Elasticsearch学习-- 聚合查询

 最新推荐文章于 2024-04-16 10:51:16 发布
最新推荐文章于 2024-04-16 10:51:16 发布
 阅读量2.9k
阅读量2.9k
 收藏
8
收藏
8


 点赞数
4
点赞数
4
一、聚合分类
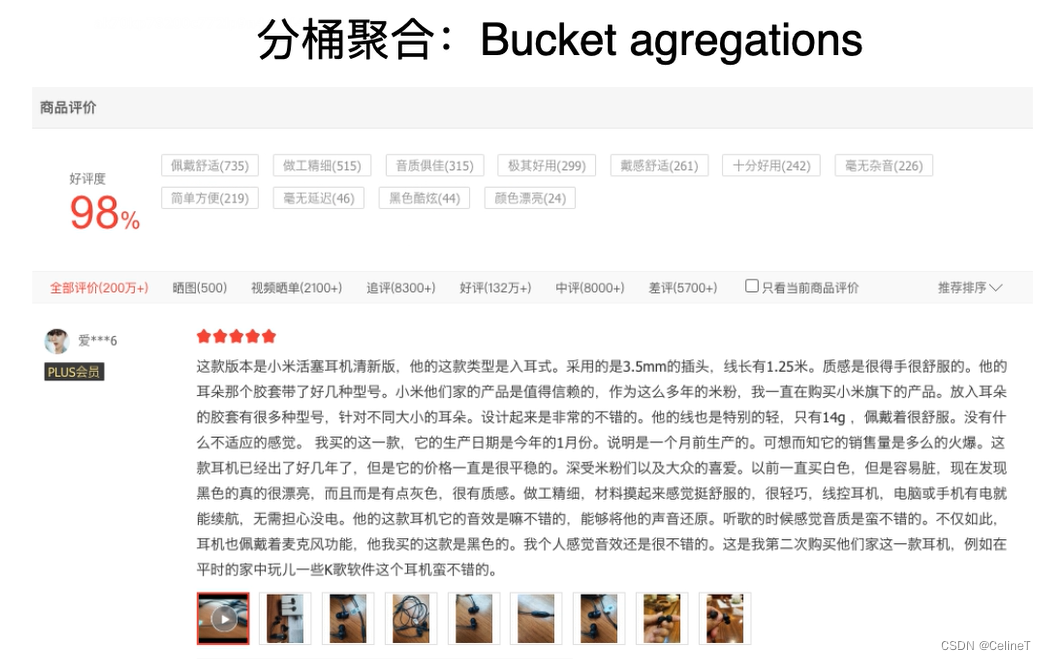
1. 分桶聚合 bucket aggregations
按照每个标签进行分类 ,类似于group by


2. 指标聚合 metrics aggregations

3. 管道聚合 pipeline aggregations

先计算平均值,再计算最小值

二、语法
GET test_index/_search
{
"aggs": {
"聚合后返回的字段": {
"avg": {
"聚合的字段": ""
}
},
"聚合后返回的字段2": {
"avg": {
"聚合的字段": ""
}
}
}
}默认查询返回结果是10条,可以通过设置size来看返回值数量
GET test_index/_search?size=20GET test_index/_search
{
"size":20
}三、桶聚合
1. 统计不同标签的商品数量
PUT product/_doc/1
{
"name":"prodect1 aa",
"price": 1000,
"tags":["tag1","tag2","tag3"]
}
PUT product/_doc/2
{
"name":"prodect2 bb",
"price": 2000,
"tags":["tag2","tag3"]
}
PUT product/_doc/3
{
"name":"prodect3 bb",
"price": 2000,
"tags":["tag4"]
}
PUT product/_doc/4
{
"name":"prodect4 bb",
"price": 3000,
"tags":["tag1","tag4"]
}
PUT product/_doc/5
{
"name":"prodect5 aa",
"price": 3000,
"tags":["tag1","tag5"]
}
PUT product/_doc/6
{
"name":"prodect6 aa",
"price": 4000,
"tags":["tag1","tag2"]
}
GET product/_search
{
"size": 0,
"aggs": {
"agg_tag": {
"terms": {
"field": "tags.keyword",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}

2. 为什么上面使用tags.keyword
因为聚合查询使用的是doc_values的正排索引,tags.keyword有正排索引
也可以通过设置fileddata属性进行正排索引
3. fileddata
修改mapping中tags字段的fileddata属性为true
POST product/_mapping
{
"properties":{
"tags":{
"type":"text",
"fielddata":true
}
}
}
这样就可以使用tags直接进行聚合操作
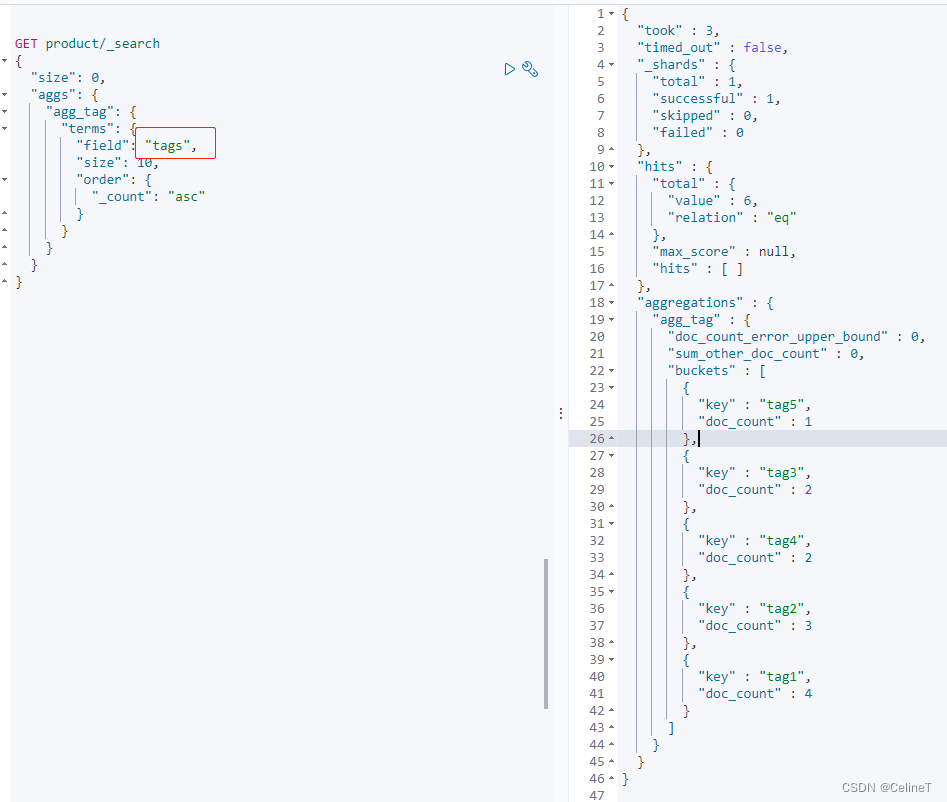
GET product/_search
{
"size": 0,
"aggs": {
"agg_tag": {
"terms": {
"field": "tags",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}
4. doc_values和field_data的区别
doc_values和filed_data都可以用于聚合查询,
doc_vaules是基于磁盘的,filed_data是基于内存的
数据量比较大时,尽量不要使用filed_data
四、指标聚合
1. 统计商品最贵、最便宜、平均价格
GET product/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
},
"avg_price": {
"avg": {
"field": "price"
}
}
}
} 
2. stats 查看所有指标
# 查看price的所有指标
GET product/_search
{
"size": 0,
"aggs": {
"stats_price": {
"stats": {
"field": "price"
}
}
}
}
3. cardinality去重后的数量
# 按照price字段进行去重后的数量
GET product/_search
{
"_source": false,
"aggs": {
"price_count": {
"cardinality": {
"field": "price"
}
}
}
}
五、管道聚合(二次聚合)
统计平均价格最低的商品分类
1)先对tags进行分桶
2)对分桶后的tags取平均price(在哪个的基础上进行操作,就放在同一级)
3)对上面的平均价格取最小平均价格的标签
# 统计平均价格最低的商品分类
GET product/_search
{
"size": 0,
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
},
"aggs":{
"avg_price_bucket":{
"avg": {
"field": "price"
}
}
}
},
"min_price_bucket":{
"min_bucket": {
"buckets_path": "tags_bucket>avg_price_bucket"
}
}
}
}
六、基于聚合结果的聚合--案例
1. 准备数据
11条商品信息
PUT /goods/_doc/1
{
"name" : "小米手机",
"desc" : "手机中的战斗机",
"price" : 3999,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-10-01T08:00:00Z",
"tags": [ "性价比", "发烧", "不卡顿" ]
}
PUT /goods/_doc/2
{
"name" : "小米NFC手机",
"desc" : "支持全功能NFC,手机中的滑翔机",
"price" : 4999,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-05-21T08:00:00Z",
"tags": [ "性价比", "发烧", "公交卡" ]
}
PUT /goods/_doc/3
{
"name" : "NFC手机",
"desc" : "手机中的轰炸机",
"price" : 2999,
"lv":"高端机",
"type":"手机",
"createtime":"2020-06-20",
"tags": [ "性价比", "快充", "门禁卡" ]
}
PUT /goods/_doc/4
{
"name" : "小米耳机",
"desc" : "耳机中的黄焖鸡",
"price" : 999,
"lv":"百元机",
"type":"耳机",
"createtime":"2020-06-23",
"tags": [ "降噪", "防水", "蓝牙" ]
}
PUT /goods/_doc/5
{
"name" : "红米耳机",
"desc" : "耳机中的肯德基",
"price" : 399,
"type":"耳机",
"lv":"百元机",
"createtime":"2020-07-20",
"tags": [ "防火", "低音炮", "听声辨位" ]
}
PUT /goods/_doc/6
{
"name" : "小米手机10",
"desc" : "充电贼快掉电更快,超级无敌望远镜,高刷电竞屏",
"price" : "",
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-07-27",
"tags": [ "120HZ刷新率", "120W快充", "120倍变焦" ]
}
PUT /goods/_doc/7
{
"name" : "挨炮 SE2",
"desc" : "除了CPU,一无是处",
"price" : "3299",
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-07-21",
"tags": [ "割韭菜", "割韭菜", "割新韭菜" ]
}
PUT /goods/_doc/8
{
"name" : "XS Max",
"desc" : "听说要出新款12手机了,终于可以换掉手中的4S了",
"price" : 4399,
"lv":"旗舰机",
"type":"手机",
"createtime":"2020-08-19",
"tags": [ "5V1A", "4G全网通", "大" ]
}
PUT /goods/_doc/9
{
"name" : "小米电视",
"desc" : "70寸性价比只选,不要一万八,要不要八千八,只要两千九百九十八",
"price" : 2998,
"lv":"高端机",
"type":"耳机",
"createtime":"2020-08-16",
"tags": [ "巨馍", "家庭影院", "游戏" ]
}
PUT /goods/_doc/10
{
"name" : "红米电视",
"desc" : "我比上边那个更划算,我也2998,我也70寸,但是我更好看",
"price" : 2999,
"type":"电视",
"lv":"高端机",
"createtime":"2020-08-28",
"tags": [ "大片", "蓝光8K", "超薄" ]
}
PUT /goods/_doc/11
{
"name": "红米电视",
"desc": "我比上边那个更划算,我也2998,我也70寸,但是我更好看",
"price": 2998,
"type": "电视",
"lv": "高端机",
"createtime": "2020-08-28",
"tags": [
"大片",
"蓝光8K",
"超薄"
]
}
2. 统计不同lv下的不同type的数量
# 统计不同lv下的不同type的数量
GET goods/_search
{
"size": 0,
"aggs": {
"lv_type_agg": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"type_agg": {
"terms": {
"field": "type.keyword"
}
}
}
}
}
}
3. 统计不同lv的价格信息
# 统计不同lv下价格信息
GET goods/_search
{
"size": 0,
"aggs": {
"lv_type_agg": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"price_agg": {
"stats": {
"field": "price"
}
}
}
}
}
}
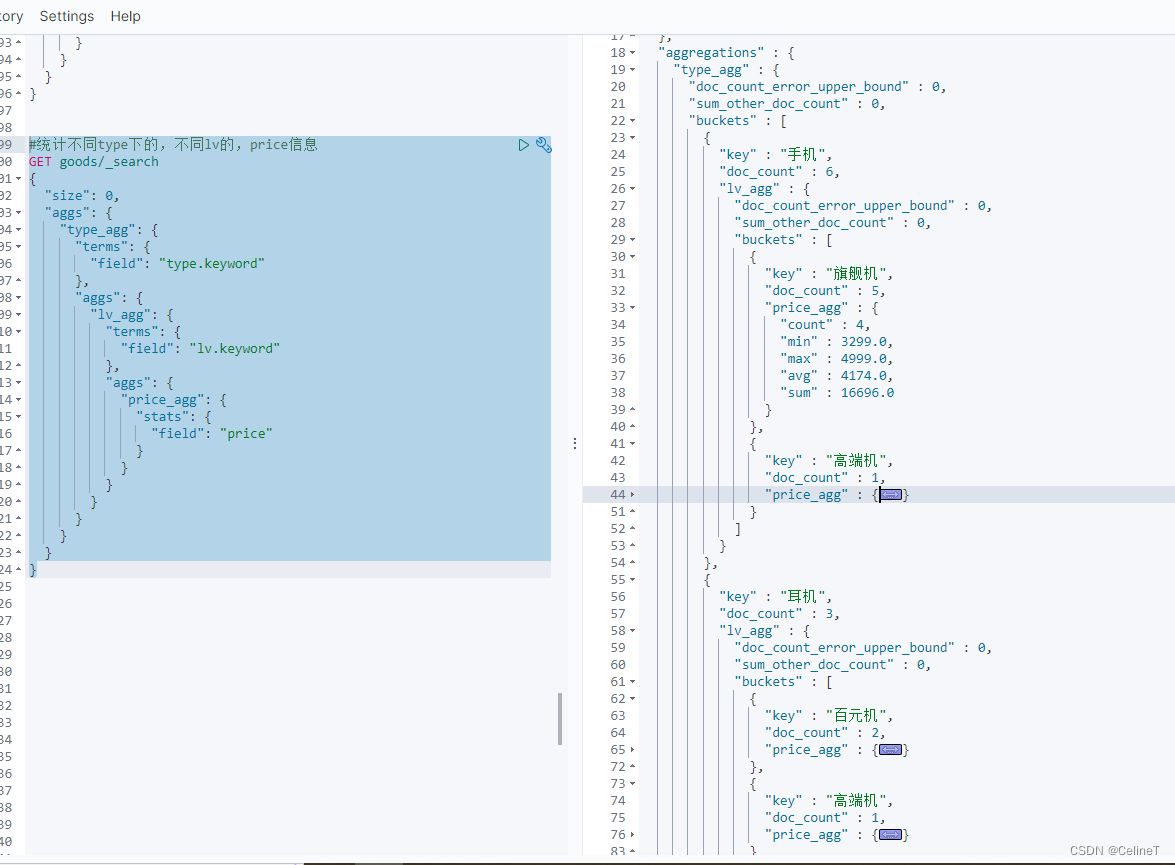
4. 统计不同type下的,不同lv的,price信息
#统计不同type下的,不同lv的,price信息
GET goods/_search
{
"size": 0,
"aggs": {
"type_agg": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"lv_agg": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"price_agg": {
"stats": {
"field": "price"
}
}
}
}
}
}
}
}
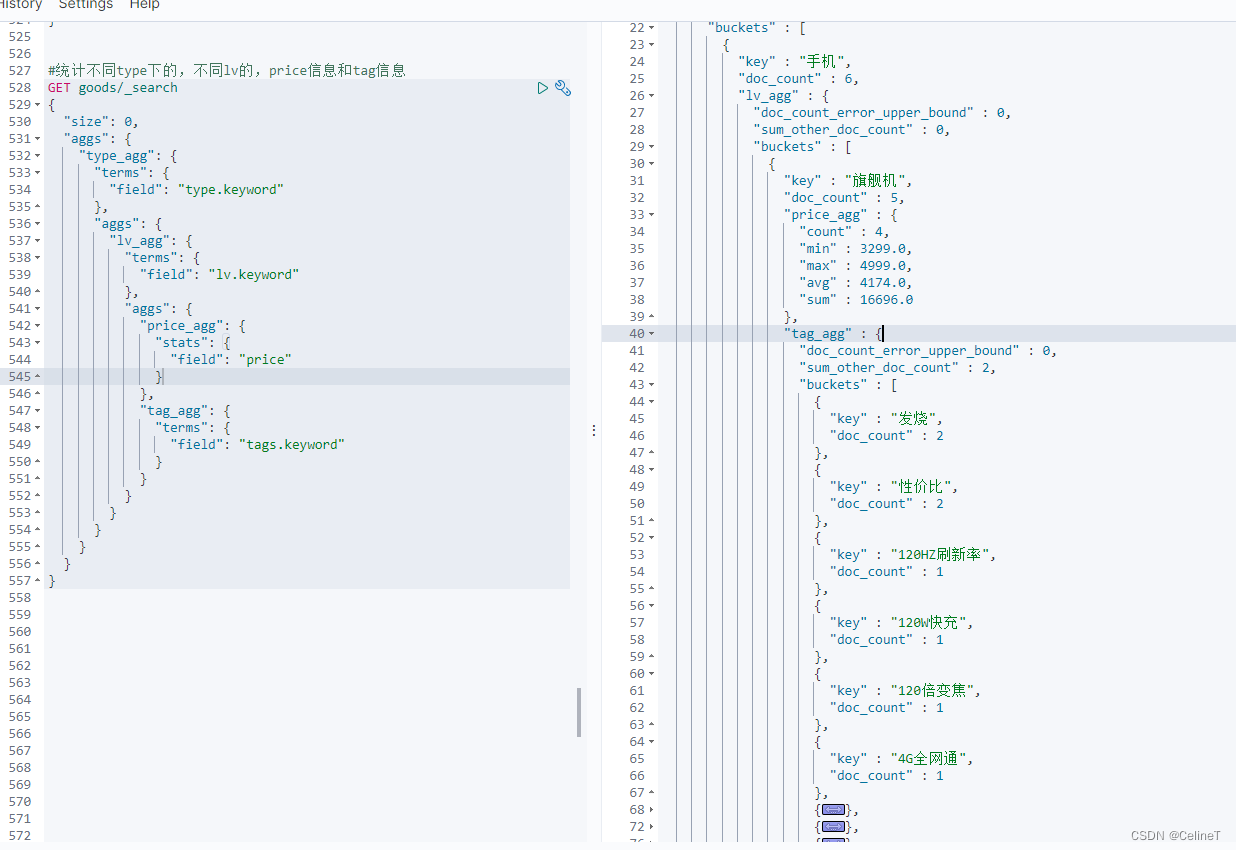
统计不同type下的,不同lv的,price信息和tag信息
#统计不同type下的,不同lv的,price信息和tag信息
GET goods/_search
{
"size": 0,
"aggs": {
"type_agg": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"lv_agg": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"price_agg": {
"stats": {
"field": "price"
}
},
"tag_agg": {
"terms": {
"field": "tags.keyword"
}
}
}
}
}
}
}
} 
5. 统计每个商品type中,不同的lv商品中,平均price最低的lv
# 统计每个商品type中,不同的lv商品中,平均price最低的lv
GET goods/_search
{
"size": 0,
"aggs": {
"type_agg": {
"terms": {
"field": "type.keyword"
},
"aggs": {
"lv_agg": {
"terms": {
"field": "lv.keyword"
},
"aggs": {
"price_agg": {
"avg": {
"field": "price"
}
}
}
},
"min_price_bucket": {
"min_bucket": {
"buckets_path": "lv_agg>price_agg"
}
}
}
}
}
}
七、基于查询结果的聚合和基于聚合结果的查询--案例
1. 基于查询结果的聚合
1)查询price>4000的tags信息
GET goods/_search
{
"size": 10,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}
2) 基于filter
与上面的结果一样
GET goods/_search
{
"size": 10,
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 4000
}
}
}
}
},
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}2. 基于聚合结果的查询
使用post_filter
GET goods/_search
{
"size": 10,
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
},
"post_filter": {
"term": {
"tags.keyword": "性价比"
}
}
}GET goods/_search
{
"size": 10,
"query": {
"term": {
"tags.keyword": {
"value": "性价比"
}
}
},
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}以上两个语句,查询结果相同
1)查询price>4000的平均price和所有商品的平均price
#查询price>4000的平均price和所有商品的平均price
GET goods/_search
{
"size": 0,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price":{
"global": {},
"aggs":{
"avg_price2":{
"avg": {
"field": "price"
}
}
}
}
}
}
2) 将上面的global换成filter的话,是与最上面的查询条件产生交集
GET goods/_search
{
"size": 0,
"query": {
"range": {
"price": {
"gte": 4000
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price":{
"filter": {
"range": {
"price": {
"lte": 3000
}
}
},
"aggs":{
"avg_price2":{
"avg": {
"field": "price"
}
}
}
}
}
}
八、聚合排序
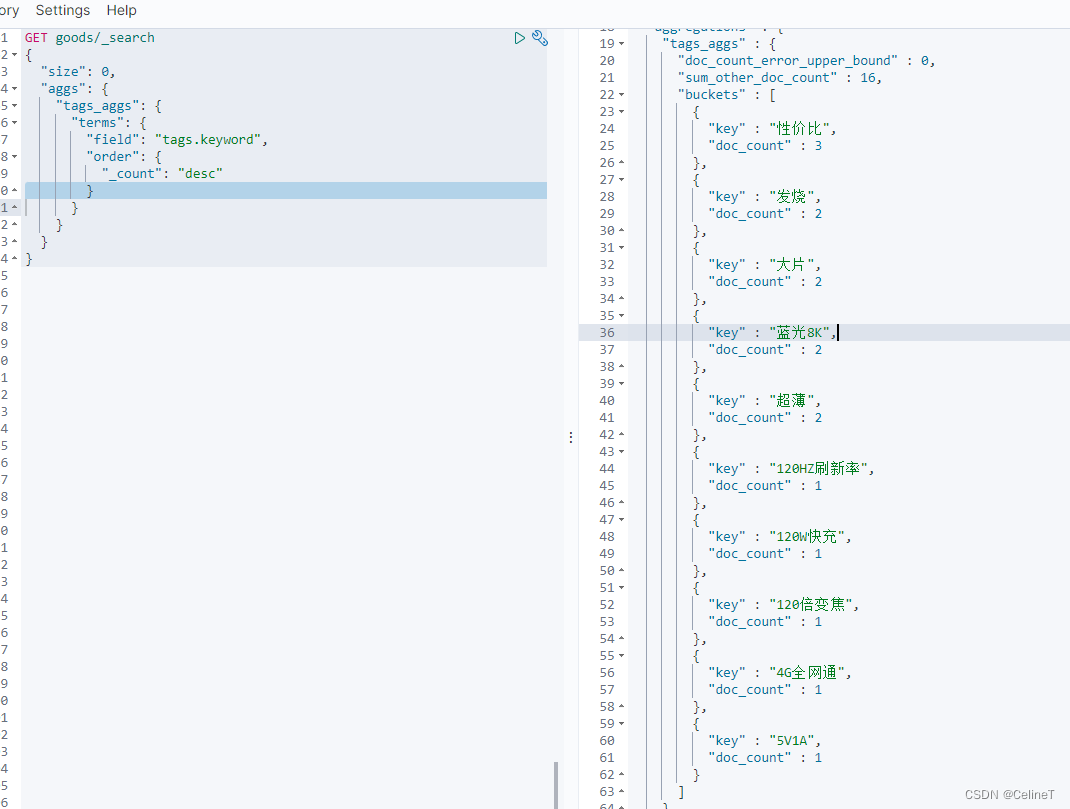
1. _count
按照doc_count排序
GET goods/_search
{
"size": 0,
"aggs": {
"tags_aggs": {
"terms": {
"field": "tags.keyword",
"order": {
"_count": "desc"
}
}
}
}
}
2._term/_key
_term已经淘汰,按照key字典序排序
GET goods/_search
{
"size": 0,
"aggs": {
"tags_aggs": {
"terms": {
"field": "tags.keyword",
"order": {
"_key": "asc"
}
}
}
}
}

3. 多层聚合
外层按照type的数量倒序排,里层按照lv的数量正序排
GET goods/_search
{
"size": 0,
"aggs": {
"type_aggs": {
"terms": {
"field": "type.keyword",
"order": {
"_count": "desc"
}
},
"aggs": {
"lv_aggs": {
"terms": {
"field": "lv.keyword",
"order": {
"_count": "asc"
}
}
}
}
}
}
}
根据price_stats中的最小值进行排序
# 根据price_stats中的最小值进行排序
GET goods/_search
{
"size": 0,
"aggs": {
"type_aggs": {
"terms": {
"field": "type.keyword",
"order": {
"filter_aggs>price_stats.min": "asc"
}
},
"aggs": {
"filter_aggs": {
"filter": {
"terms": {
"type.keyword": [
"耳机",
"手机",
"电视"
]
}
},
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
}
}
}
}
九、图形化
1. 根据价格range分桶
GET goods/_search
{
"size": 0,
"aggs": {
"price_range": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 1000
},
{
"from": 1000,
"to": 2000
},
{
"from": 2000,
"to": 3000
},
{
"from": 3000,
"to": 4000
},
{
"from": 4000,
"to": 5000
}
]
}
}
}
}
2. histogram(直方图、柱状图)
根据price,间隔1000,跟上面的基本相同
GET goods/_search
{
"size": 0,
"aggs": {
"price_range": {
"histogram": {
"field": "price",
"interval": 1000
}
}
}
}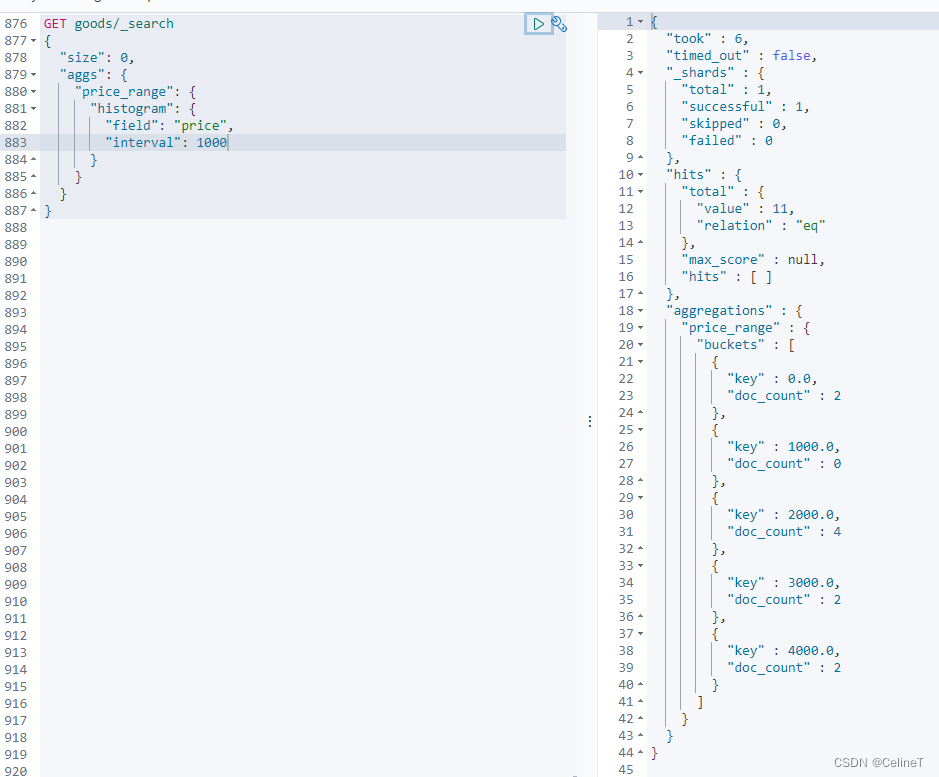
跟field、interval同级的其他参数
keyed:设置true,表示将结果输出为key、value形式
min_doc_count:设置成1,表示输出结果doc_value大于等于1的数据(过滤0)
missing:对空值赋默认值(设置成500,上图中表示,将price缺失的数据的price设置成500)
3. date-histogram
专门针对日期类型的直方图
根据月份进行分桶,可以用format进行指定格式输出
GET goods/_search
{
"size": 0,
"aggs": {
"date_range": {
"date_histogram": {
"field": "createtime",
"interval": "month"
}
}
}
}
可以设置extended_bounds,展示没有的数据0

4. auto_date_histogram
自动设置interval,根据buckets

5. cumulative_sum(累加聚合)
十、percentile (百分位统计、饼状图)
1. percentiles

2. percentile_ranks
















 1046
1046










 暂无认证
暂无认证














 到【灌水乐园】发言
到【灌水乐园】发言










m0_57815548: 你好,我也是这种情况,都试过了不行
jqncc: 前后端推荐用jwt??自己先搞清楚jwt适用场景吧,不要乱推荐了以免人子弟
林辰l: 有偿请教一些java问题
chen9707bin: 这个with-dependencies.jar包 还原pom 不是很容易 也不太好发现依赖哪些jar包
tanghuluweide_zhaji: 能否具体一二