDK11 / JDK8。建议采用 apt 或者 yum 方式,并在 .bashrc 或者 .profile 中正确配置 JAVA_HOME 变量
- 统一修改 hosts文件,使用 scp 传送到各台机器
- 安装权限,放置在同一用户的家目录下(全权权限)
- 家(home)目录:~/
- 生产环境:运维部署指引
- 配置免密登录,方便各台机器切换。 ssh-copy-id
- 所有配置文件都在 etc/hadoop 下,配置包括:
- hadoop-env.sh > JAVA_HOME
- core-site.xml > hdfs地址
- hdfs-site.xml > Namenode节点地址,注意 http:// , replication
- yarn-site.xml > resourcemanage地址
- Mapred-site.xml > 启用yarn
- 所有配置文件修改好,测试之后,再分发到从属机器(scp命令) 所有配置 master → slaver
- 【 问题指引 】
- HDFS问题:
- hdfs
- 多次执行 format操作, 导致id不一致
- HDFS问题:
3.1.2 下载安装文件
- ~~解压安装至路径 /usr/local ~~
- 可以直接解压到家目录下,无需修改权限
3.1.3 配置相关文件
- 配置 Spark 的 classpath ( 建议显示配置 )
3.1.4 Spark 和 Hadoop 的交互
- Spark 部署模式包括:
- Local 模式:本地工作模式
- Standalong 模式:
- YARN 模式:使用 YARN 作为 集群管理器
- Mesos 模式:使用 Mesos 作为 集群管理器
3.2 在 PySpark 中运行代码
3.2.1 PySpark 命令
- pyspark命令机器常用参数:pyspark --master < master-url >
- Spark运行模式取决于传递给 SparkContext 的 Master URL 的值。Master URL可以是以下任意模式
3.3 开发 Spark 独立应用程序
3.3.1 安装编译打包工具
- WordCount.py
3.4 Spark集群环境搭建
3.5 在集群上运行Spark应用陈旭
3.5.1 启动Spark集群
3.5.2 采用独立集群管理器
- 在集群运行应用程序
- 向独立集群管理器提交应用,7077作为主节点参数递给spark-submit
- 运行自带样例程序SparkPi
- 在集群中运行pyspark
3.5.3 采用Hadoop YARN管理器
- 集群中运行应用程序
- 向Hadoop YARN集群管理器提交应用,yarn-client或—作为主节点
- 复制结果地址
- 在集群中运行pyspark
- Tips:
- 在yarn节点上运行SPARK需要设置
- spark
- 将spark/jars 中的 jar包 上传到 hdfs 上的 sparkJars 中
- 在 spark-default.conf 中设置
- spark.yarn.jars hdfs://namenodeip:9000/sparkjars/*.jar
第4章 RDD编程
4.1 RDD编程基础
4.1.1 RDD创建
-
从文件系统中加载数据创建RDD

- 从本地文件系统中加载数据创建RDD

- 从分布式文件系统HDFS中加载数据

- 从本地文件系统中加载数据创建RDD
-
通过并行集合(列表)创建RDD

4.1.2 RDD操作
-
转换操作

-
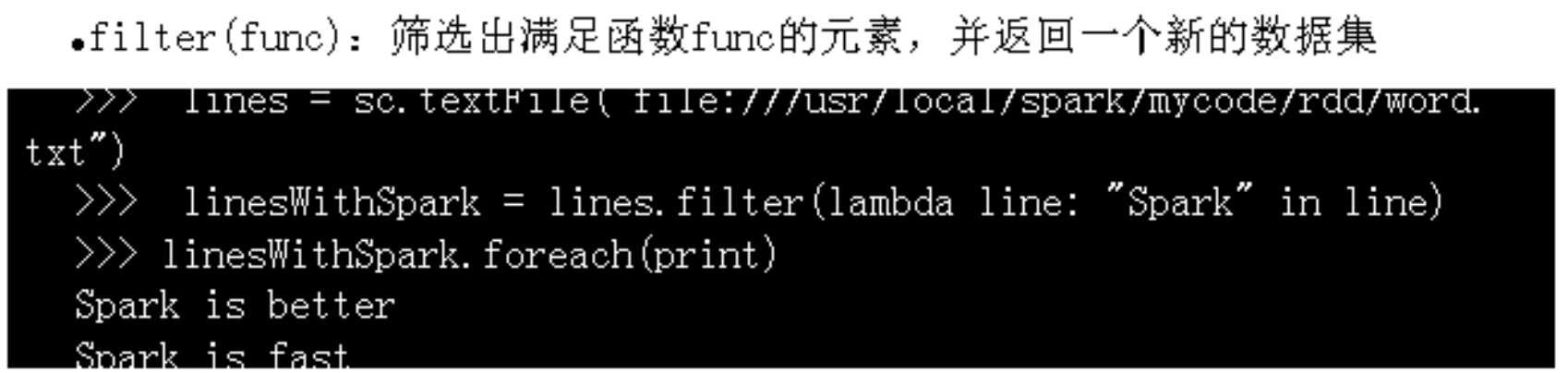
fileter(func):
-
map(func):


-
flatMap(func):

-
groupByKey():
-
reduceByKey():
-
-
行动操作
-
惰性机制
4.1.3 持续化
4.1.4 分区
4.1.5 一个综合案例
4.2 键值对RDD
4.3 数据读写
4.3.1 文件数据读写
- 本地文件系统的数据读写
- 从文件中读取数据创建RDD

- 把RDD写入到文本文件中
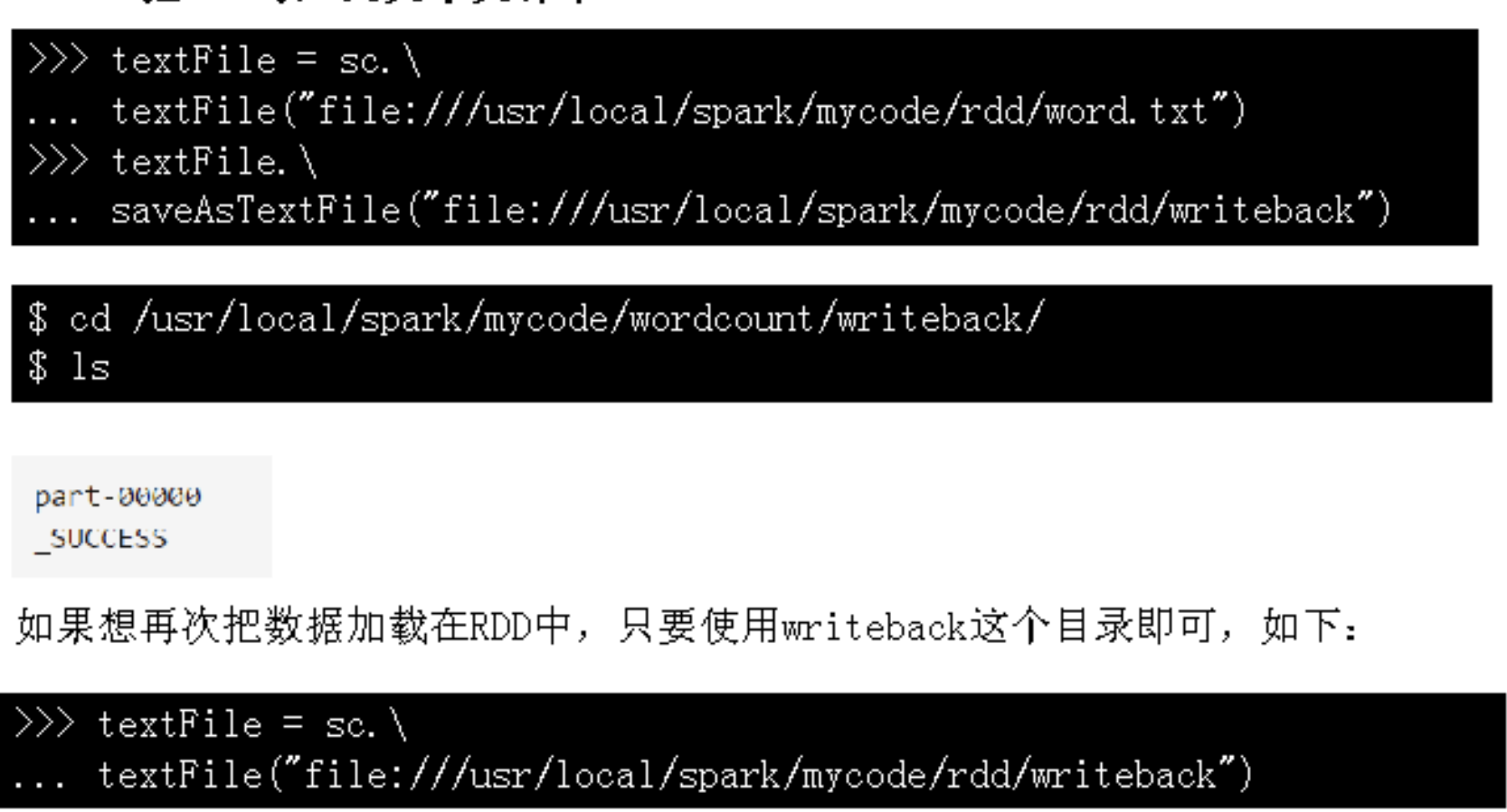
- 从文件中读取数据创建RDD
- 分布式文件系统HDFS的数据读写

4.3.2 读写HBase数据
-
HBase 简介
- Hbase是Google BigTable的开源实现
- 稀疏、多维度、排序的映射表
- 每个值是一个未经解释的字符串,没有数据类型
- 每一行有一个可排序的行间和任意多的列
- 列族支持动态扩展,所有列均以字符串形式存储
- 更新操作不会删除旧版本,而是生成新版本
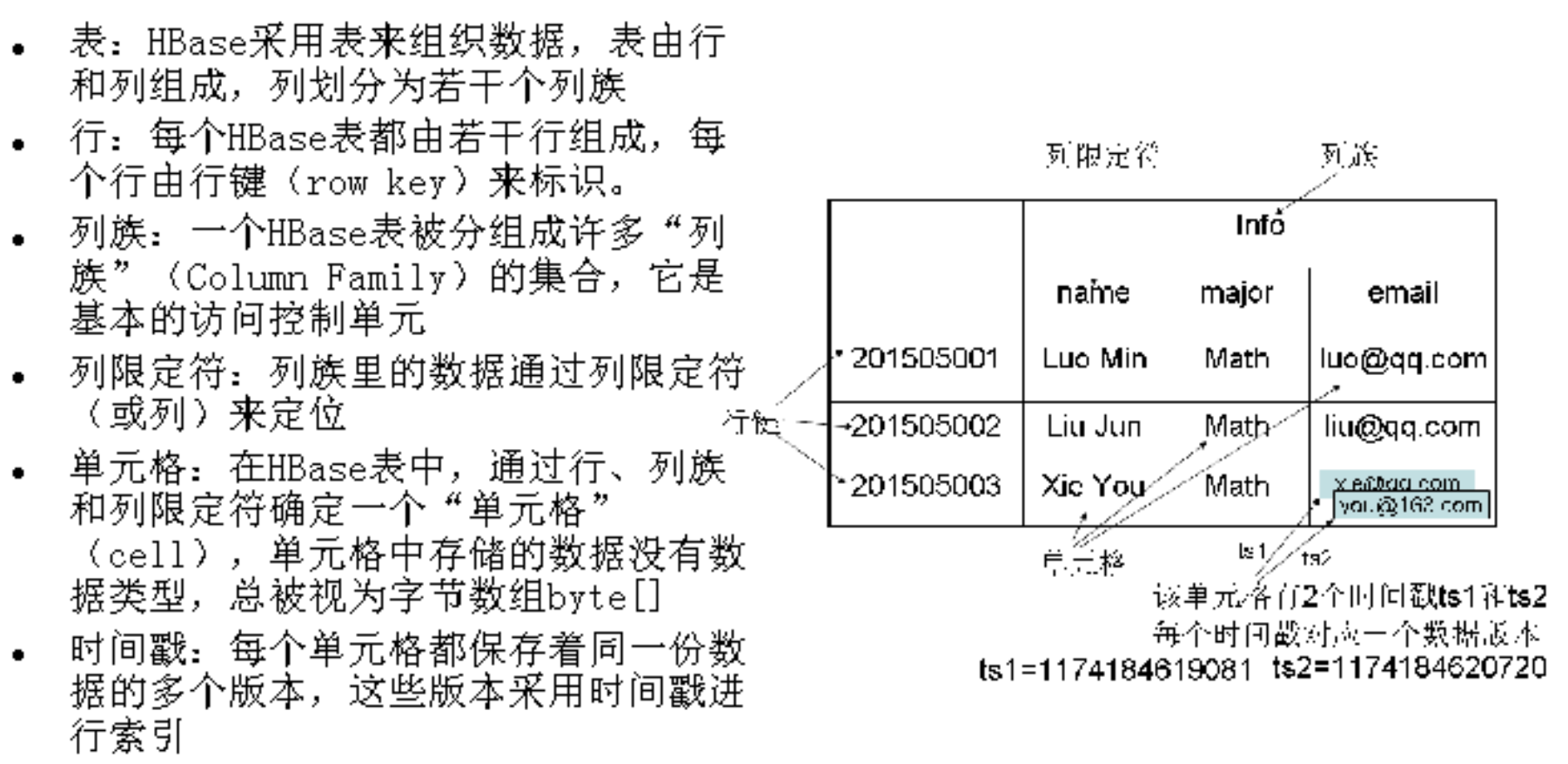
- 表:
- 列族:
- 列限定符:
- 单元格:
- 时间戳:
- 概念视图
- 物理视图
- 列族横向拓展

- 列族横向拓展
-
创建一个HBase表
-
启动

-
创建、录入信息

-
-
配置Spark



-
编写程序读取HBase


-
编写程序向HBase写入数据


4.4 综合案例
Tip of SparkPython
- 什么时候使用RDD
- DataFrame
4.4.1 案例1:求TOP值
- 任务描述















 665
665










 暂无认证
暂无认证
































 到【灌水乐园】发言
到【灌水乐园】发言










小手の冰凉: 可能的解决方法: 1. 修改文件路径读写权限,sudo chmod 777 - R [ path ] 2. MySQL等相关服务未启动,启动mysql服务
小手の冰凉: 这个项目重点放在如何在虚拟机中部署,对于模型没有深入理解,你的问题我无法解答
小手の冰凉: 祝你六级顺利通过
小手の冰凉: 如果你是我的学弟或学妹,数据集应该在老师发的选题文件里,按住ctrl点击数据集图片会跳转到相应数据集文件
小手の冰凉: 写入数据到本地文件X_train.txt