GPU显存占满利用率GPU-util为0

吨吨不打野
 已于 2022-10-10 10:36:37 修改
已于 2022-10-10 10:36:37 修改
 阅读量3.4w
阅读量3.4w
 收藏
194
收藏
194
 点赞数
75
点赞数
75
已于 2022-10-10 10:36:37 修改
阅读量3.4w
收藏
194

 点赞数
75
点赞数
75
于 2021-09-10 20:22:04 首次发布

文章目录
- 1. 💢问题描述
- 2. 🥗原因分析
- 2.1 GPU内存占用率(memory usage)
- 2.2 GPU内存利用率(volatile GPU-Util)
- 2.3 torch.utils.data.dataloader
- 2.4 其他相关内容
- 3. 🍔好的实践经验
- 4. GPU加载数据非常慢
1. 💢问题描述
运行程序的时候提醒显存不够,查看了一下nvidia-smi,确实显存占满了,但是GPU-Util,gpu利用率有三个都是0,只有一个是56%
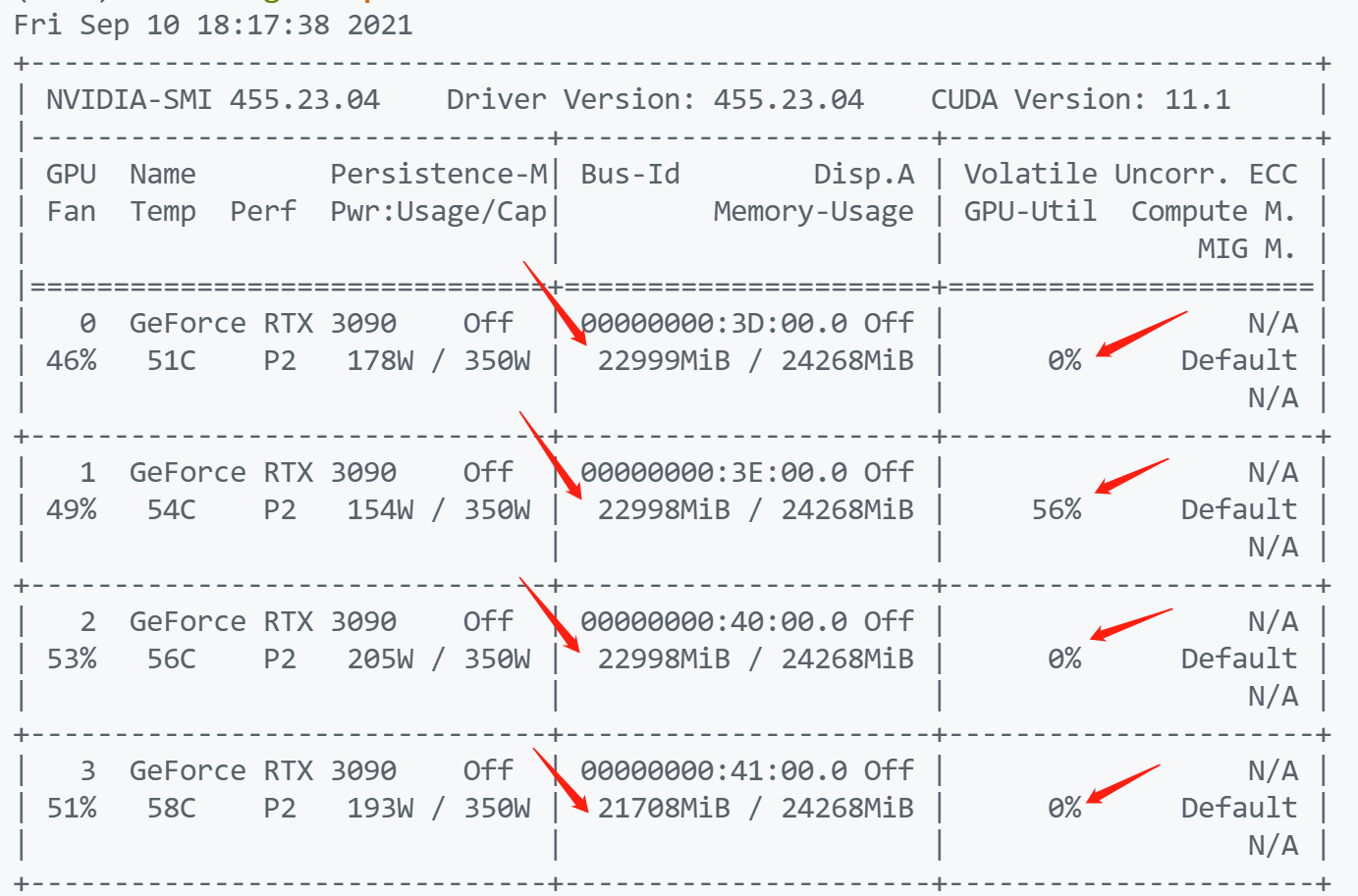
搜索后发现这个现象的原因还比较普遍,但是似乎没有几个可以很好解决这个问题,
参考:
- 脚本之家的文章: Pytorch GPU内存占用很高,但是利用率很低如何解决,
- 转载自CSDN博客: Pytorch GPU内存占用很高,但是利用率很低,
- ✅总结自CSDN博客: 深度学习PyTorch,TensorFlow中GPU利用率较低,CPU利用率很低,且模型训练速度很慢的问题总结与分析 这篇的点赞量评论数最多,以这个为主要。看了一下,确实很明晰,也举了例子。
2. 🥗原因分析
下面的2.1和2.2部分来自于
深度学习PyTorch,TensorFlow中GPU利用率较低,CPU利用率很低,且模型训练速度很慢的问题总结与分析
可以移步去原文!
2.1 GPU内存占用率(memory usage)
- GPU内存的占用率往往是由模型大小和batchsize决定的,如果发现GPU占用率很小,比如40%,70%等等。如果此时网络结构已经固定,则只需要改变batch size的大小,就可以尽量利用完整个GPU的内存。
- 对GPU内存占用率影响最大的还是模型大小,包括网络的宽度,深度,参数量,中间每一层的缓存,都会在内存中开辟空间来进行保存,模型本身会占用很大一部分内存。
- 其次是batch size的大小,也会占用影响内存占用率。batch size设置为128,与设置为256相比,内存占用率是接近于2倍关系。当你batch size设置为128,占用率为40%的话,设置为256时,此时模型的占用率约等于80%,偏差不大。所以在模型结构固定的情况下,尽量将batch size设置大,充分利用GPU的内存。
- GPU会很快的算完你给进去的数据,主要瓶颈在CPU的数据吞吐量上面。
2.2 GPU内存利用率(volatile GPU-Util)
volatile memory 易失性存储器
- 当没有设置好CPU的线程数时,这个参数是在反复的跳动的,0%,20%,70%,95%,0%。这样停息1-2 秒然后又重复起来。
- 其实是GPU在等待数据从CPU传输过来,当数据从总线传输到GPU之后,GPU逐渐计算起来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。
- 所以GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。
- 提高GPU利用率的方式:
- 硬件上(最好):更换好的四代或者更强大的内存条,配合更好的CPU。
- 软件上(以pytorch为例):
- PyTorch框架的数据加载
Dataloader类中包含了一些优化,包括num_workers(线程数)以及pin_memory,可以提升速度。解决数据传输的带宽瓶颈和GPU的运算效率低的问题。 - 在TensorFlow下也类似的设置。
详细来说
- 首先要将num_workers(线程数)设置合理,4,8,16是几个常选的几个参数。
测试发现将num_workers设置的非常大,例如,24,32,等,其效率也不一定会变高,因为模型需要将数据平均分配到几个子线程去进行预处理,分发等数据操作,设高了反而影响效率。
当然,线程数设置为1,是单个CPU来进行数据的预处理和传输给GPU,效率也会低。- 其次,当服务器或者电脑的内存较大,性能较好的时候,可以打开pin_memory,就省掉了将数据从CPU传入到缓存RAM里,再给传输到GPU上;为True,会直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
2.3 torch.utils.data.dataloader
官方文档: torch.utils.data.dataloader
确实有两个重要的参数:
num_workers (int, optional): how many subprocesses to use for data
loading. ``0`` means that the data will be loaded in the main process.
(default: ``0``)
collate_fn (callable, optional): merges a list of samples to form a
mini-batch of Tensor(s). Used when using batched loading from a
map-style dataset.
pin_memory (bool, optional): If ``True``, the data loader will copy Tensors
into CUDA pinned memory before returning them. If your data elements
are a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,
see the example below.
使用这个参数,可以将tensor拷贝到cuda的pinned memory,
关于pinned memory,可以参考文章:博客园 6.1 CUDA: pinned memory固定存储,是一种加速数据从cpu到gpu传输速度的方式。
- 使用pytorch时,训练集数据太多达到上千万张,Dataloader加载很慢怎么办? - 人民艺术家的回答 - 知乎
- pytorch内存泄露-dataloader
2.4 其他相关内容
https://www.zhihu.com/question/298616211

3. 🍔好的实践经验
在调试过程,
- 命令:
top实时查看CPU的进程利用率,这个参数对应你的num_workers的设置; - 命令:
watch -n 0.5 nvidia-smi每0.5秒刷新并显示显卡设置。实时查看你的GPU的使用情况,这是GPU的设置相关。 - 这两个配合好。包括batch_size的设置。
使用了watch -n 0.5 nvidia-smi这个命令之后,才确实可以看到,其实GPU是在运行的,只是变化很快。一直在变动。
4. GPU加载数据非常慢
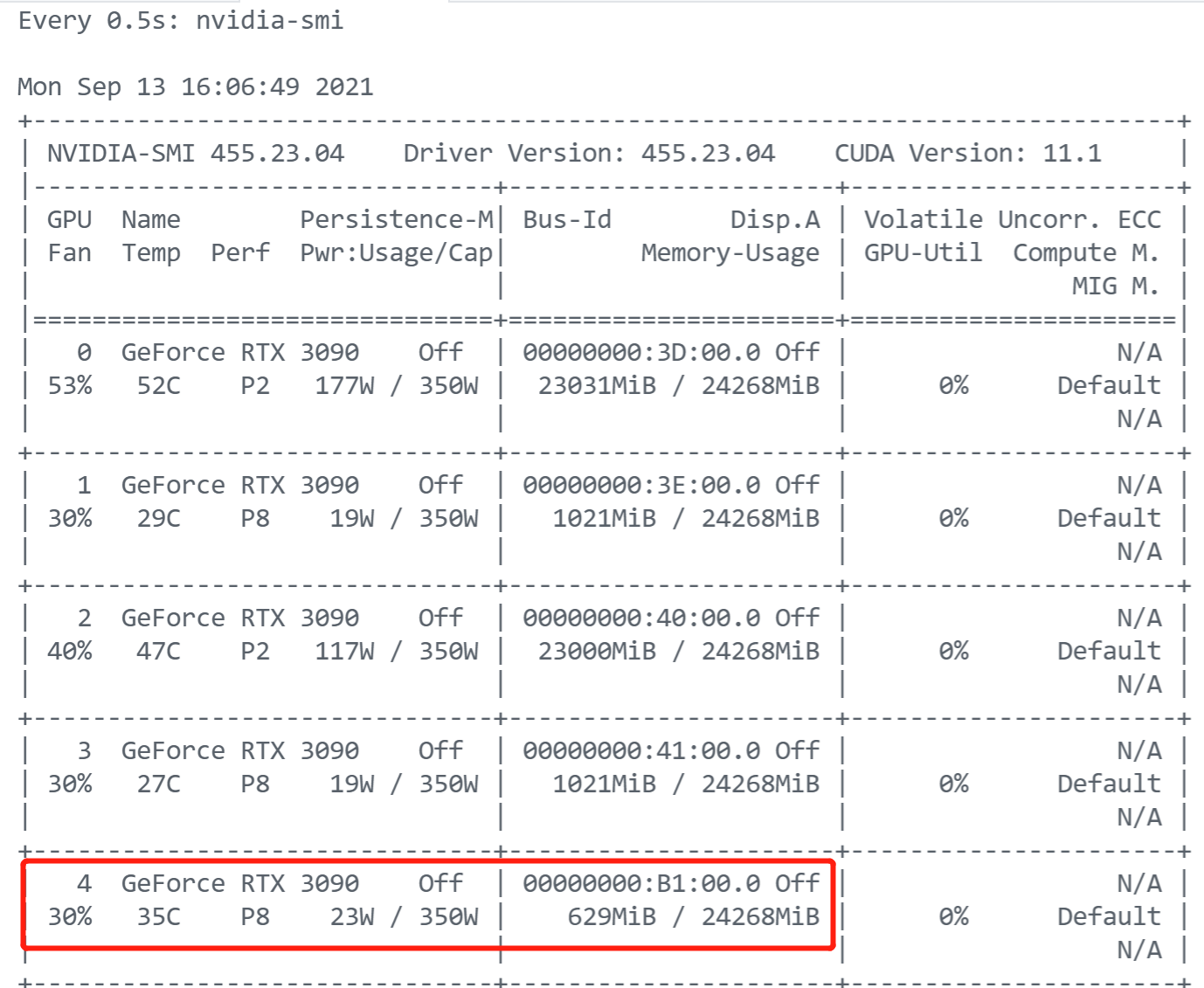
有一个公用服务器,多人使用,同时多块GPU,可以看到,其实前面0,2这两块GPU基本是满载的,1和3这两块也有人在使用,但是我所使用的4号GPU,加载速度非常慢,差不多3-5分钟才加载了600MB的内容。。。
所以考虑是CPU到GPU的数据传输问题导致的瓶颈,故去查看CPU信息:
lscpu
 结合top命令发现,CPU数量48个,但是top命令中cpu最多就是9.4,根本占不满。。所以应该不是硬件的问题,不是cpu和gpu之间数据传输导致的
结合top命令发现,CPU数量48个,但是top命令中cpu最多就是9.4,根本占不满。。所以应该不是硬件的问题,不是cpu和gpu之间数据传输导致的
参考: GPU导入模型非常缓慢的解决办法,大概可以感觉到,应该是cudann版本太老了的问题,
- 以前跑得很快,用的是
2.0.1-gpu-cuda11.0-cudnn8 - 现在虽然使用的是新版本的PaddlePaddle,但是由于服务器的cuda版本只有11.1,不满足11.2的要求,所以退而求其次,使用了
2.1.2-gpu-cuda10.2-cudnn7一个老的cudnn8的镜像,确实也是这次很慢。。。换!

















 7556
7556











 人工智能领域新星创作者
人工智能领域新星创作者





















































 到【灌水乐园】发言
到【灌水乐园】发言












天龙地龙小老虎: 嗯嗯,说不定哪天我会回来借鉴你的这个开发经验。
吨吨不打野: 可能吧,哈哈哈,不过很久不做这个了
天龙地龙小老虎: 你这个代码,可以变成RPA的底层工具。
waketzheng: ssh示例:pip install git+ssh://git@github.com/waketzheng/tomlkit.git@fix-326#egg=tomlkit
街角男孩: 没有用,关不了,老是沙CRAK文件